 579
579 
Содержание
Продолжая недавний разговор про потоковую передачу событий и соответствующие Big Data инструменты, сегодня рассмотрим не отдельные фреймворки обработки данных в режиме реального времени, а комплексные платформы, которые объединяют сразу несколько технологий для интерактивной аналитики больших данных. Вас ждет краткий обзор Cloudera Streaming Analytics, Materialize и Rockset: что это такое, как они связаны с Apache Kafka, Flink и Spark, а также при чем здесь SQL с BI.
3 SQL-платформы потоковой аналитики больших данных
Оставив за рамками этой статьи узко специализированные инструменты, которые решают только одну задачу, например, только хранение данных или их обработка, разберем более обширные решения, которые охватывают сразу несколько целей. С учетом глобального тренда на интеграцию отдельных систем и технологий, знание современных платформ потоковой обработки пригодится для любого практикующего дата-инженера. Итак, далее рассмотрим следующие платформы интерактивной аналитики больших данных, которые используют механизм SQL-запросов в качестве средства обращения к ним:
- Cloudera Streaming Analytics;
- Materialize;
- Rockset.
Помимо того, что все они используют SQL для доступа к данным, они также принимают данные из потоковых источников, например, Apache Kafka, и обрабатывают их в режиме реального времени, чтобы затем отправить в систему-приемник. В качестве принимающей стороны может выступать как ПО промежуточного уровня, т.е. та же самая Kafka, так и СУБД прикладных систем, корпоративные хранилища данных и даже дэшборды BI-приложений. Что именно предлагают Cloudera Streaming Analytics, Materialize и Rockset своим пользователям, т.е. дата-инженерам, мы рассмотрим далее.
Cloudera Streaming Analytics: потоковая передача c Apache Flink
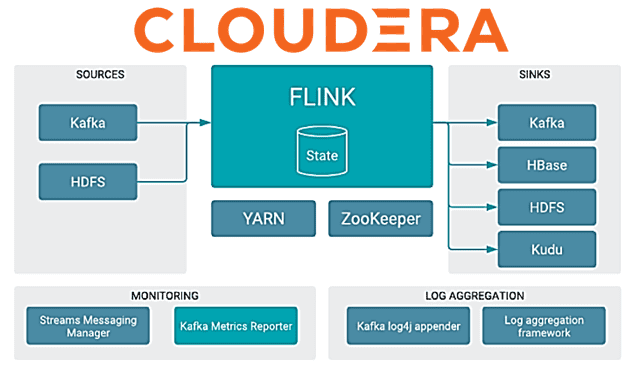
Cloudera Streaming Analytics основана на базе фреймворке Apache Flink и представляет собой платформу потоковой аналитики и обработки больших наборов данных в реальном времени. Благодаря тесной интеграции с Apache Kafka, Cloudera Streaming Analytics включает средства мониторинга и ведения логов: реестр схем (Schema Registry), менеджер потоковых сообщений (Streams Messaging Manager) и отчеты метрик Kafka (Metrics Reporter). А наличие коннекторов ко многим компонентам экосистемы Apache Hadoop (HBase, HDFS и Kudu) позволяет передавать в них результаты вычислений.
Поскольку Flink имеет обязательные зависимости с компонентами экосистемы Apache Hadoop (HDFS, YARN и Zookeeper), это следует учитывать при настройке хостов. В частности, следует назначить хосту роли Flink Gateway и HistoryServer на основе обязательных зависимостей. В Cloudera Streaming Analytics задания Flink выполняются как приложения YARN. Распределенная файловая система HDFS используется для хранения данных восстановления и логов, а сервис синхронизации метаданных ZooKeeper отвечает за координацию высокой доступности заданий.
На практике Flink Gateway часто совмещен со шлюзами YARN и HDFS, а Flink HistoryServer – с ролью HDFS или шлюзом. Для создания заданий потоковой обработки с отслеживанием состояния средствами SQL-запросов Cloudera Streaming Analytics предоставляет комплексный интерфейс – SQL Stream Builder. Он позволяет просто объявлять выражения, которые фильтруют, объединяют, маршрутизируют и обогащают потоки данных в интерактивном режиме. Выполненные SQL-запросы выполняются как задания в кластере Flink, оперируя неограниченными потоками данных до тех пор, пока они не будут отменены. Так можно создавать, запускать и отслеживать задания потоковой обработки в SSB, поскольку каждый SQL-запрос является заданием Flink. Пример того, как это работает на практике мы рассматривали здесь.
SQL-платформа Materialize
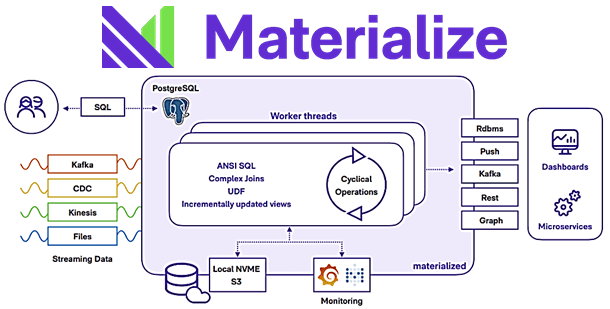
Materialize — это SQL-платформа для обработки потоковых данных, написанная на Rust и запущенная в 2019 году. Она основана на Timely Dataflow и Differential Dataflow, двух системах, созданных в 2013 году и активно используемыми многими компаниями. Они воплощают вычислительную модель циклического потока данных с малой задержкой. А Materialize использует SQL в качестве основного интерфейса доступа к потоковым данным. Платформа реализует постепенно обновляемые материализованные представления, чтобы предоставлять аналитические данные в реальном времени с сохранением актуального исторического контекста.
