 1271
1271 
Содержание
- Основы потоковой обработки Big Data в Apache Spark для начинающих: что такое Spark Streaming и Structured Streaming
- Apache Spark Structured Streaming vs Spark Streaming: 5 основных отличий
- Аналитика больших данных в режиме реального времени с Apache Spark: ожидания и реальность
- Еще раз об отличиях RDD, Dataset и Dataframe
- Когда это случилось: обработка времени события и опоздавших данных
- Сквозные гарантии
- Источники и приемники потоковых данных
- Apache Spark Structured Streaming или Spark Streaming: что и когда выбирать
В этой статье рассмотрим, что такое Apache Spark Structured Streaming и Spark Streaming, чем они отличаются и что общего между этими 2-мя способами обработки потоковых данных в самом популярном фреймворке аналитики больших данных. Читайте далее, как микро-пакетная передача приближается к режиму реального времени и при чем здесь структуры данных для распределенной обработки Big Data.
Основы потоковой обработки Big Data в Apache Spark для начинающих: что такое Spark Streaming и Structured Streaming
Apache Spark предоставляет 2 способа работы с потоковыми данными [1]:
- Spark Streaming – отдельная библиотека в Spark для обработки непрерывных потоковых данных. В его основе лежит дискретизированный поток DStream, который имеет API на базе главной структуры данных Spark – RDD (Resilient Distributed Dataset, надежная распределенная коллекция типа таблицы), которая является отказоустойчивой и может использоваться параллельно. DStreams предоставляют для обработки данные от источника потоковой передачи, разделив их на блоки, аналогично RDD. По завершение вычислений данные отправляются в пункт назначения. DStreams обеспечивает параллельный механизм восстановления, который повышает эффективность по сравнению с традиционными схемами репликации и резервного копирования, но допускает небольшое отставание в обработке потоковых данных [2].
- Structured Streaming (начиная с версии 2.0) – библиотека, реализующая модель потоковой передачи на базе модуля Spark SQL, а точнее, API ее основных структур данных – Dataframe и Dataset, используемых в Java, Scala, Python и R. С помощью этой библиотеки можно применить любой SQL-запрос через DataFrame API или операции Scala через DataSet API для потоковой передачи данных. Этот масштабируемый и отказоустойчивый механизм потоковой обработки Big Data представляет собой улучшенный способ обработки непрерывной потоковой передачи больших данных без проблем с обработкой ошибок и сбоев. Движок Spark SQL заботится о том, чтобы поток данных обрабатывался постепенно и непрерывно, а конечный результат обновлялся по мере поступления новых потоковых данных [2].
Таким образом, Structured Streaming и Spark Streaming оба предназначены для работы с потоками Big Data в Apache Spark, однако, при общем целевом назначении, они отличаются некоторыми особенностями реализации, о которых мы поговорим далее.
Apache Spark Structured Streaming vs Spark Streaming: 5 основных отличий
Чтобы понять, в чем разница между 2-мя вышеназванными способами обработки потоковых данных в Спарк, сравним их по следующим критериям [1]:
- режим реального времени, когда данные ничем не ограничены, приходят непрерывно и обрабатываются сразу по мере поступления;
- используемые структуры данных, через которые идет обработка потоков. О том, что такое RDD, Dataset и Dataframe в Спарк и чем они отличаются друг от друга, мы писали здесь.
- Обработка времени события и опоздавших данных. Время события — это время, когда событие действительно произошло. Примечательно, что источник потоковой передачи не обязательно должен подтверждать данные в реальном времени. Кроме того, возможны в генерации данных и их передаче механизму обработки.
- Сквозные гарантии доставки данных и отказоустойчивости Spark-приложений, чтобы иметь возможность перезапускать их с той же точки, где произошел сбой, во избежание потери и дублирования информации.
- разнообразие источников и приемников данных, а также гибкость манипуляций с ними.
