 768
768 
Содержание
- Machine learning - множество математических, статистических и вычислительных методов для разработки алгоритмов, способных решить задачу не прямым способом, а на основе поиска закономерностей в разнообразных входных данных.
- Что такое Machine Learning
- Типы и суть Machine Learning
- Методы Machine Learning
- Средства реализации Machine Learning
Machine learning — множество математических, статистических и вычислительных методов для разработки алгоритмов, способных решить задачу не прямым способом, а на основе поиска закономерностей в разнообразных входных данных.
Что такое Machine Learning
Общий термин «Machine Learning» или «машинное обучение» обозначает множество математических, статистических и вычислительных методов для разработки алгоритмов, способных решить задачу не прямым способом, а на основе поиска закономерностей в разнообразных входных данных [1]. Решение вычисляется не по четкой формуле, а по установленной зависимости результатов от конкретного набора признаков и их значений. Например, если каждый день в течении недели земля покрыта снегом и температура воздуха существенно ниже нуля, то вероятнее всего, наступила зима. Поэтому машинное обучение применяется для диагностики, прогнозирования, распознавания и принятия решений в различных прикладных сферах: от медицины до банковской деятельности.
Типы и суть Machine Learning
Выделяют 2 типа машинного обучения [1]:
- Индуктивное или по прецедентам, которое основано на выявлении эмпирических закономерностей во входных данных;
- Дедуктивное, которое предполагает формализацию знаний экспертов и их перенос в цифровую форму в виде базы знаний.
Дедуктивный тип принято относить к области экспертных систем, поэтому общий термин «машинное обучение» означает обучение по прецедентам. Прецеденты или обучающая выборка – это наборы входных объектов и соответствующих им результатов. При этом не существует четкой формулы, которая аналитически описывает зависимость между результатами и входами. Например, какая погода будет завтра, если на протяжении недели дни были морозные, солнечные, с низкой влажностью воздуха, без ветра и осадков? При этом следует учесть еще множество параметров: географические координаты, рельеф местности, движение теплых и холодных фронтов воздуха и пр. Необходимо построить алгоритм, который выдаст достаточно точный результат для любого возможного входа. Точность результатов регулируется оценочным функционалом качества. Таким образом, решение формируется эмпирически, на основе анализа накопленного опыта. При этом обучаемая система должна быть способна к обобщению – адекватному отклику на данные, выходящие за пределы имеющейся обучающей выборки. На практике входные данные могут быть неполными, неточными и разнородными. Поэтому существует множество методов машинного обучения [2]. Можно сказать, что машинное обучение реализует подход Case Based Reasoning (CBR) — метод решения проблем рассуждением по аналогии, путем предположения на основе подобных случаев (прецедентов).

Методы Machine Learning
Существует множество методов машинного обучения. Мы перечислим самые популярные, оставив их подробную классификацию специализированным ресурсам [1, 2, 3]. Выделяют 2 вида классического Machine Learning:
- С учителем (supervised learning), когда необходимо найти функциональную зависимость результатов от входов и построить алгоритм, на входе принимающий описание объекта и на выходе выдающий ответ. Функционал качества, как правило, определяется через среднюю ошибку ответов алгоритма по всем объектам выборки. К обучению с учителем относятся задачи классификации, регрессии, ранжирования и прогнозирования.
- Без учителя (unsupervised learning), когда ответы не задаются, и нужно искать зависимости между объектами. Сюда входят задачи кластеризации, поиска ассоциативных правил, фильтрации выбросов, построения доверительной области, сокращения размерности и заполнения пропущенных значений.
К неклассическим, но весьма популярным методам относят обучение с подкреплением, в частности, генетические алгоритмы, и искусственные нейронные сети. В качестве входных объектов выступают пары «ситуация, принятое решение», а ответами являются значения функционала качества, который характеризует правильность принятых решений (реакцию среды). Эти методы успешно применяются для формирования инвестиционных стратегий, автоматического управления технологическими процессами, самообучения роботов и других подобных задач [2].
Ниже на рисунке показана классификация наиболее часто используемых методов Machine Learning [3].
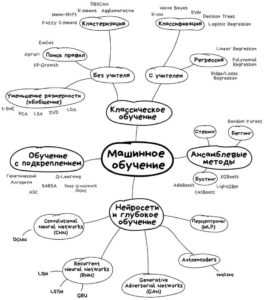
Средства реализации Machine Learning
Сегодня чаще всего для создания программ машинного обучения используются языки R, Python, Scala и Julia [4]. Они поддерживаются многими интегрированными средами разработки, в частности, R-Studio, R-Brain, Visual Studio, Eclipse, PyCharm, Spyder, IntelliJ IDEA, Jupyter Notebooks, Juno и др. [4]. На наших практических курсах мы научим вас успешной работе с этими инструментами, чтобы потом вы могли самостоятельно формировать наборы входных данных, строить эффективные алгоритмы для решения прикладных задач своей области: от нефтегазовой промышленности до биржевой аналитики. Выбирайте свой обучающий интенсив и приходите к нам на занятия!
Источники
- https://ru.wikipedia.org/wiki/Машинное_обучение
- http://www.machinelearning.ru/wiki/index.php?title=Машинное_обучение
- https://vas3k.ru/blog/machine_learning/
- https://semanti.ca/blog/?recommended-ide-for-data-scientists-and-machine-learning-engineers