 1254
1254 
Содержание
Продвигая наш новый курс по графовым алгоритмам на больших данных, сегодня рассмотрим, почему концепция графов сегодня так востребована в Big Data и Machine Learning. Вас ждет краткий ликбез по модулю GraphX в Apache Spark и его отличия от API GraphFrames, а также особенности кластерной обработки и сохранения данных графа свойств.
Аналитика больших данных на графах: краткий ликбез
Напомним, граф – это математическая структура из вершин, связанных друг с другом с помощью ребер. Вершины представляют собой некоторые объекты, отношения между которыми показывают ребра. В информатике граф — это абстрактный тип данных, который предназначен для реализации математических концепций неориентированного и ориентированного графа. Структура данных графа может также связывать с каждым ребром некоторое значение ребра — символическую метку или числовой атрибут как весовой показатель стоимости, емкости, длины и пр.
Графовые базы данных и алгоритмы активно используются в следующих бизнес-задачах:
- разработка рекомендательных систем и персонализация маркетинговых предложений на основе выявления круга общения потребителя и определения его интересов;
- обнаружение подозрительных транзакций в приложении для обработки платежей и подозрительных схем в страховании;
- тематическое моделирование, включая кластеризацию документов и извлечение смысла из данных;
- подсчет популярности людей или постов в соцсетях;
- обнаружение сообществ для задач электронной коммерции и поиска пропавших людей;
- оптимизация маршрутов и другие транспортные (логистические) задачи – поиск кратчайшего или самого дешевого пути и пр.
В аналитике больших данных обработка данных графа включает его обход для поиска определенных узлов в наборе данных, которые соответствуют указанным шаблонам. Далее выполняется обнаружение связанных узлов и отношений в данных, чтобы увидеть шаблоны связей между различными объектами. Конвейер обработки данных обычно включает следующие этапы:
- предварительная обработка данных, включая ETL-процессы загрузки, преобразования и фильтрации;
- создание графа;
- анализ;
- постобработка.
Типичный инструмент графовой аналитики должен обеспечивать гибкость для работы с графами и с коллекциями, чтобы комбинировать различные задачи анализа данных, от ETL до исследовательского анализ и итеративного вычисления графов в одной системе. Сегодня наиболее популярными фреймворками такого типа считаются Spark GraphX, Gelly в Apache Flink и GraphLab. Также выделяют различные генераторов графов: Cycle Graph, Grid Graph, Hypercube Graph, Path Graph и Star Graph. А для визуализации закономерностей в основе отношений между объектами графа часто применяются D3.js, Linkurious и GraphLab Canvas.
Далее рассмотрим подробнее, как подходы графовой аналитики реализуются в одном из самых популярных Big Data фреймворков – Apache Spark.
Модули обработки графов в Apache Spark: GraphX vs GraphFrames
Для задач графовой аналитики в Apache Spark есть специальный модуль GraphX, который представляетс собой API для графов и параллельных вычислений. Он расширяет Spark RDD, вводя новую абстракцию Graph – ориентированный мультиграф свойств, характерных для каждой вершины и ребра. Его называют граф свойств (Property Graph), элементы которого представляют собой определяемыми пользователем объектами, прикрепленные к каждой вершине и ребру. Этот направленный мультиграф может иметь несколько параллельных ребер, имеющих одну и ту же исходную и целевую вершины. Такое распараллеливание упрощает сценарии моделирования, когда между одними и теми же вершинами может быть несколько отношений, например, коллега и друг, роль в проекте и должность в оргструктуре компании. Каждая вершина имеет уникальный 64-битный длинный идентификатор (VertexId). GraphX не накладывает никаких ограничений на порядок идентификаторов вершин. У ребер тоже есть соответствующие идентификаторы вершин источника и назначения. Граф свойств параметризован по типам вершин (VD) и ребер (ED).
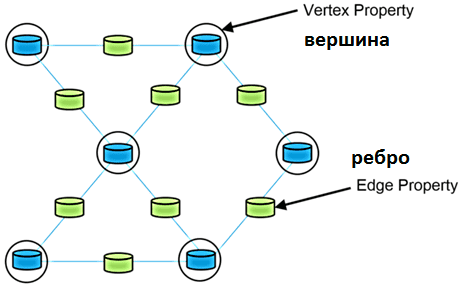
Как и RDD, графы свойств неизменяемы, распределены и отказоустойчивы. Изменения значений или структуры графа реализуются в новом графе. А неизменившиеся структура, атрибуты и индексы исходного графа повторно используются в новом, чтобы снизить потребление памяти и стоимость этой функциональной структуры данных. Граф разделяется между исполнителями Spark с использованием ряда эвристик разбиения вершин. Как и в случае с RDD, каждый раздел графа может быть воссоздан на другом узле Spark-кластера в случае сбоя. Чтобы снизить потребление памяти, GraphX оптимизирует представление типов вершин и ребер, когда они являются примитивными типами данных, такими как int, double и пр., сохраняя их в специализированных массивах.
