 665
665 
Содержание
Недавно мы уже рассматривали выполнение Join-операций в Apache Spark SQL. Сегодня поговорим про особенности потокового соединения в модуле Structured Streaming этого популярного фреймворка аналитики больших данных. Читайте далее, в чем специфика внешних и внутренних соединений потоков Big Data в Apache Spark Structured Streaming, а также как и зачем Inner/Outer Join используют водяные знаки (watermark).
Соединение потоков в Apache Spark Structured Streaming
Соединение (Join) считается достаточно сложной операцией в SQL. А соединение потоков данных усложняется задержками поступления информаций. Для ограниченного источника данных, такого, как статичная СУБД, все данные для соединения имеются в наличии, тогда как в случае потокового источника данные непрерывно перемещаются, причем с непостоянной скоростью. Это может быть связано с техническими причинами, такими как проблемы с конвейером приема, или из-за функциональных требований, когда связанные события не всегда генерируются в течение аналогичного периода времени. К примеру, процесс заказа в интернет-магазине, который обычно длится долго. Поэтому операция соединения должна управлять набором связанных, но асинхронных событий.
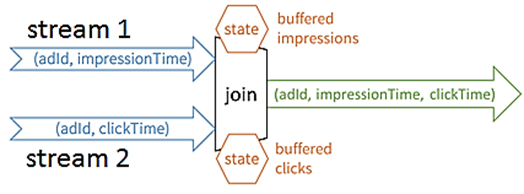
Кроме того, при соединении потоков необходимо обеспечить управление состоянием, т.к. данные для конкретного события могут поступить в любой момент (рано или поздно), а количество места, зарезервированного для их хранения, ограничено. Поэтому следует понимать, что делать с накопленным состоянием и когда его можно сбросить, что соответствует моменту, в который не ожидается получение какого-либо нового события для данного ключа соединения.
Начиная с версии Apache Spark 2.3.0, библиотека Structured Streaming решает обе эти проблемы, позволяя соединять 2 или более потоков следующим образом [1]:
- семантика соединения потоков аналогична работе с пакетами;
- вывод генерируется, как только будет найден соответствующий элемент при внутреннем соединении (Inner Join);
- водяной знак (watermark) и запрос временного диапазона используются для соединения поздних данных и принятия решения о сбросе состояния, когда более не ожидается событий для данного ключа;
- поддерживаются разные типы соединения: внутреннее и внешнее (Outer Join);
- соединения могут быть каскадными, т.е. применяться более чем к 2 потокам данных.
Join-операции и watermark: особенности потоковой обработки Big Data
В случае внутреннего соединения Apache Spark Structured Streaming, результатом которого являются только совпавшие по условию объединенные записи из входных наборов данных, строка без соответствия не генерируется. Поэтому не требуется никаких временных ограничений для соединенных столбцов. Однако, каждая потенциально присоединяемая строка буферизуется в хранилище состояний. Соединение и выдача результата выполняются каждый раз, когда найдена соответствующая строка. При этом строки, даже без совпадений, могут оставаться в хранилище состояний в течение очень долгого времени. Поэтому рекомендуется иметь условие, указывающее, как долго должно сохраняться состояние конкретного ключа. Для этого Apache Spark Structured Streaming использует механизм водяных знаков – watermark [2], о котором мы рассказывали здесь.
Можно рассматривать водяной знак как отметку, которая «дискретизирует» поток данных по аналогии с переводом сигнала из аналоговой формы в цифровую.
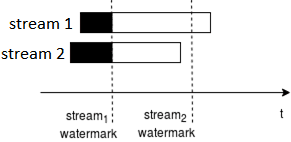
Отслеживание водяных знаков актуально и для внешних соединений. Outer Join дает все строки с одной стороны, даже если некоторые из них не имеют совпадений в соединяемом наборе данных. Для ограниченных источников данных, таких как СУБД, такие несоответствия возвращаются напрямую с нулевым значением, представляющим строку на другой стороне. Однако, в случае неограниченных источников, т.е. потоков данных, нужно учитывать влияние задержки сети или временное выпадение из онлайн устройства, генерирующего события. Из-за таких ситуаций в какой-то момент времени не все соединяемые данные могут быть в наличии. Поэтому следует иметь возможность отложить физическое соединение до того момента, когда придет большая часть строк для Join-операции. Для этого требуется где-то сохранить строки с одной стороны [3].