Materialize разработан как многопоточная платформа параллельных вычислений, которая при необходимости объединяет операции с малой задержкой в более важные реактивные вычисления, чтобы обеспечить высокую производительность и корректность интенсивной обработки данных.
Materialize подключается ко многим источникам и выходных входных данных: Kafka, реляционные СУБД, файловые системы, облачные объектные хранилища типа AWS S3. А благодаря полной совместимости с PostgreSQL, возможна интеграция со многими приложениями и СУБД через ODBC/JDBC. Наконец, еще одним значимым преимуществом является возможность визуализации данных как средствами внешних BI-систем, так и встроенными механизмами самой платформы.
RocksDB и Rockset
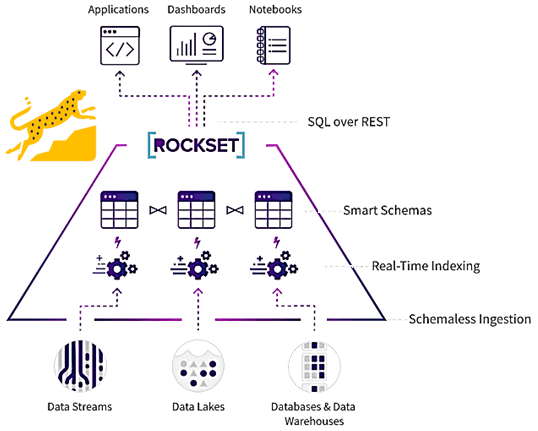
Поскольку потоковая передача событий все же неотделима от Apache Kafka и Flink, неудивительно, что некоторые компоненты этих фреймворков встречаются и в независимых решениях. Например, RocksDB – адаптируемое, встраиваемое и постоянное key-value хранилище, которое используют приложения Kafka Streams и Flink для хранения состояний. Об этом мы писали здесь и здесь. Также на базе RocksDB основана целая аналитическая платформа Rockset, которая обеспечивает поиск, агрегацию и соединение массивных полуструктурированных данных в режиме реального времени без дополнительной нагрузки. Rockset автоматически индексирует структурированные, полуструктурированные, географические и временные данные для поиска в реальном времени и масштабной аналитики.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
15 декабря, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
RocksDB как высокопроизводительный механизм хранения поддерживает непрерывный прием данных с задержкой записи менее секунды и запрашивает их за 10 миллисекунд, обеспечивая быструю запись по сети и оперативное чтение. Многие проекты (MongoRocks, Rocksandra, MyRocks и пр.) применяют RocksDB в качестве механизма хранения для баз данных, чтобы сократить потребление дискового пространства и задержку записи. А модель «ключ-значение» RocksDB отлично подходит для реализации конвергентной индексации, когда каждое поле во входном документе хранится в строковом или столбцовом хранилище и поисковом индексе.
На практике Rockset часто используется в качестве уровня скорости, который индексирует данные из OLTP-системы, такой как MongoDB или DynamoDB, а также потоковых фреймворков (Apache Kafka, Amazon Kinesis) и даже озер данных, например, AWS S3. Rockset действует как внешний вторичный индекс, ускоряя аналитические запросы и обеспечивая изоляцию производительности для первичных транзакционных систем, храня данные в документной модели данных. Но Rockset отличается от типичных документно-ориентированных NoSQL-СУБД тем, что индексирует и хранит данные для поддержки реляционных SQL-запросов.
Rockset имеет встроенную интеграцию со множеством источников данных: Amazon DynamoDB, Kinesis, S3, Apache Kafka, Google Cloud Storage, MongoDB, Atlas, другие СУБД и файловые хранилища. После подключения Rockset автоматически загрузит данные в течение нескольких секунд, и можно сразу же приступить к выполнению SQL-запросов. Сами данные могут быть в разных форматах: JSON, XML, CSV, Apache Parquet и пр.
Rockset имеет динамическую сплошную типизацию, когда тип данных связан со значением поля в каждом столбце, а не целиком. Благодаря облачной архитектуре Rockset является очень гибким. Традиционные СУБД, созданные для дата-центров, предполагают фиксированный объем аппаратных ресурсов независимо от нагрузки. А облачная архитектура Rockset позволяет динамически масштабировать систему для эффективной утилизации доступных ресурсов. Еще преимуществами Rockset являются использование общего иерархического хранилища с разделением доступа, а также средства планирования ресурсов для управления спросом и предложением.
Rockset подключается к Apache Kafka для непрерывного приема потоков событий, предоставляя полнофункциональный SQL для фильтрации, агрегирования и объединения с другими наборами данных. Это позволяют пользователям легко создавать API-интерфейсы в реальном времени и интерактивные дэшборды, используя типовые BI-инструменты для потоковых данных. Развертывание SQL поверх REST-интерфейса, Rockset позволяет отправлять результаты вычислений сразу в приложения-приемники или дэшборды BI-систем. Эти плюсы бессерверного стека уже оценили дата-инженеры BOSH, Sequoia Capital, Delloite и множество других компаний, включая маркетплейс публичных аукционов Whatnot, о котором мы рассказываем здесь. А чем Rockset отличается от ksqlDB и что выбирать для аналитики больших данных в реальном времени, читайте в нашей новой статье.
Читайте в нашей новой статье обзор платформ для построения самообслуживаемых конвейеров потоковой передачи событий: DataCater и Flow на базе Apache Kafka и Gazette.
А всю практику разработки и эксплуатации распределенных приложений потоковой аналитики больших данных с Apache Kafka и Spark Streaming вы освоите на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