Подобно базовым операциям RDD (map, filter и reduceByKey), графы свойств также имеют набор основных операторов, которые берут определенные пользователем функции и создают новые графы с преобразованными свойствами и структурой. Spark GraphX предоставляет операторы subgraph, joinVertices и aggregateMessages для преобразования данных графа, а также разные способы построения графа из набора вершин и ребер в RDD или сохранение на жестком диске.
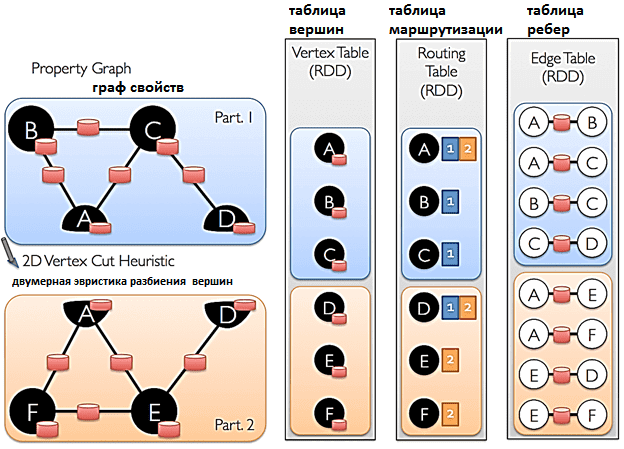
GraphX использует подход вершинной вырезки для разбиения распределенного графа. Вместо того, чтобы разбивать графы по ребрам, GraphX разбивает граф по вершинам, чтобы снизить накладные расходы на связь и хранение данных. Логически это соответствует назначению ребер узлам кластера и разрешению вершин охватывать несколько узлов. Точный метод назначения ребер зависит от стратегии разделения PartitionStrategy, которую могут определять пользователи с помощью оператора Graph.partitionBy.
После того, как ребра были разделены, ключевой задачей эффективных вычислений с параллельным графом является эффективное соединение атрибутов вершин с ребрами. Поскольку в реальных графах обычно больше ребер, чем вершин, атрибуты вершин перемещаются на ребра. Поскольку не все разделы будут содержать ребра, смежные со всеми вершинами, нужна таблица маршрутизации, которая определяет, куда транслировать вершины при реализации соединения для триплетов и алгоритма агрегации сообщений aggregateMessages.
Еще Spark GraphX включает оптимизированный вариант API системы Pregel — масштабируемой и отказоустойчивой платформы Google для выражения произвольных алгоритмов графов. Также GraphX включает большую коллекцию алгоритмов и построителей графов для упрощения задач графовой аналитики: ранжирование страниц, связанные компоненты, SVD++, подсчет треугольников, обнаружение сообществ. Все эти алгоритмы доступны в пакете org.apache.spark.graphx.lib и вызвать их можно как методы в классе Graph. Примеры их использования мы рассмотрим в следующий раз, а в заключение расскажем про GraphFrame.
GraphFrame – это новый компонент графовой аналитики в Apache Spark, который объединяет сопоставление с образцом и алгоритмы графов со Spark SQL. В отличие от GraphX, в GraphFrame вершины и ребра представлены как DataFrame вместо объектов RDD. Это повышает уровень абстракции, упрощая разработку графовых конвейеров аналитики больших данных с оптимизацией запросов как для графовых, так и для реляционных данных. Планировщик с поддержкой графов использует материализованные представления для повышения производительности запросов.
Кроме того, в дополнение к API Scala, GraphFrame также поддерживает Python с Java и позволяет сохранять и загружать графы в форматах Parquet, JSON и CSV. Компонент GraphFrame доступен как дополнение к GraphX и свободно загружается с официального сайта фреймворка spark-apache.org.
Перед использованием GraphX в Spark-проекте, сперва следует импортировать необходимые классы, включая RDD:
import org.apache.spark._
import org.apache.spark.rdd.RDD
import org.apache.spark.graphx._
import org.apache.spark.graphx.util.GraphGenerators
Например, объект org.apache.spark.graphx.util.GraphGenerators класса GraphGenerators предоставляет набор функций по генерации класса, от графа со случайными ребрами до графа в виде звезды с одной центральной вершиной. Подробнее о том, как звездчатые графы Spark используются в аналитической NoSQL-СУБД DataStax Enterprise Graph, читайте в нашей новой статье.
Практические примеры использования Apache Spark для разработки распределенных приложений и графовой аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

