 1591
1591 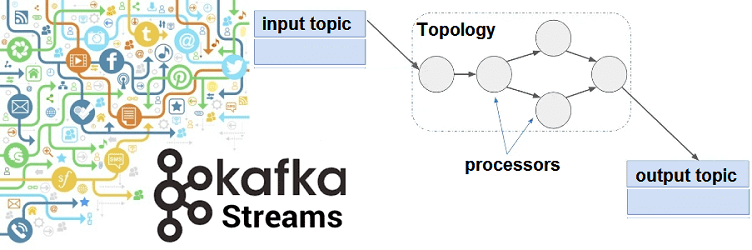
Содержание
Kafka Streams – это клиентская библиотека для разработки потоковых приложений Big Data, которые работают с данными, хранящимися в топиках Apache Kafka. Она предоставляет мощный и гибкий API-интерфейс со всеми преимуществами Кафка-платформы (масштабируемость, надежность, минимальную задержку, механизмы аналитических запросов), позволяя разработчику писать код в локальном режиме (вне кластера). Kafka Streams API, доступный в виде Java-библиотеки, представляет собой самый простой способ писать критически важные приложения и микросервисы реального времени со всеми преимуществами кластерной технологии на стороне сервера Kafka [1].
Ключевые достоинства, возможности и недостатки Kafka Streams
При том, что Kafka Streams является всего лишь библиотекой, она напрямую решает множество проблем разработки потоковых приложений аналитики больших данных [1]:
- высокая производительность, надежность и масштабируемость;
- одновременная обработка событий с минимальной задержкой в миллисекундах без использования микро-пакетного подхода;
- stateful-обработка, включая распределенные соединения и агрегаты;
- временные окна с неупорядоченными данными подобно модели DataFlow;
- распределенная обработка и отказоустойчивость с быстрым перезапуском в случае сбоя;
- возможность повторной обработки, чтобы пересчитать выходные данные при изменении кода;
- быстрые развертывания без простоев;
- наличие декларативного и функционального API высокого уровня в виде удобного DSL, а также императивного API более низкого уровня абстракции.
Барьер входа в эту Big Data технологию довольно низок: разработчик может быстро написать и запустить небольшую пробную версию на локальной машине. А для масштабирования потребуется только запустить дополнительные экземпляры приложения на нескольких узлах. Kafka Streams прозрачно обрабатывает балансировку нагрузки нескольких экземпляров одного и того же приложения, используя модель параллелизма самой платформы Kafka.
Другими важными достоинствами Kafka Streams с точки зрения разработчика Big Data являются следующие [2]:
- простота интеграции в любое Java-приложение и взаимодействия с любыми DevOps-инструментами для упаковки, развертывания и эксплуатации программного кода;
- отсутствие внешних зависимостей от других систем, кроме самой Apache Kafka в качестве внутреннего уровня обмена сообщениями;
- использование модели партиционирования Kafka для горизонтального масштабирования обработки при сохранении строгих гарантий упорядочения смещений в топике;
- отказоустойчивая поддержка локального состояния, что обеспечивает очень быстрые и эффективные stateful-операции, в т.ч. оконные соединения и агрегаты;
- поддержка семантику строго однократной обработки (exactly once) с гарантией, что каждая запись будет обработана один раз и только один раз, даже в случае сбоя на клиентах Streams или брокерах Kafka в процессе вычислений;
- включает необходимые примитивы потоковой обработки, а также высокоуровневый Streams DSL и низкоуровневый Processor API.
