 1402
1402 
Содержание
Продвигая наши обновленные курсы по Kafka, сегодня рассмотрим, почему в последнее время эту Big Data платформу потоковой обработки событий стали активно сравнивать с Apache Pulsar. Читайте далее, как устроен этот молодой, но интересный фреймворк потоковой обработки больших данных, чем он отличается от Kafka и RabbitMQ, что между ними общего и каковы его перспективы в мире Big Data.
Интеграция и потоковая аналитика больших данных: что такое Apache Pulsar
В real-time обработке больших данных и интеграции распределенных систем RabbitMQ считается самым популярным конкурентом Apache Kafka – Big Data платформы потоковой передачи событий. Об этом мы подробно рассказывали здесь. Однако, RabbitMQ – далеко не единственная альтернатива Kafka. С 2019 года все большую известность получает новый проект Apache Software Foundation (ASF) – фреймворк Pulsar. Изначально разработанный в Yahoo! для собственных нужд корпорации, в 2016 году Pulsar получил статус open-source, а еще через 2 года – стал проектом фонда ASF высшего уровня.
Эта облачная распределенная платформа обмена сообщениями между серверами и потоковой передачи позволяет управлять сотнями миллиардов событий в день. Аналогично Kafka, работая по модели «издатель-подписчик», Pulsar обеспечивает гарантированную доставку сообщений и легковесную вычислительную среду без сервера для потоковой обработки данных практически в режиме real-time. Это многопользовательское высокопроизводительное решение включает встроенную поддержку нескольких кластеров в одном экземпляре Pulsar, бесшовную распределенную репликацию сообщений между кластерами, масштабируемость до более миллиона топиков и гарантированную доставку сообщений с постоянным хранилищем на базе распределенного сервиса журналов Apache BookKeeper [1].
Отчет пользователей Pulsar за 2020 год показал ускорение темпов внедрения этого фреймворка в сложные ETL-процессы, микросервисные Big Data системы и различные бизнес-приложения потоковой обработки и аналитики больших данных в реальном времени. Среди наиболее известных клиентов Apache Pulsar можно отметить Verizon Media, Narvar, Overstock, Nutanix, Tencent, OVHCloud, Clever Cloud, а также множество других корпораций и компаний среднего размера [2]. Какие принципы работы и архитектуры обеспечивают такой успех Apache Pulsar, мы рассмотрим далее.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
24 августа, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Как устроен Apache Pulsar: архитектура и принципы работы
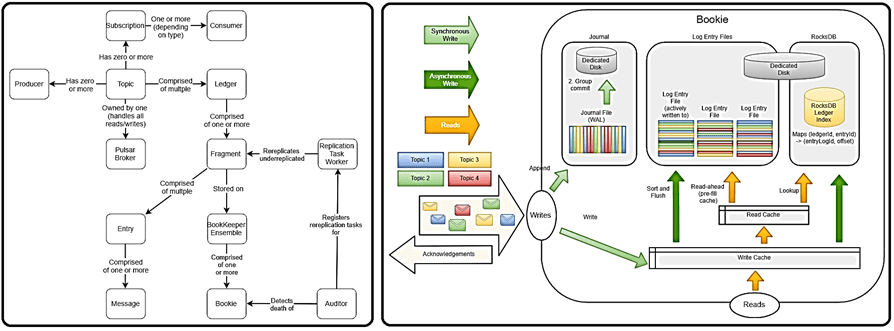
Pulsar состоит из 3 основных компонентов [3]:
- брокер – stateless-служба, к которой подключаются клиенты для обмена сообщениями;
- распределенный сервис логов Apache BookKeeper, узлы которого (букмекеры) хранят фактические сообщения и позиции курсора (Cursor) для их чтения из топика. BookKeeper использует RocksDB в качестве встроенной базы данных, которая используется для хранения внутренних индексов, но не управляется независимо от BookKeeper.
- сервис синхронизации распределенных систем Apache ZooKeeper для хранения метаданных брокеров и букмекеров.
