 1853
1853 
Содержание
Сегодня поговорим про достоинства и недостатки массово-параллельной архитектуры для хранения и аналитической обработки больших данных, рассмотрев Greenplum и Arenadata DB. Читайте в нашей статье, что такое MPP-СУБД, где и как это применяется, чем полезны эти Big Data решения и с какими проблемами можно столкнуться при их практическом использовании.
Что MPP-СУБД и как это работает
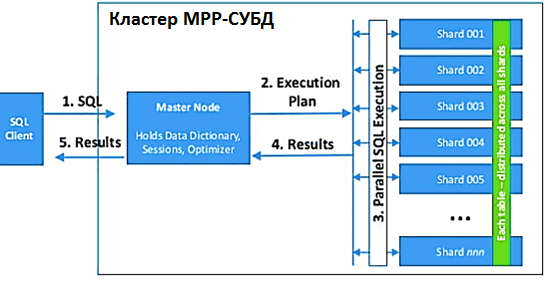
Особенностью массово-параллельная архитектура (Massive parallel processing, MPP) является физическое разделение памяти узлов, объединенных в кластер [1]. В случае MPP-СУБД каждый узел кластера работает со только своими жесткими дисками, распараллеливая операции чтения и записи данных. После того, как каждый из узлов закончит свои вычисления и отсортирует их в нужном порядке, ему нужно получить необходимые данные от остальных серверов. Для этого каждый узел отправляет свою порцию данных на все остальные сервера по быстрой обособленной сети (interconnect). Поскольку информация уже отсортирована, то на каждом узле при получении данных происходит отбор только тех записей, которые нужны для обработки, а остальные сразу отсеиваются и не занимают места в оперативной памяти. В итоге чтение с жестких дисков происходит быстрее, обработка результатов — тоже, и общее суммарное время выполнения операции оказывается в 10-100 раз меньше, чем в традиционных СУБД [2].
Несмотря на такие оптимистичные показатели скорости, MPP-СУБД не предназначена для быстрой обработки индивидуальных транзакций, как, например, OLTP-система. К примеру, запись данных в MPP-базу происходит вовсе не мгновенно, а представляет собой последовательность целую шагов [3]:
- сперва выполняется синтаксический разбор SQL-выражения;
- затем строится плана выполнения SQL-запроса;
- далее запрос отправляется на все узлы кластера и с ожиданием от каждого из них подтверждения насчет успешного выполнения. При этом возникает небольшая временная задержка из-за обмена данными по сети.
Таким образом, массивно-параллельные СУБД предназначены для хранения и обработки больших объемов данных (до сотен ТБ), а не для оперативных транзакций и быстрого построения аналитических отчетов, как, например, колоночные базы Arenadata QuickMarts и ClickHouse, о которых мы писали здесь.
Где и как используются массивно-параллельные базы данных в Big Data
На практике MPP-системы широко используются в области Big Data для предиктивной аналитики, регулярной отчетности и построения корпоративных хранилищ данных (КХД). В частности, построение аналитических моделей оттока клиентов (Churn Rate) – один из типовых вариантов применения MPP-СУБД [4]. Поэтому массивно-параллельные системы особенно востребованы в сфере торговли, где требуется анализировать большие объемы данных, например, сведения о товарах, клиентах и контрагентах, чеки и другая торговая информация. Именно поэтому крупный отечественный ритейлер X5 Retail Group выбрал MPP-СУБД Arenadata DB в качестве основы для своей распределенной аналитической платформы [5].
В свою очередь, Arenadata DB представляет собой коммерческий дистрибутив другого open-source проекта – распределенной СУБД для корпоративного сектора Greenplum. Сама система Greenplum базируется на свободной объектно-реляционной базе PostgreSQL с возможностью горизонтального масштабирования и столбцовым хранением данных, которое повышает эффективность их сжатия и снижает трафик для выполнения запросов [6]. Несмотря на open-source статус, Greenplum очень широко распространена в сегменте enterprise. Например, Тинькофф банк использует эту MPP-СУБД в качестве ядра для своего КХД [7].
Разумеется, Arenadata DB и Greenplum – не единственные представители систем MPP-класса на рынке Big Data СУБД. Среди проприетарных (и дорогих) систем наиболее известными считаются решения от Vertica, Teradata и Netezza [4]. К примеру, банк ВТБ построил свое КХД именно на Teradata, интегрировав ее с Apache Hadoop для распределенных вычислений [8].
Достоинства и недостатки массово-параллельной архитектуры
С учетом вышеописанных особенностей MPP-архитектуры, отметим ее основные преимущества для аналитических СУБД с позиции Big Data [9]:
- относительная быстрота обработки больших объемов данных при выполнении сложных SQL-запросов за счет распараллеливания операций и концепции Shared Nothing, когда каждый процессор имеет доступ только к своей локальной памяти и нет необходимости в потактовой синхронизации процессоров;
- простота горизонтального масштабирования до сотен узлов;
- отказоустойчивость за счет зеркалирования и резервирования.
Обратной стороной этих достоинств являются следующие недостатки:
- высокие требования к ресурсам ЦП, памяти и жестким дискам, а также к сетевой инфраструктуре [1];
- низкая производительность при большом объеме простых запросов, выполняющих одну операцию, т.к. каждая транзакция на мастере порождает множество зеркальных транзакций на сегментах [7];
- неоптимальное распределение сегментов, что может негативно отразиться на производительности кластера при его расширении [10].
Эти недостатки устраняются ведорами по мере развития MPP-систем. В частности, 6-ая версия Greenplum, вышедшая в конце 2019 года, позволяет оптимизировать распределение сегментов с помощью алгоритма consistent hashing. Он разрешает перераспределять только часть блоков при добавлении новых узлов в кластер, ускоряя фоновое перераспределение таблиц [9]. Что такое сегмент в кластере Greenplum и какие особенности эта архитектура накладывает на его использование, мы рассмотрим в следующей статье.
А практические навыки по администрированию и эксплуатации MPP-СУБД для эффективного хранения и аналитики больших данных вы получите на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://ru.wikipedia.org/wiki/Массово-параллельная_архитектура
- https://bi-cube.ru/v-chem-raznica-mezhdu-mpp-i-tradicionnymi-s/
- https://bi-cube.ru/kak-pravilno-rabotat-s-greenplum-chast-perv/
- https://arenadata.tech/products/db/
- https://arenadata.tech/about/cases/x5-retail-dwh.php
- https://ru.wikipedia.org/wiki/Greenplum
- https://habr.com/ru/company/tinkoff/blog/267733/
- https://habr.com/ru/article/348534/
- https://habr.com/ru/post/474008/
- https://globalcio.ru/live/projects/3309/

