 482
482 
Содержание
- Архитектура и компоненты
- Техническое погружение в детали производительности и использования Page Cache
- Ключевые абстракции - Streams и Tables
- Типы запросов Push & Pull
- Практика - Развертывание в Yandex Cloud
- Сценарий - Аналитика Retail-датасета
- Шаг 1: Регистрация потока (Ingestion)
- Шаг 2: Оконные функции (Windowing)
- Шаг 3: Объединение потоков (JOIN)
- Управление коннекторами
- Сравнение технологий потоковой обработки
- Заключение
- Референсные ссылки
ksqlDB — это потоковая SQL-платформа для обработки и анализа данных в реальном времени поверх Apache Kafka, позволяющая создавать непрерывные запросы, трансформации и агрегаты над потоками данных с использованием SQL, вместо написания низкоуровневого кода на Java или Scala. Это инструмент, который превращает поток событий в структурированную базу данных, доступную для мгновенных запросов.
Архитектура и компоненты
Система ksqlDB не является самостоятельным хранилищем данных в классическом понимании (как PostgreSQL). Это вычислительный слой, который использует ресурсы кластера Kafka для транспорта и хранения логов.
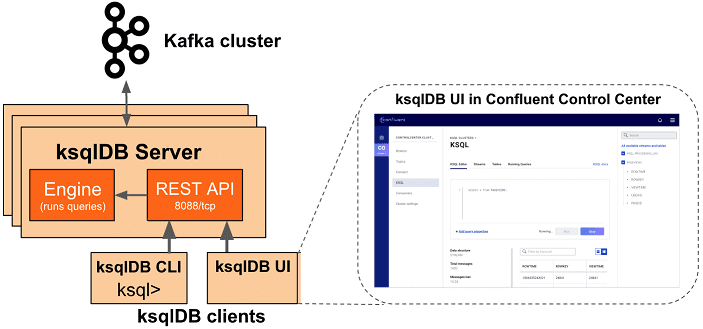
Архитектура решения состоит из нескольких ключевых элементов.
- ksqlDB Server. «Мозг» системы. Он принимает SQL-запросы, компилирует их в топологии Kafka Streams и управляет их выполнением.
- RocksDB. Встроенная в каждый узел сервера key-value база данных. Она хранит локальное состояние (state), например, текущую сумму покупок пользователя.
- Command Topic. Служебный топик Kafka, через который узлы кластера ksqlDB синхронизируют между собой созданные запросы.
- Kafka Topics. Служат фундаментом для физического хранения всех входных и выходных данных.
Таким образом, ksqlDB объединяет в себе механизм обработки логов (Kafka) и механизм хранения состояний (RocksDB).
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
24 августа, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Техническое погружение в детали производительности и использования Page Cache
Понимание физики работы ksqlDB критично для эксплуатации высоконагруженных систем. ksqlDB Server ведет себя как стандартный Kafka Consumer, но с важными нюансами.
Существует два режима потребления данных с разным влиянием на железо.
- Real-time режим (Low Impact). Если сервер успевает обрабатывать поток по мере поступления, он считывает данные из OS Page Cache (оперативной памяти брокеров). Это самый быстрый путь, который практически не создает нагрузки на дисковую подсистему брокеров.
- Режим Backfilling (High I/O). Когда вы запускаете запрос с параметром auto.offset.reset=’earliest’, ksqlDB начинает читать исторические данные. Брокерам приходится поднимать старые сегменты с жесткого диска (HDD/SSD). Это вызывает резкий рост Disk I/O, что может замедлить работу всего кластера.
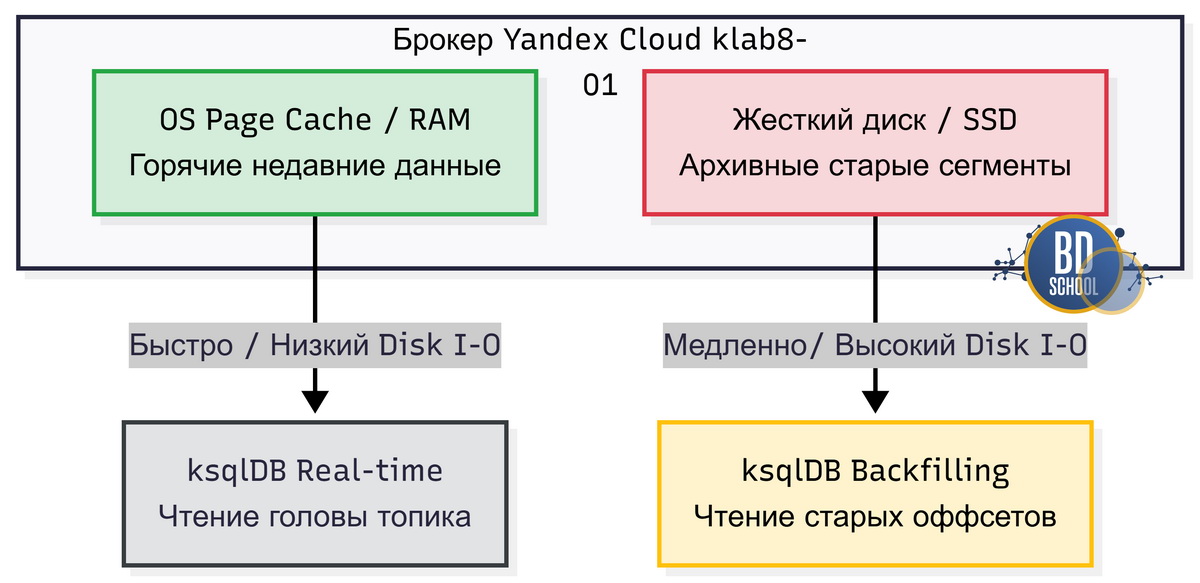
При планировании мощностей всегда учитывайте этот фактор, чтобы аналитические задачи не «положили» операционный кластер.
