 1332
1332 
Сегодня рассмотрим инструмент, который облегчает практическое использование Apache Spark, позволяя дата-аналитику и разработчику распределенных приложений быстро писать и выполнять SQL-запросы в рамках удобного веб-редактора. Читайте далее, что такое Hue, как он связан со Spark SQL и Hive, а также причем здесь Livy.
Что Hue и при чем здесь Apache Livy
HUE (Hadoop User Experience) – это веб-интерфейс экосистемы Hadoop для анализа данных. Этот open-source продукт распространяется под лицензией Apache 2.0, но принадлежит компании Cloudera [1]. Примечательно, что популярный REST API Apache Livy, который предоставляет облегченное представление интерактивных и пакетных выражений PySpark, Scala и SQL во фреймворке Спарк, изначально был создан в рамках проекта Hue [2]. Подробнее о том, что такое Apache Livy, зачем он нужен и как работает со Спарк, мы писали здесь и здесь.
Как часть экосистемы Hadoop, Hue совместим со всеми дистрибутивами этой платформы, Hortonworks, MAPR, HDInsight и пр. HUE включает целый набор приложений ко всем модулям Big Data кластера, в т.ч. платформу разработки, файловый браузер и планировщик задач Spark, Pig, Oozie, YARN, Sentry и Knox в виде workflow-цепочек и дэшбордов, отображающих их состояние [3]. О том, что такое Pig и чем это отличается от Hive, читайте в нашей новой статье.
Одним из главных достоинств Hue является возможность подключения к различным источникам данных [1]:
- СУБД – Apache Hive, Impala, Pinot, Presto, Druid, Flink SQL, Spark SQL, Drill, Phoenix, ksqlDB, MySQL, MS SQL, Oracle, ClickHouse, Greenplum, Elasticsearch, PostgreSQL, Redshift, BigQuery, SQLLite, Azure SQL Database, Teradata, SAP, Vertica, Snowflake, AWS Athena, Dask SQL и пр.;
- хранилища данных – Apache Hadoop HDFS, Ozone, HBase, AWS S3, Azure File Systems, Google Cloud Storage. Как обратиться к таблицам HBase через SQL-запросы с Phoenix и Hue, читайте в нашей новой статье.
Hadoop для инженеров данных
Код курса
HDDE
Ближайшая дата курса
в любое время
Продолжительность
40 ак.часов
Стоимость обучения
89 600
Подключения к источникам данных реализуется через собственные интерпретаторы или коннекторы SqlAlchemy, которые необходимо добавить в ini-файл Hue. Как это работает, мы рассмотрим далее на примере Apache Spark SQL.
Spark SQL и Hadoop User Experience
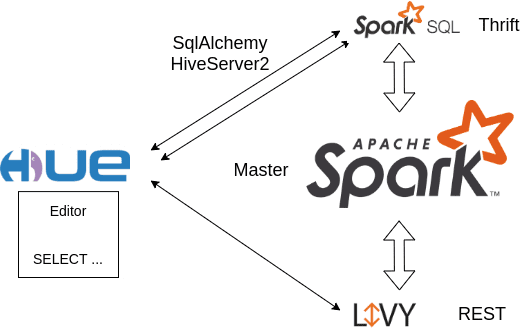
Типовым сценарием совместного использования Hue с Apache Livy и Спарк можно назвать следующий [4]:
- веб-редактор Hue используется для написания SQL-запросов;
- Spark SQL позволяет встроить логику запросов к данным в Спарк-приложение;
- REST-интерфейс с открытым исходным кодом Livy поддерживает выполнение фрагментов кода или программ в контексте Спарк локально или в YARN, позволяя создавать приложения или записные книжки для взаимодействия с Apache Spark в реальном времени.
Hue может подключаться к Spark SQL Thrift Server, о котором мы рассказывали здесь, с помощью 2-х интерфейсов [4]:
- SqlAlchemy – ORM-коннектор на основе универсальной библиотеки Python, который синхронизирует объекты Python и записи реляционной СУБД, позволяя описывать структуры баз данных и способы взаимодействия с ними на языке Python без использования SQL и работает как backend для разных баз данных, переключаться между которыми можно простым изменением конфигурации [5]
- HiveServer2 – собственный коннектор Hue для Apache Hive.
Основным преимуществом SqlAlchemy является синхронная отправка запросов, но API HiveServer2, пока является более близким и продвинутым. Более того, для SqlAlchemy требуется коннектор Hive, который по умолчанию работает с ошибкой из-за проблемы неполной совместимости Apache Hive со Spark Thrift. При этом метод get_table_names() класса HiveDialect в sqlalchemy_hive.py возвращает неверный список имен таблиц при запросе Spark SQL Thrift Server, включая туда список дубликатов schema_name [6]. Обойти это можно с помощью исправления, доступного в PyHive — наборе интерфейсов Python DB-API и SQLAlchemy для Presto и Hive [7].
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
1 июня, 2026
Продолжительность
16 ак.часов
Стоимость обучения
51 200
Узнайте больше подробностей про использование Apache Spark SQL и Livy для разработки распределенных приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Data pipeline на Apache AirFlow и Arenadata Hadoop
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
Источники
- https://gethue.com/
- https://gethue.com/how-to-use-the-livy-spark-rest-job-server-for-interactive-spark-2-2/
- https://habr.com/ru/post/283242/
- https://medium.com/data-querying/a-sparksql-editor-via-hue-and-the-spark-sql-server-f82e72bbdfc7
- https://ru.wikipedia.org/wiki/SQLAlchemy
- https://github.com/dropbox/PyHive/issues/150
- https://github.com/gethue/PyHive/

