 1676
1676 
Содержание
Greenplum – open-source продукт, массивно-параллельная реляционная СУБД для хранилищ данных с гибкой горизонтальной масштабируемостью и столбцовым хранением данных на основе PostgreSQL. Благодаря своим архитектурным особенностям и мощному оптимизатору запросов, Гринплам отличается особой надежностью и высокой скоростью обработки SQL-запросов над большими объемами данных, поэтому эта MPP-СУБД широко применяется для аналитики Big Data в промышленных масштабах [1].
История разработки и развития
Отметим наиболее значимые вехи развития проекта Greenplum [2]:
- 2005 год – первый выпуск технологии одноименной фирмой в Калифорнии (США);
- 2010 год — корпорация EMC поглотила компанию Greenplum, продолжив работу над проектом;
- 2011 год – корпорация EMC выпустила для всеобщего пользования бесплатную версию Greenplum Community Edition;
- 2012 год – корпорация Pivotal приобрела продукт EMC Greenplum Community Edition, продолжая далее развивать его под своим брендом;
- 2015 год – компания Pivotal опубликовала исходный код СУБД Greenplum под свободной лицензией Apache;
- 2018 год – интеграция с отечественной платформой визуализации и анализа данных Luxms BI;
- 2018 год – российская компания «Аренадата Софтвер», разработчик первого отечественного дистрибутива Apache Hadoop, выпустила собственную MPP-СУБД Arenadata DB на основе Greenplum, адаптировав ее для корпоративного использования.
- 2020 год — корпорация VMware приобрела компанию Pivotal, которая была вендором Greenplum (GP) с 2012 года. С этого момента open-source MPP-СУБД коммерциализируется под торговой маркой VMware Tanzu Greenplum
Как устроена Greenplum: архитектура и принципы работы
СУБД Greenplum представляет собой несколько взаимосвязанных экземпляров базы данных PostgreSQL, объединенных в кластер по принципу массивно-параллельной архитектуры (Massive Parallel Processing, MPP) без разделения ресурсов (Shared Nothing). При этом каждый узел кластера, взаимодействующий с другими для выполнения вычислительных операций, имеет собственную память, операционную систему и жесткие диски.
Для повышения надежности к типовой топологии master-slave добавлен резервный главный сервер. Так в состав кластера Greenplum входят следующие компоненты [1]:
- Мастер-сервер(Master host), где развернут главный инстанс PostgreSQL (Master instance). Это точка входа в Greenplum, куда подключаются клиенты, отправляя SQL-запросы. Мастер координирует свою работу с сегментами – другими экземплярами базы данных PostgreSQL. Мастер распределяет нагрузку между сегментами, но сам не содержит никаких пользовательских данных – они хранятся только на сегментах.
- Резервный мастер(Secondary master instance) — инстанс PostgreSQL, включаемый вручную при отказе основного мастера.
- Сервер-сегмент (Segment host), где хранятся и обрабатываются данные. На одном хост-сегменте содержится 2-8 сегментов Greenplum – независимых экземпляров PostgreSQL с частью данных. Сегменты Гринплам бывают основные (primary) и зеркальные (mirror). Primary-сегмент обрабатывает локальные данные и отдает результаты мастеру. Каждому primary-сегменту соответствует свое зеркало (Mirror segment instance), которое автоматически включается в работу при отказе primary.
- Интерконнект (interconnect) – быстрое обособленное сетевое соединение для связи между отдельными экземплярами PostgreSQL.
Мастер взаимодействует с сегментами Гринплам следующим образом [1]:
- пользователь подключается к базе данных с помощью клиентских программ: psql или через API-интерфейсы типа JDBC и ODBC;
- мастер аутентифицирует клиентские соединения и обрабатывает входящие SQL-запросы;
- каждый сегмент для обработки запроса создает соответствующие процессы;
- после выполнения вычислений над локальными данными сегмент возвращает результаты мастеру;
- мастер координирует результаты от сегментов и представляет конечный итог клиентской программе.
