 668
668 
Содержание
С учетом тренда на контейнеризацию при разработке и развертывании любых технологий, в т.ч. Big Data, сегодня рассмотрим плюсы и минусы совместного использования Apache Spark с Kubernetes. Читайте далее, как отправить Спарк-задание в кластер Кубернетес и почему это сэкономит затраты на вашу инфраструктуру аналитики больших данных, не повысив производительность отдельных приложений, но увеличив скорость поставки в целом.
От писка моды к зрелости на рынке Big Data: Кубер как еще один менеджер ресурсов Спарк
Активный рост интереса к Kubernetes наблюдается с 2017 года [1], спустя 3 года после того, как сама платформа управления контейнерами была создана корпорацией Google для собственных нужд и приобрела статус open-source. В настоящее время Kubernetes (K8s) считается одной из главных DevOps-технологий, которая позволяет в лучших традициях Agile, многократно сократить весь цикл поставки программного продукта, от разработки и тестирования до развертывания в production. О преимуществах и недостатках запуска Apache Kafka на K8s мы уже рассказывали здесь. Продолжая обучение дата-инженеров и администраторов Big Data кластеров, сегодня разберем эту тему для Apache Spark.
Хотя этот распределенный фреймворк заботится о распараллеливании работ между узлами кластера самостоятельно, он не управляет имеющимися машинами, а полагается на помощь менеджера или планировщика вычислительных ресурсов. С 2018 года Kubernetes присоединился к компании кластер-менеджеров Spark, которую прежде составляли Standalone-диспетчер, Apache Mesos и Hadoop YARN. Поддерживаемый для версий Спарк от 2.3 и позднее, этот режим развертывания становится все более популярным и пользуется спросом у крупных Big Data компаний: Google, Palantir, Red Hat, Bloomberg, Lyft и пр. Однако, несмотря на активный спрос, эта технология еще считается новой [2], несмотря на то, что экспериментальный режим по Kubernetes-фичам в Apache Spark снят с версии 3.1.1, вышедшей в марте 2021 года [3]. Что нового и особенно полезного есть в этом релизе, мы разберем завтра, а пока ответим на актуальный до сих пор вопрос «Apache Spark на Kubernetes: за и против».
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
16 марта, 2026
Продолжительность
16 ак.часов
Стоимость обучения
48 000
Как Docker-контейнеры в К8s облегчают жизнь администратору кластера и разработчику Spark-приложений и что с ними не так
С практической точки зрения основными преимуществами развертывания Spark на K8s являются следующие [2]:
- контейнеризация приложений делает их более портативными, упрощая упаковку зависимостей и обеспечивая повторяемость всех рабочих процессов, от сборки и тестирования до развертывания в production. Это уменьшает общую нагрузку на DevOps-инженеров, ускоряя цикл разработки и поставки продуктов. В частности, пользователи платформы Data Mechanics, коммерциализирующей развертывание Spark на Kubernetes, отмечают 10-кратное увеличение скорости разработки. Дополнительным фактором такого роста эфективности рабочих процессов является легкое управление зависимостями и упрощение перехода с локального Python-кода на PySpark, об особенностях которого мы писали здесь. К примеру, можно создать новый Docker-образ для каждого приложения, упаковав туда нужные библиотеки, и динамически добавлять необходимый код поверх, вместо долгой и нестабильной инициализации с компиляцией C-компонентов при каждом запуске.
- эффективное совместное использование ресурсов с экономией затрат. В отличие от других кластер-менеджеров (YARN, Standalone, Mesos), при одновременном развертывании разных Spark-приложений в пределах одного кластер, Kubernetes автоматически решает проблемы с изоляцией зависимостей и проивзодительности. Без контейнеризации приложения с единой версией фреймворка и Python имеют общие библиотеки и среды, а также конкурируют за ресурсы, когда одно задание может замедлять выполнение других. Переходные кластеры для production-заданий на период их выполнения решают эту проблему, но увеличивают затраты. Например, на одну только настройку YARN может уйти до 10 минут, в течение которых невозможно совместное использование вычислительных ресурсов кластера. А Kubernetes может остановить контейнеры одного приложения и перераспределить ресурсы другому всего за 10 секунд, позволяя запускать все Спарк-приложения в одном кластере и предоставляя каждому заданию собственную версию фреймворка, Python и нужные зависимости в соответствующем Docker-образе. Клиенты Data Mechanics отмечают сокращение затрат на 50-75% по сравнению с другими платформами. Кроме того автоматическое масштабирование кластера позволяет фокусироваться на бизнес-задачах, не тратя время и силы на сложное администрирование Spark-кластера, управление очередями и компромиссами с несколькими арендаторами при развертывании YARN. Справедливости ради стоит отметить, что развертывание распределенных приложений в кластере Kubernetes не увеличивает их производительность по сравнению с другими менеджерами ресурсов, таких как Hadoop YARN и пр.