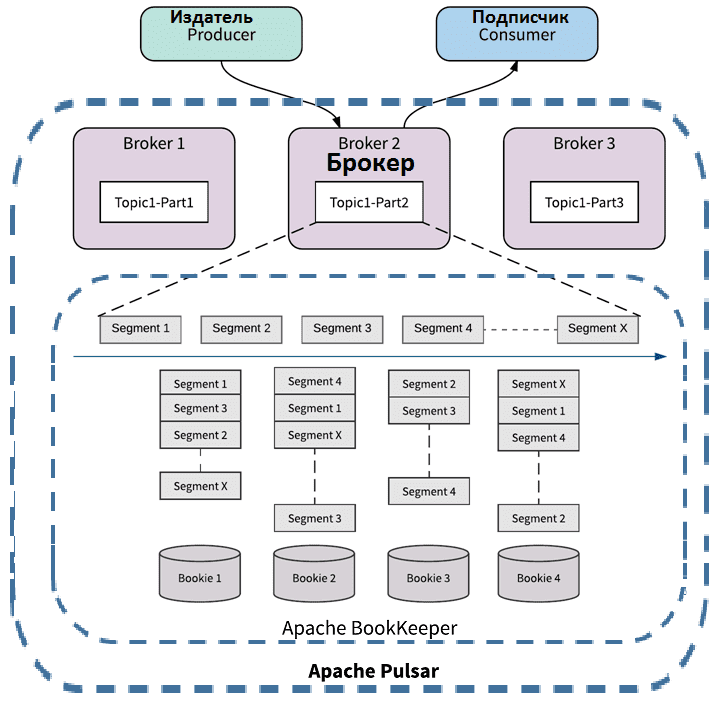
В отличие от Kafka, где используется модель монолитной архитектуры, которая тесно связывает обслуживание и хранение, Pulsar реализует многоуровневую структуру, позволяющую управлять этими функциями на отдельных уровнях. Брокер Pulsar выполняет вычисления на одном уровне, а букмекер управляет stateful-хранилищем на другом уровне. Наличие BookKeeper в архитектуре Pulsar обеспечивает более гибкую масштабируемость, меньшую операционную нагрузку, скорость и стабильность высокопроизводительной обработки Big Data.
Кратко принципы работы Apache Pulsar можно описать следующим образом [4]:
- Аналогично Kafka, Pulsar хранит сообщения в топиках – структуре журнала, где каждое сообщение имеет смещение, для отслеживания которого используется курсор (Cursor). Издатель или производитель (producer) отправляет свои сообщения в заданный топик, и Pulsar гарантирует, что после подтверждения сообщения оно не будет потеряно.
- Подписчик или потребитель (consumer) получает сообщения из топика через подписку (Subscription) – логическую сущность, которая отслеживает текущее смещение потребителя (курсор), а также предоставляет некоторые дополнительные гарантии в зависимости от типа подписки.
- Подписка может быть эксклюзивной (Exclusive), когда в один момент времени только один потребитель может читать топик. В общей (Shared) подписке конкурирующие потребители могут одновременно читать топик. А при подписке на отказ (Fail-Over Subscription) для потребителей применяется активный/резервный шаблон: при отказе активного потребителя его заменяет резервная копия, активный потребитель в один момент времени может быть только один. К одному топику может быть прикреплено несколько подписок. Подписки не содержат данных, только метаданные и курсор.
- Pulsar обеспечивает семантику очереди и журнала (лога), позволяя потребителям рассматривать топик как очередь, которая удаляет сообщения после подтверждения потребителем, или как журнал, где потребители могут перематывать курсор. При этом модель хранилища данных остается все тем же логом.
- Если для топика не задана политика хранения данных через пространство имен, то сообщения удаляются после того, как все курсоры прикрепленных подписок прошли его смещение, т.е. сообщение было подтверждено на всех подписках, прикрепленных к этому топику. Но, если задана политика хранения данных в топике, то сообщения удаляются после того, как они выходят за границу политики, например, по размеру или времени.
- Сообщения имеют срок действия – они удаляются, если вышло их время жизни (Time to Live, TTL). Это означает, что сообщения могут быть удалены до того, как любой потребитель получит возможность их прочитать. Срок действия применяется только к неподтвержденным сообщениям и подходит для семантики очередей.
- TTL применяются к каждой подписке отдельно, что означает логическое удаление данных. Фактическое удаление произойдет позже, в зависимости от других подписок и политики хранения данных.