Аналитика больших данных в режиме реального времени с Apache Spark: ожидания и реальность
В Spark Streaming концепция real-time обработки реализована не полностью: библиотека работает с микро-пакетами (micro-batch) RDD. Spark опрашивает источник с периодичностью, заданной длительностью пакета в конкретном приложении, а затем создает пакет из полученных данных. Таким образом, каждая входящая запись принадлежит пакету DStream.
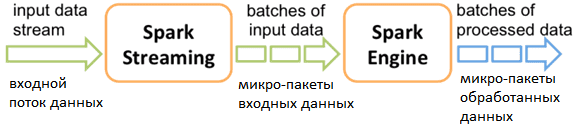
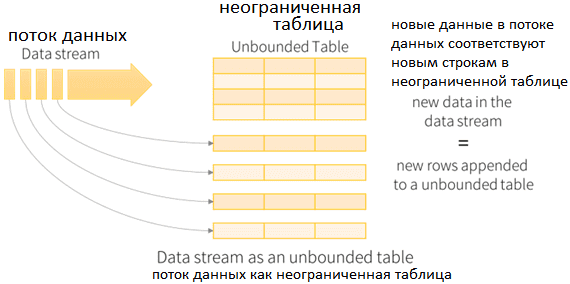
Structured Streaming работает по той же архитектуре периодического опроса данных по истечении некоторого времени в зависимости от интервала запуска, однако, она больше приближена к реальной потоковой передаче. В Spark Structured Streaming нет концепции микро-пакетов. Полученные данные добавляются к непрерывно текущему потоку данных. Каждая строка потока данных обрабатывается, и результат обновляется в неограниченной выходной таблице. Вид представления результата (обновление имеющихся данных, только новые или все результаты), зависит от режима операций: Complete, Update, Append.
Еще раз об отличиях RDD, Dataset и Dataframe
Для выполнения потоковых операций Spark Streaming работает с DStream API, который использует RDD, а Structured Streaming – со API DataFrame и Dataset. Не вдаваясь во все подробности отличия этих структур данных Спарк друг от друга, отметим, что DataFrame более оптимизирован с точки зрения обработки и предоставляет больше возможностей для агрегирования и других операций [1]. Конструкция RDD представляет собой распределенный набор элементов данных, однако, библиотека RDD непрозрачна и сложна для понимания. Предоставляя разработчику больше контроля, RDD API не оптимизирует цепочку преобразования данных, что приводит к увеличению временных задержек, особенно при обработке ошибочных и медленных данных. В свою очередь, DataFrame – это распределенный набор данных, организованных в именованные столбцы. Концептуально это похоже на таблицу реляционной СУБД, но с более широкими возможностями. Таким образом, API DataFrame обеспечивает более высокий уровень абстракции, позволяя пользователям манипулировать данными, когда они перемещаются по конвейеру обработки данных. В частности, здесь поддерживаются все этапы оптимизации запросов Spark SQL, включают три типа логических планов и один физический план. Поэтому можно сказать, что Spark Structured Streaming оперирует более эффективными структурами данных [2].
Когда это случилось: обработка времени события и опоздавших данных
В Spark Streaming нет опции обработки данных с использованием времени события. Он работает только с меткой времени (timestamp), когда данные получены Спарк. На основе метки времени приема данных Spark Streaming помещает их в микро-пакет, даже если событие было создано раньше и принадлежало более раннему пакету. Это может привести к потере данных или уменьшению точности. С другой стороны, Structured Streaming предоставляет функциональные возможности для обработки данных на основе времени события, когда его timestamp уже входит в полученную информацию. Таким образом, реализуется возможность обработки потоковых данных в зависимости от времени происхождения событий в реальном мире, что повышает точность. Также это позволяет обрабатывать данные, поступающие с опозданием.