- независимость от облака и Cloud-провайдера. Развертывание Spark в Kubernetes бесплатно предоставляет использование пространств имен и квот для управления несколькими арендаторами, а также RBAC-управление доступом, включая интеграцию с IAM облачного провайдера, для надежной информационной безопасности и точного доступа к данным. А обилие инструментов с поддержкой Kubernetes позволяет повторно использовать существующую инфраструктуру.
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
16 марта, 2026
Продолжительность
32 ак.часов
Стоимость обучения
96 000
Обратной стороной всех этих достоинств являются следующие недостатки [2]:
- необходимость экспертного опыта и навыков работы с Kubernetes для корректной и эффективной настройки рабочего окружения и запуска приложений;
- зависимость от версий фреймворка – не ниже 2.3, а лучше – 2.4.
Чтобы пояснить все вышеперечисленные достоинства и недостатки развертывания Spark-приложений в кластере Kubernetes, далее мы рассмотрим их архитектуру и ключевые принципы работы.
Как устроен Spark на Kubernetes: архитектура и принципы работы
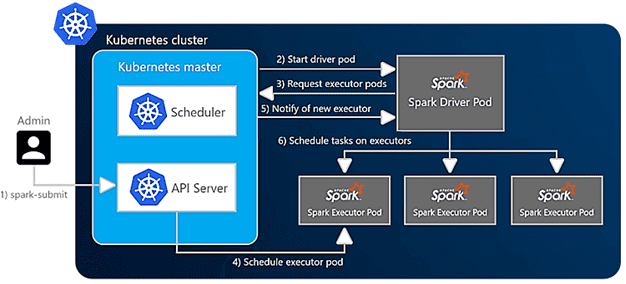
При запуске Spark-приложения в кластере K8s идет непосредственное обращение к серверу Kubernetes API на главном узле, который планирует под или контейнер для драйвера Spark. Как только драйвер Spark будет запущен, он будет напрямую связываться с Kubernetes, чтобы запросить исполнителей, распределенных по подам. При включенном динамическом распределении (dynamic allocation) количество исполнителей Spark динамически изменяется в зависимости от нагрузки. Есть два способа отправить Спарк-приложение в Kubernetes [4]:
- через spark-submit, который входит в состав фреймворка. Дальнейшие операции в приложении Spark должны будут напрямую взаимодействовать с объектами пода K8s.
- Spark-оператор, который был разработан Google Cloud Platform, но работает везде. В этом случае запуск одного пода в кластере превратит приложения Спарк в настраиваемые ресурсы Kubernetes, которые можно определять, настраивать и описывать, как другие объекты K8s. Также он поддерживает монтирование конфигураций (ConfigMaps) и томов (Volumes) непосредственно из конфигурации Спарк-приложения.
Независимо от способа отправки Spark-задания в K8s, этот запрос содержит полную конфигурацию приложения, включая код и зависимости для запуска, упакованные как Docker-образ или указанные через URI, параметры инфраструктуры (память, ЦП и объем хранилища для каждого исполнителя) и другие настроечные параметры.
Kubernetes принимает этот запрос и запускает драйвер Spark в Docker-контейнере пода. Затем драйвер Спарк может напрямую связываться с мастером — главным узлом кластера Kubernetes, чтобы запросить поды-исполнители, масштабируя их во время выполнения соразмерно нагрузке при динамическом распределении. Kubernetes сам заботится об упаковке подов на узлы кластера, т.е. физические виртуальные машины и динамически масштабирует их в соответствии с требованиями [3].
В следующий раз мы рассмотрим, как ускорить Спарк-приложения, развернутые в кластере K8s, и избежать ошибки OOM на подах.
Узнайте больше об аналитике больших данных с Apache Spark на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники
- https://trends.google.ru/trends/explore?date=2014-01-01%202021-03-18&geo=RU&q=Kubernetes
- https://spark.apache.org/releases/spark-release-3-1-1/
- https://www.datamechanics.co/blog-post/pros-and-cons-of-running-apache-spark-on-kubernetes
- https://www.datamechanics.co/blog-post/setting-up-managing-monitoring-spark-on-kubernetes