Обратной стороной этих достоинств являются следующие недостатки [3]:
- хотя Kafka Streams предоставляет разработчику мощный и гибкий API, многое скрыто «под капотом», что затрудняет ювелирную оптимизацию приложений;
- отсутствие автоматизированных средств рефакторинга кода увеличивает нагрузку на разработчика;
- автоматическая генерация внутренних хранилищ для состояний приложения в топиках Кафка, что может привести к увеличению объема обрабатываемых данных, обеспечивая отказоустойчивость приложений.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
13 июля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Как устроена Кафка Стримс: архитектура и принципы работы
Базовыми концепциями Kafka Streams являются следующие:
- Топик (Topic) – неограниченный, постоянно обновляемый набор данных или упорядоченная, воспроизводимая и отказоустойчивая последовательность неизменяемых записей, каждая из которых определяется как пара «ключ-значение» (key-value), где ключи и значения — это обычные массивы байтов (<byte[], byte[]>);
- Поток (Stream)– полная история всех случившихся событий, топик со схемой данных (schema), где ключи и значения уже не байтовые массивы, а имеют определённые типы;
- Таблица (Table)– агрегация событий на текущий момент, агрегированный поток данных.
При этом в Apache Kafka Streams поток можно рассматривать как таблицу и наоборот, о чем мы писали в этой статье. Приложение потоковой обработки определяет свою вычислительную логику через одну или несколько топологий процессоров — графов из потоковых процессоров (узлов), которые соединены потоками (ребрами). Потоковый процессор представляет собой этап обработки для преобразования данных в потоках путем однократного приема входной записи и передачи обратно в топик Kafka или внешнюю систему [2]. Подробнее об этом мы рассказывали здесь и здесь.
Каждый потоковый раздел представляет собой полностью упорядоченную последовательность записей данных и сопоставляется с разделом топика Kafka, а запись данных в потоке – с сообщением в этом топике. Ключи записей данных определяют разделение данных в Kafka и в Kafka Streams, задавая, как данные направляются в определенные разделы внутри топиков.
Топология обработчика приложения масштабируется за счет разделения на несколько задач. Kafka Streams создает фиксированное количество задач на основе разделов входного потока для приложения, назначая каждой задаче список разделов из входных потоков (топиков Kafka). Назначение разделов задачам никогда не меняется, поэтому каждая задача представляет собой фиксированную единицу параллелизма приложения. Затем задачи могут создавать экземпляры своей собственной топологии обработчика на основе назначенных разделов, поддерживая буфер для каждого из назначенных разделов и обрабатывая оттуда по одному сообщению. Таким образом, все потоковые задачи автоматически обрабатываются независимо и параллельно.
Максимальный параллелизм приложения ограничен максимальным количеством потоковых задач, т.е. числом разделов входного топика, откуда считываются данные. Например, если входной топик имеет 5 разделов, можно запустить до 5 экземпляров приложений, которые будут совместно обрабатывать данные. В случае запуска большего количества экземпляров приложения, «лишние» экземпляры будут запускаться, но простаивать, а если один из занятых экземпляров выйдет из строя, то бездействующий возьмет на себя его работу.
Kafka Streams позволяет пользователю настроить количество потоков, которые библиотека может использовать для распараллеливания обработки в экземпляре приложения. Каждый поток может независимо выполнять одну или несколько задач со своей топологией процессора. Например, на следующей диаграмме показан один потоковый поток, выполняющий две потоковые задачи.
Kafka Streams — это не менеджер ресурсов, а библиотека, которая запускается везде, где работает приложение потоковой обработки. Несколько экземпляров приложения выполняются на одном узле или распределяются по нескольким машинам, и задачи могут автоматически распределяться библиотекой для этих запущенных экземпляров приложения. Назначение разделов задачам никогда не меняется, а в случае сбоя экземпляра приложения все назначенные ему задачи будут автоматически перезапущены на других экземплярах, продолжая использовать те же разделы потока. Такая попытка найти компромисс между балансировкой нагрузки и закреплением stateful-задач в Kafka Streams обеспечивается с помощью класса StreamsPartitionAssignor [4].
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
13 июля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Источники
- https://www.confluent.io/blog/introducing-kafka-streams-stream-processing-made-simple/
- https://kafka.apache.org/27/documentation/streams/core-concepts
- https://medium.com/@stephane.maarek/the-kafka-api-battle-producer-vs-consumer-vs-kafka-connect-vs-kafka-streams-vs-ksql-ef584274c1e
- https://kafka.apache.org/27/documentation/streams/architecture