Сквозные гарантии
Для обеспечения отказоустойчивости Spark Streaming, и Structured Streaming используют механизм контрольных точек (checkpoints) для сохранения хода выполнения задания, о котором мы рассказывали здесь и здесь. Кроме checkpoint’ов, для обеспечения строго однократной семантики доставки сообщений (exactly once), Structured Streaming применяет два условия для восстановления после любой ошибки [1]:
- источник данных должен быть воспроизводимым;
- потребители данных должны поддерживать идемпотентные операции для поддержки повторной обработки в случае сбоев.
Это позволяет Apache Spark Structured Streaming обеспечивать высокую надежность и отказоустойчивость распределенных приложений.
Источники и приемники потоковых данных
В Spark Streaming нет ограничений на тип приемника данных благодаря методу foreachRDD() для выполнения действий с потоком. Он поочередно возвращает RDD, созданные каждым микро-пакетом, позволяя выполнять над ними любые действия, например, вычисления или сохранение в хранилище. Для выполнения с одним RDD набора операций и отправления в несколько приемников, его можно кэшировать.
Structured Streaming до версии Спарк 2.3 поддерживал ограниченное количество выходных приемников, причем с одним приемником могла быть выполнена только одна операция. Также отсутствовала возможность сохранять выходные данные в нескольких внешних хранилищах. Чтобы использовать настраиваемый приемник, пользователю необходимо было реализовать метод ForeachWriter(). В релизе Спарк 2.4 появился новый приемник – foreachBatch, который дает результирующую выходную таблицу в виде DataFrame, позволяя использовать его для настраиваемых операций. Такое решение сделало Apache Spark Structured Streaming более гибкой и дало преимущество перед Spark Streaming [1].
Apache Spark Structured Streaming или Spark Streaming: что и когда выбирать
Подводя итог сравнению Structured Streaming и Spark Streaming, отметим, что первая библиотека больше ориентирована на потоковую обработку больших данных в реальном времени, а вторая – на пакетную. API-интерфейсы оптимизированы в структурированной потоковой передаче, тогда как Spark Streaming по-прежнему основан на старых добрых RDD. Structured Streaming с использованием DataFrames является улучшением DStreams в исходной модели Apache Spark Streaming. При том, что потоки DStream состоят из отказоустойчивой конструкции RDD, разделение потоковых данных на последовательные блоки RDD происходит медленнее, чем структура данных DataFrame в структурированной потоковой передаче. Поэтому потоковая обработка и анализ больших данных в Spark Streaming происходит медленнее, что увеличивает задержку и снижает надежность доставки сообщений.
Таким образом, можно сказать, что Structured Streaming предоставляет разработчикам с опытом реализации распределенных Big Data систем быстроту вычислений и гибкость API-интерфейсов. Пример практического использования этой библиотеки в ретаргетинговых компаниях и потоковой аналитики больших данных о пользовательском поведении читайте в нашей новой статье. Однако, при выборе Apache Spark Structured Streaming стоит помнить о некоторых ограничениях этого решения [2]:
- чтобы настроить ETL-конвейер с оптимальной производительностью и писать соответствующий программный код, разработчик должен понимать сложные концепции Спарк;
- небольшое количество предлагаемых коннекторов предполагает самостоятельную разработку и поддержку коннекторов к различным источникам и приёмникам данных. Впрочем, появившиеся в Спарк 2.4 новые методы предоставляют такую возможность, о чем мы уже упомянули.
- масштабирование Спарк-приложений в облаке требует комплексного управления и добавления уровня оркестрации. Этим непросто оперировать из-за сложности механизма контрольных точек, разбиения на разделы, перетасовки и частичного переноса данных на отдельные узлы кластера.
Как все эти отличия отражаются на практике, мы рассматриваем здесь на примере записи данных в СУБД PostgreSQL с использованием Спарк-приложения.
Освоить весь инструментарий фреймворка Apache Spark для разработки распределенных приложений и потоковой аналитики больших данных вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Потоковая обработка в Apache Spark
- Core Spark – Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
Источники
- https://dzone.com/articles/spark-streaming-vs-structured-streaming
- https://www.upsolver.com/blog/apache-spark-and-spark-structured-streaming-compared

