 2895
2895 
Содержание
Hadoop – это свободно распространяемый набор утилит, библиотек и фреймворк для разработки и выполнения распределённых программ, работающих на кластерах из сотен и тысяч узлов. Эта основополагающая технология хранения и обработки больших данных (Big Data) является проектом верхнего уровня фонда Apache Software Foundation.
Из чего состоит Hadoop: концептуальная архитектура
Изначально проект разработан на Java в рамках вычислительной парадигмы MapReduce, когда приложение разделяется на большое количество одинаковых элементарных заданий, которые выполняются на распределенных компьютерах (узлах) кластера и сводятся в единый результат [1].
Проект состоит из основных 4-х модулей:
- Hadoop Common – набор инфраструктурных программных библиотек и утилит, которые используются в других решениях и родственных проектах, в частности, для управления распределенными файлами и создания необходимой инфраструктуры [1];
- HDFS – распределённая файловая система, Hadoop Distributed File System – технология хранения файлов на различных серверах данных (узлах, DataNodes), адреса которых находятся на специальном сервере имен (мастере, NameNode) [2]. За счет дублирования (репликации) информационных блоков, HDFS обеспечивает надежное хранение файлов больших размеров, поблочно распределённых между узлами вычислительного кластера [1];
- YARN – система планирования заданий и управления кластером (Yet Another Resource Negotiator), которую также называют MapReduce 2.0 (MRv2) – набор системных программ (демонов), обеспечивающих совместное использование, масштабирование и надежность работы распределенных приложений [3]. Фактически, YARN является интерфейсом между аппаратными ресурсами кластера и приложениями, использующих его мощности для вычислений и обработки данных [1];
- Hadoop MapReduce – платформа программирования и выполнения распределённых MapReduce-вычислений, с использованием большого количества компьютеров (узлов, nodes), образующих кластер.
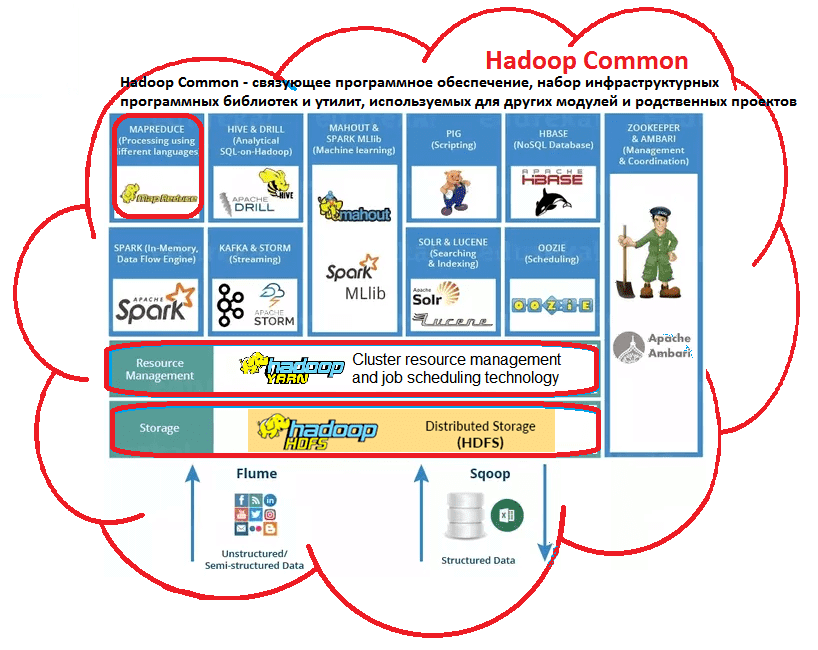
Сегодня вокруг Hadoop существует целая экосистема связанных проектов и технологий, которые используются для интеллектуального анализа больших данных (Data Mining), в том числе с помощью машинного обучения (Machine Learning) [2].
Как появился хадуп: история разработки и развития
Технология хадуп появилась почти 15 лет назад и постоянно развивается. Далее показаны основные вехи ее истории:
2005 – публикация сотрудников Google Джеффри Дина и Санжая Гемавата о вычислительной концепции MapReduce сподвигла Дуга Каттинга на инициацию проекта. Разработку в режиме частичной занятости вели Дуг Каттинг и Майк Кафарелла, чтобы построить программную инфраструктуру распределённых вычислений для свободной программной поисковой машины на Java. Свое название проект получил в честь игрушечного слонёнка ребёнка основателя [1]. Именно поэтому хадуп неформально называют «железный слон» и изображают его в виде этого животного.
2006 – корпорация Yahoo пригласила Каттинга возглавить специально выделенную команду разработки инфраструктуры распределённых вычислений, благодаря чему Hadoop выделился в отдельный проект [1].
2008 – Yahoo запустила кластерную поисковую машину на 10 тысяч процессорных ядер под управлением Hadoop, который становится проектом верхнего уровня системы проектов Apache Software Foundation. Достигнут мировой рекорд производительности в сортировке данных: за 209 секунд кластер из 910 узлов обработал 1 Тбайт информации. После этого технологию внедряют Last.fm, Facebook, The New York Times, облачные сервисы Amazon EC2 [1].
2010 – корпорация Google предоставила Apache Software Foundation права на использование технологии MapReduce. Hadoop позиционируется как ключевая технология обработки и хранения больших данных (Big Data). Начала формироваться Hadoop-экосистема: возникли продукты Avro, HBase, Hive, Pig, Zookeeper, облегчающие операции управления данными и распределенными приложениями, а также анализ информации [1].
2011 – получение ежегодной инновационной награды медиагруппы Guardian за универсальный подход к хранению и обработке распределенных данных («швейцарский нож XXI века») [1].
2013 – появление модуля YARN в релизе Hadoop 2.0 значительно расширяет парадигму MapReduce, повышая надежность и масштабируемость распределенных систем [3].
Где и зачем используется Hadoop
Выделяют несколько областей применения технологии [4]:
- поисковые и контекстные механизмы высоконагруженных веб-сайтов и интернет-магазинов (Yahoo!, Facebook, Google, AliExpress, Ebay и т.д.), в т.ч. для аналитики поисковых запросов и пользовательских логов;
- хранение, сортировка огромных объемов данных и разбор содержимого чрезвычайно больших файлов;
- быстрая обработка графических данных, например, газета New York Times с помощью хадуп и Web-сервиса Amazon Elastic Compute Cloud (EC2) всего за 36 часов преобразовала 4 терабайта изображений (TIFF-картинки размером в 405 КБ, SGML-статьи размером в 3.3 МБ и XML-файлы размером в 405 КБ) в PNG-формат размером по 800 КБ.

Все подробности о распределенной обработке данных, администрировании и применении Hadoop для проектов Big Data и Machine Learning на наших компьютерных курсах обучения разных групп пользователей, от «чайников» до профессионалов – хадуп для инженеров, администраторов и аналитиков больших данных в Москве:
- INTR: Основы Hadoop
- HADM: Администрирование кластера Hadoop
- DSEC: Безопасность озера данных Hadoop
- HDDE: Hadoop для инженеров данных
- BAHU: Основы Hadoop для пользователей
Источники
- https://ru.wikipedia.org/wiki/Hadoop
- https://m.habr.com/ru/post/240405/
- https://www.ibm.com/developerworks/ru/library/bd-hadoopyarn/index/
- https://www.ibm.com/developerworks/ru/library/l-hadoop/index/