- Потребители подтверждают получение сообщений по одному или оптом (кумулятивно), что лучше для пропускной способности, но вводит обработку дублей после сбоев потребителей. Кумулятивное подтверждение недоступно для общих подписок, т.к. подтверждения основаны на смещении. Однако API потребителя допускает пакетные подтверждения с меньшим количеством RPC-вызовов, что улучшает пропускную способность для конкурирующих потребителей по общей подписке.
Пульсар: Ускоренная Kafka или расширенный RabbitMQ?
Подобно Kafka, в Pulsar есть разделы топиков, которые тоже представляют собой топики. Как и в Apache Kafka, производитель может отправлять сообщения циклически, используя алгоритм хеширования или явно выбирать раздел. В Kafka каждая реплика раздела полностью хранится на одном брокере. Реплика раздела состоит из серии файлов сегментов и индексов. Эта модель хороша тем, что она простая и быстрая: все операции чтения и записи являются последовательными. Однако, у одного брокера должно быть достаточно хранилища для реплик, что требует много места на жестком диске. Кроме того, при масштабировании кластера становится необходимой перебалансировка разделов, что требует тщательного планирования и выполнения.
В Apache Pulsar каждый регистр из одного или нескольких фрагментов может быть реплицирован на несколько узлов BookKeeper для избыточности и повышения производительности чтения. Каждый фрагмент тиражируется в другом наборе букмекеров, если их достаточно. Данные топика распределены между несколькими букмекерами. Топик разделен на регистры (Ledger) и фрагменты (Fragment) с чередованием на вычисляемые подмножества ансамблей фрагментов. При расширении кластера нужно просто добавить букмекеров, и они начнут получать записи при создании новых фрагментов. Ребалансировка разделов не требуется. Каждый брокер Pulsar отслеживает регистры и фрагменты топика по метаданным, которые хранятся в ZooKeeper. Поэтому при сбое ZooKeeper, Pulsar также отказывает.
С точки зрения модели работы с сообщениями интересны следующие сходства и отличия Apache Pulsar от Kafka и RabbitMQ [5]:
- Kafka использует архитектуру на основе опроса, когда потребители получают сообщения с сервера, а длительный опрос используется для обеспечения мгновенного доступа к новым сообщениям.
- RabbitMQ использует подход на основе push, синоним традиционных систем обмена сообщениями.
- Pulsar также использует подход на основе push, но с API, имитирующим запросы потребителей.
Архитектуры на основе вытягивания (pull) обычно предпочтительнее для рабочих нагрузок с высокой пропускной способностью, позволяя потребителям управлять своим потоком данных, т.е. получать только то, что нужно. Push-архитектуры требуют, чтобы в брокер были интегрированы управление потоком и противодавление (backpressure). С точки зрения хранения данных Pulsar немного похож на Kafka и RabbitMQ, но с рядом отличий [5]:
- Kafka хранит данные в распределенный журнале фиксации, в конец которого добавляются новые записи. Чтения являются последовательными, начиная со смещения, данные копируются с нуля из дискового буфера в сетевой буфер. Это подходит для потоковой передачи событий.
- RabbitMQ и Pulsar используют системы хранения на основе индексов, храня данные в древовидной структуре, чтобы обеспечить быстрый доступ для подтверждения отдельных сообщений. Быстрые отдельные чтения в древовидных структурах компенсируются увеличением накладных расходов на запись данных, что проявляется в уменьшении пропускной способности записи или в увеличении задержки.
- RabbitMQ хранит сообщения только короткий период времени, а Pulsar и Kafka могут делать это неограниченно.
Таким образом, Pulsar сочетает достоинства Apache Kafka и RabbitMQ, чтобы избежать ограничений систем для построения распределенных приложений потоковой обработки и аналитики больших данных. В следующей статье мы подробнее рассмотрим сходства и отличия Apache Kafka и Pulsar, а также разберем, в каком случае стоит выбирать тот или иной Big Data фреймворк и почему.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
13 июля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
На практике узнать об особенностях администрирования кластеров и разработки Kafka-приложений для аналитики больших данных вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://streamnative.io/en/pulsar
- https://streamnative.io/whitepaper/apache-pulsar-user-survey-report-2020/
- https://streamnative.io/en/blog/tech/2020-07-08-pulsar-vs-kafka-part-1
- https://jack-vanlightly.com/blog/2018/10/2/understanding-how-apache-pulsar-works
- https://www.confluent.io/kafka-vs-pulsar/

