 1825
1825 
Содержание
Avro – это линейно-ориентированный (строчный) формат хранения файлов Big Data, активно применяемый в экосистеме Apache Hadoop и широко используемый в качестве платформы сериализации.
Как устроен формат Avro для файлов Big Data: структура и принцип работы
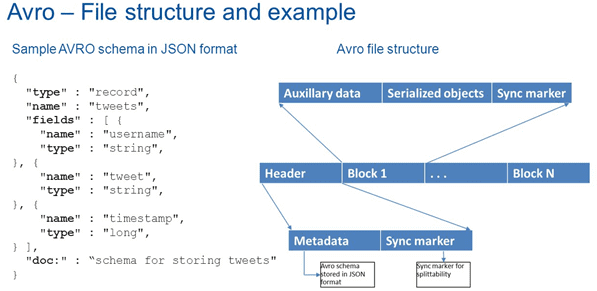
Avro сохраняет схему в независимом от реализации текстовом формате JSON (JavaScript Object Notation), что облегчает ее чтение и интерпретацию как программами, так и человеком [1].
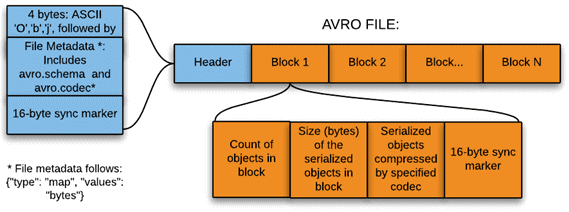
Файл Авро состоит из заголовка и блоков данных. Заголовок содержит:
- 4 байта, ASCII ‘O’, ‘b’, ‘j’, далее 1.
- метаданные файла, содержащие схему – структуру представления данных.
- 16-байтное случайное число — маркер файла.
Для блоков данных Avro может использовать компактную бинарную кодировку или человекочитаемый формат JSON, удобный для отладки.
В отличие от многих других форматов Big Data, столбцовых (RCFile, Apache ORC и Parquet) и линейно-ориентированных (Sequence, Map-File), Avro поддерживает эволюцию схем данных, обрабатывая изменения схемы путем пропуска, добавления или модификации отдельных полей. Авро не является строго типизированным форматом: информация о типе каждого поля хранится в разделе метаданных вместе со схемой. Благодаря этому для чтения сериализованной информации не требуется предварительное знание схемы [2]. О том, что такое сериализация и зачем нужны схемы данных, мы рассказывали здесь.
Авро обеспечивает богатую структуру данных, поддерживая следующие типы [3]:
- примитивные (null, Boolean, int, long, float, double, string, bytes, fixed);
- сложные составные (union, recod, enum, array, map);
- логические (decimal, date, time-millis, time-micros, timestamp-millis, timestamp-micros, uuid).
Достоинства и недостатки формата Авро
Линейная структура данных формата Avro обеспечивает следующие преимущества [1]:
- высокая скорость записи информации, что особенно важно в потоковых Big Data системах – именно поэтому Авро очень активно применяется в Apache Kafka и корпоративных озерах данных (Data Lake);
- формат отлично подходит для ETL-хранилищ и витрин данных, где требуется чтение всех полей записи, а не избирательно по столбцам, как в колоночно-ориентированных форматах.
Еще стоит отметить, что независимая от реализации человекочитаемая JSON-схема данных обеспечивает поддержку множества языков программирования (C, C++, C#, Go, Haskell, Java, Python, Scala, другие скриптовые и ООП-языки), а также облегчает отладку в процессе разработки. Наконец, наличие широких возможностей описания объектов и событий, включая создание собственных схем данных, и совместимость с предыдущими версиями по мере развития данных с течением времени, делают формат Avro отличным вариантом для потоковых данных [3].
Тем не менее, по сравнению с колоночно-ориентированными форматами (RCFile, Apache ORC и Parquet) Авро свойственны следующие недостатки [4, 1]:
- пониженная скорость чтения информации, поскольку требуется читать все поля записи;
- меньшая производительность при выполнении избирательных запросов;
- больший расход дискового пространства для хранения данных.
Источники
- https://blog.clairvoyantsoft.com/big-data-file-formats-3fb659903271
- https://ru.bmstu.wiki/Apache_Avro
- https://bigdataschool.ru/blog/kafka-big-data-apache-avro/
- http://datareview.info/article/test-proizvoditelnosti-apache-parquet-protiv-apache-avro/