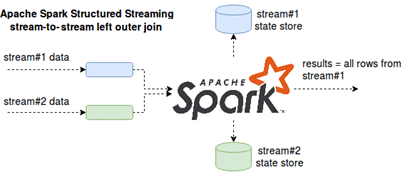
Как и в случае внутреннего соединения с водяным знаком, при Outer Join строки буферизуются в хранилище состояний. И внешнее соединение также использует идею водяных знаков и условий запроса диапазона, чтобы решить, когда данная строка не должна получать никаких новых совпадений во втором потоке. Поэтому внешнее соединение без водяного знака просто невозможно. Интересно, что результаты соединения обусловлены сопоставлением: совпавшие строки возвращаются, как только это возможно, а несоответствующие – только по достижении времени водяного знака [3].
2 стратегии управления водяными знаками в Apache Spark
Таким образом, без концепции «просроченного состояния» сохранение соответствия строк будет длиться неограниченно долго, а, поскольку источник данных неограничен, рано или поздно он неизбежно выйдет из строя (закончится место). Поэтому Apache Spark предоставляет 2 различных стратегии для управления истечением срока действия (водяным знаком):
- ключ состояния, которая применяется к запросу, когда столбец watermark’а определен по крайней мере в одном из соединяемых потоков, например, столбец с отметкой времени (timestamp) или столбец временного окна (window). Если водяной знак определен только для одной стороны, Apache Spark может определить его и для другой. Также эта стратегия применяется, если имеется определение условия диапазона для столбца водяного знака в условии JOIN, который должен соединяться иначе, чем при равенстве значений. Название этой стратегии «ключ состояния» происходит от использования водяного знака непосредственно в условии JOIN.
- значения состояния, когда условие JOIN не содержит равенства в поле водяного знака, а указывает на диапазон, выраженный как неравенство. Таким образом, название этой стратегии — водяной знак со значением состояния. Условие диапазона, определенное в условии JOIN, автоматически влияет на водяной знак одной из соединенных сторон. Когда это условие выражается как leftTimeWatermark> rightTimeWatermark + 10 минут, это означает, что левая сторона будет принимать только события, произошедшие позже, чем водяной знак правой стороны + 10 минут. При этом, если водяной знак правой стороны равен 10:00, то водяной знак левой стороны автоматически становится 10:10. Это работает и наоборот, то есть левый водяной знак влияет на правый. Такая стратегия также будет работать, если определены 2 разных значения водяных знаков с обеих сторон. Apache Spark Structured Streaming будет использовать одно общее значение водяного знака, минимальное для соединяемых потоков. Наличие двух разных watermark’ов не будет работать в случае водяного знака с ключом состояния, т.к. потоки соединяются по равенству водяных знаков. Водяной знак состояния также может применяться к кейсам с временными окнами, но, как и в случае столбцов с отметками времени, он должен быть выражен как неравенство в условии JOIN.
Также возможно совместное использование этих 2-х стратегий, однако движок Apache Spark Structured отдает предпочтение водяному знаку с ключом состояния из-за его более строгого характера. Это довольно четко показано в методе getOneSideStateWatermarkPredicate (oneSideInputAttributes: Seq [Attribute], oneSideJoinKeys: Seq [Expression], otherSideInputAttributes: Seq [Attribute]), который находит, какие атрибуты использовались для определения атрибута водяного знака и создает JoinStateWatermarkPredicate — абстракцию предикатов водяных знаков состояния соединения, описываемых выражением SQL-оптимизатора Catalyst, следующим образом [4]:
- JoinStateKeyWatermarkPredicate, если водяной знак был определен для ключа соединения с выражением водяного знака для индекса выражения ключа соединения;
- JoinStateValueWatermarkPredicate, если водяной знак был определен среди атрибутов oneSideInputAttributes (с водяным знаком значения состояния на основе заданных атрибутов oneSideInputAttributes и otherSideInputAttributes).
Таким образом, все стратегии управления «сроком годности» соединяемых потоков в Apache Spar Streaming используют концепцию водяного знака, чтобы обнаруживать опоздавшие строки, которые будут отброшены в следующем цикле обработки [2].
Узнайте больше про особенности Apache Spark Structured Streaming для аналитики больших данных и разработки распределенных приложений на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Core Spark – Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
Источники
- https://www.waitingforcode.com/apache-spark-structured-streaming/inner-joins-streams-apache-spark-structured-streaming/read
- https://www.waitingforcode.com/apache-spark-structured-streaming/stream-to-stream-state-management/read
- https://www.waitingforcode.com/apache-spark-structured-streaming/outer-joins-apache-spark-structured-streaming/read
- https://jaceklaskowski.gitbooks.io/spark-structured-streaming/content/spark-sql-streaming-StreamingSymmetricHashJoinHelper/