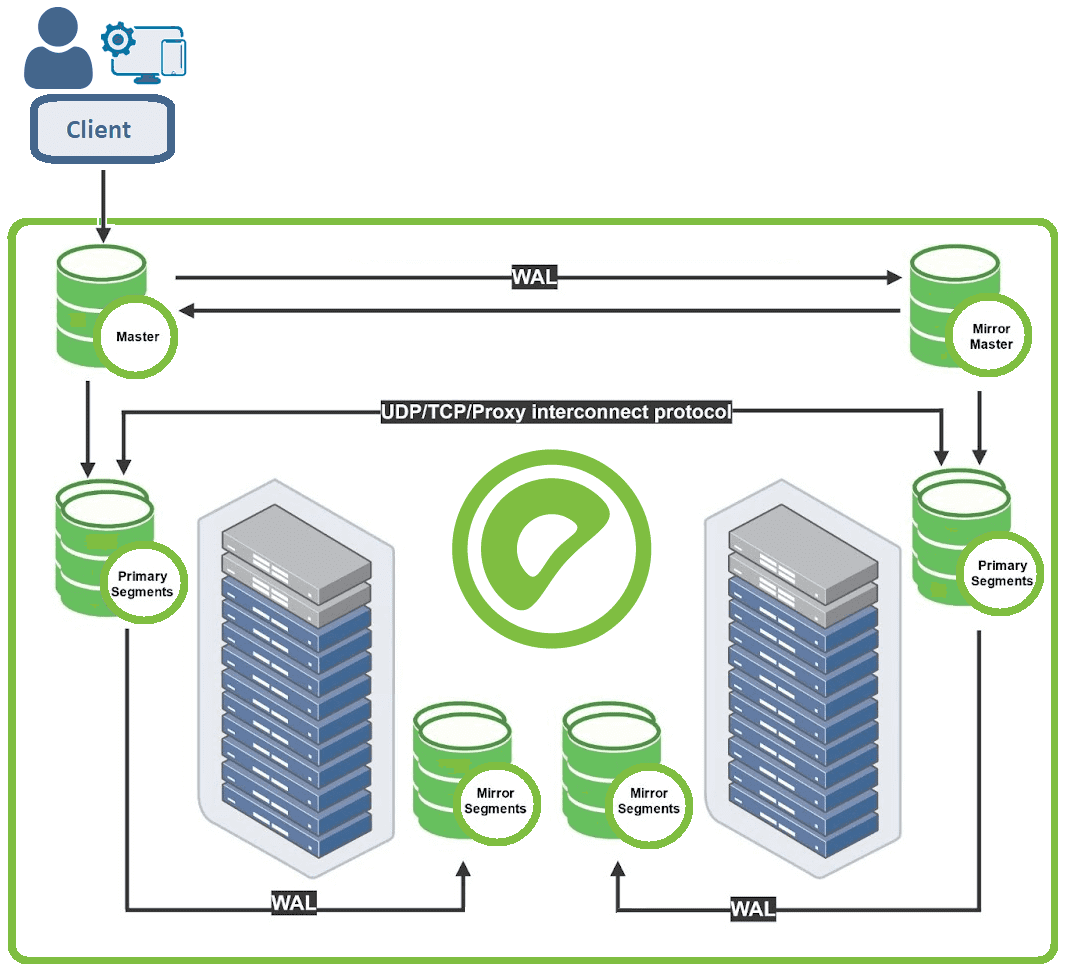
Подробнее архитектуру Greenplum и основные принципы работы этой MPP-СУБД мы рассматриваем здесь. Зеркалирование сегментов обусловливает повышенную надежность, однако приводит к избыточному потреблению ресурсов и удорожанию кластера. О других достоинствах и недостатках Гринплам читайте в нашей отдельной статье. А подробно, чем Greenplum отличается от PostgreSQL, мы рассказываем в этом материале.
Основные сценария использования в Big Data и примеры внедрения
Благодаря надежности, масштабируемости и высокой скорости обработки данных, наиболее востребованными сценариями применения Гринплам в Big Data считаются следующие:
- системы предиктивной аналитики и регулярной отчетности по большим объемам данных;
- построение озер (Data Lake) и корпоративных хранилищ данных (КХД);
- разработка аналитических моделей по множеству разнообразных данных, например, для прогнозирования оттока клиентов (Churn Rate).
Greenplum для инженеров данных и аналитиков данных
Код курса
GPDE
Ближайшая дата курса
25 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
На практике Greenplum широко используется в enterprise-секторе, где необходима быстрая и надежная аналитика больших данных: банки, телекоммуникационные компании, ритейл. Например, NYSE, NASDAQ, Boeing, At&T, Sony, включая Тинькофф Банк, Sberbank CIB, Ростелеком и прочие крупные корпорации [3]. Подробнее про некоторые примеры использования Greenplum и Arenadata DB в реальных проектах мы рассказываем в отдельной статье.
Источники
- https://ru.bmstu.wiki/Greenplum_DB
- http://www.tadviser.ru/index.php/Продукт:EMC_Greenplum_Database_Edition
- https://www.osp.ru/os/2018/01/13053940/