 1292
1292 
Содержание
Сегодня поговорим про построение конвейеров обработки данных (data pipeline) на примере совместного использования Apache Spark с Airflow и рассмотрим типовые проблемы этой комбинации. Читайте в нашей статье, как автоматизировать задачи пакетной и потоковой обработки больших данных (Big Data) с помощью гибкого REST-API Apache Livy, включая работу с Python-кодом, отказоустойчивость и безопасность.
Что не так с комбо Apache Spark и Airflow: смотрим на примере data pipeline
Представим достаточно простой data pipeline, когда необходимо обеспечить запуск Spark-задач по расписанию в рамках следующего ETL-процесса [1]:
- непрерывный поток приходит с видеокамер, датчиков и других IoT-устройств, данные пишутся в топики Apache Kafka;
- одно приложение Apache Spark обеспечивает извлечение данных (Extract) в эффективном для хранения и чтения Big Data столбцовом формате, например, Parquet, чтобы далее отправить их (Load) в историческое хранилище (архив) на базе Apache Hadoop или Amazon S3;
- другое Spark-приложение выполняет агрегацию событий с малой задержкой (Transform) и отправляет результаты в новые топики Kafka;
- еще одно Spark-приложение выполняет пакетные отчеты по данным из топиков Kafka, отображая их на дэшбордах BI-систем (Load) и, при необходимости, отправляя оперативные предупреждения (alerts).
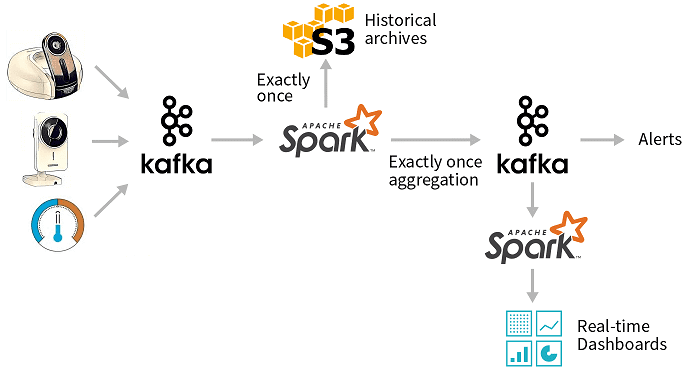
В этом несложном примере появляется сразу несколько Spark-задач, которые необходимо запускать по расписанию. С этим отлично справляется Apache Airflow – open-source набор библиотек для разработки, планирования и мониторинга рабочих процессов, написанный на Python. Он решает задачи автоматизации создания, запуска и мониторинга data pipeline’ов, представляя процесс извлечения-преобразования-загрузки данных в виде единого проекта на Python. При этом доступен как наглядный web-GUI, так и среда разработки на Python. Задачи конвейера данных, которые надо выполнить в строго определенной последовательности по определенному расписанию в рамках единой смысловой цепочки, называются DAG (Directed Acyclic Graph, направленный ациклический граф) [2]. Подобные возможности предоставляет оркестратор Dagster, еще более упрощая тестирование и отладку Spark-приложений, о чем мы рассказываем в новой статье.
Совместное использование Spark и Airflow ограничивается особенностями или недостатками последнего, которые мы упоминали здесь. В практическом смысле наиболее значимым из них является разделение по операторам, когда каждый оператор Airflow исполняется в своем python-интерпретаторе. Для каждой задачи создается свой файл с определением DAG, который не пересекается с другими и содержит собственный Spark Context – класс в Spark API, который является начальным этапом для создания Spark-приложения, а также может использоваться для создания общих структур данных (RDD, dataframe) и переменных. Это ограничение не позволяет запустить несколько операторов Airflow в едином Spark Context’е над общим пространством dataframe’ов. Обойти эту проблему можно с помощью Apache Livy – REST-API сервиса для взаимодействия с кластером Spark, о котором мы поговорим далее [3].
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
1 июня, 2026
Продолжительность
16 ак.часов
Стоимость обучения
51 200
Что такое Apache Livy: краткий обзор возможностей для Data Engineer’а
Apache Livy – это служба, которая обеспечивает простое взаимодействие с кластером Spark через интерфейс REST, включая отправку заданий или фрагментов кода Spark, синхронное или асинхронное получение результатов, а также управление контекстом. Помимо REST API для взаимодействия с Apache Spark сервис Livy позволяет работать с клиентской библиотеку удаленных вызовов RPC (Remote Procedure Call). Apache Livy также упрощает взаимодействие между Spark и серверами приложений, что позволяет использовать Спарк для интерактивных веб- и мобильных систем. Таким образом, Apache Livy обеспечивает следующие возможности [4]:
- совместная работа нескольких задач Spark от разных клиентов в рамках одного Spark Context’а;
- общее использование кэшированных RDD или Dataframes для нескольких заданий и клиентов;
- одновременное управление сразу несколькими контекстами Spark, в т.ч. их запуск в кластере Apache Hadoop YARN или Mesos вместо Livy Server для обеспечения высокой отказоустойчивости и параллелизма;
- отправка задач на исполнение по расписанию в виде предварительно скомпилированных jar-файлов, фрагментов кода или через клиентский API Java или Scala;
- безопасная аутентификация.
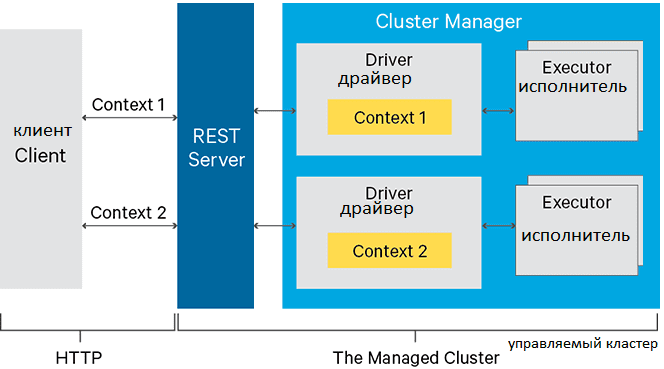
Возвращаясь к рассматриваемом примеру по data pipeline на базе Apache Spark и Kafka, отметим, что благодаря Livy можно вводить Python-код в программу, которую исполняет драйвер (driver), где запущена сессия Livy. Таким образом, обеспечивается гибкость работы с собственным кодом на Python в стиле Jupiter Notebook, что привычно каждому Data Scientist’у и удобно инженеру Big Data. Это позволяет в полной мере использовать Apache Airflow, автоматизируя создание и управление сложных конвейеров обработки данных в виде визуальных DAG-цепочек. Также появляется возможность оптимизировать созданный data pipeline, например, настраивая порядок преобразований так, чтобы Спарк смог максимально долго держать общие данные в памяти кластера. Поэтому, несмотря на «инкубаторский» статус в Apache Software Foundation, Livy активно используется в реальных Big Data проектах. В частности, компания «АльфаСтрахование» применяет этот полезный инструмент для инженерии больших данных с 2019 года [3]. Пример активного использования этого RESTful-интерфейса в фотохостинге Pinterest смотрите в нашей новой статье. А о проблеме распараллеливания вызовов REST API в Apache Spark без использования Livy читайте здесь.
Завтра мы продолжим разговор про эти инструменты Big Data, а технические подробности по администрированию и эксплуатации Apache Spark, Airflow и Livy для аналитики больших данных в проектах цифровизации своего бизнеса, а также государственных и муниципальных предприятий, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Построение эффективных конвейеров обработки данных с Apache Airflow и Arenadata Hadoop
- Анализ данных с Apache Spark
- Data Pipeline на Apache Airflow
Источники