Ключевые абстракции — Streams и Tables
Философия ksqlDB строится на дуализме (двойственности) потоков и таблиц.
STREAMS (Потоки) — это бесконечная лента событий. Факты в потоке неизменяемы. Если пользователь совершил покупку, это событие навсегда останется в истории, даже если он потом отменил заказ (это будет новым событием). Аналогия: лог транзакций в банке.
TABLES (Таблицы) — это мгновенный снимок состояния. Таблица хранит только последнее актуальное значение для каждого ключа. Если в поток приходит событие с уже существующим ID, таблица обновляет значение. Аналогия: текущий баланс счета.
Взаимодействие между ними позволяет конвертировать историю в состояние (агрегация) и состояние обратно в поток (CDC).
Типы запросов Push & Pull
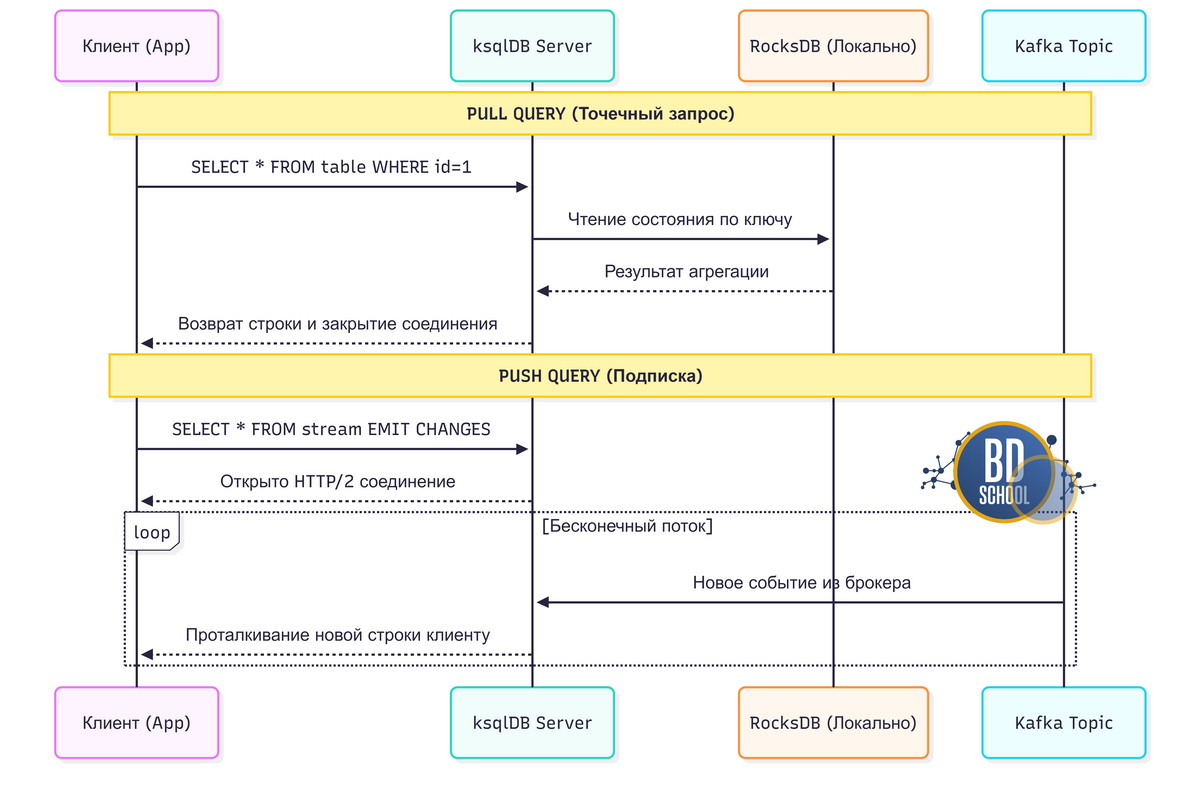
ksqlDB разделяет запросы на два фундаментальных типа в зависимости от сценария потребления.
Push Queries (Подписка)
Это бесконечные запросы, которые инициируются ключевой фразой EMIT CHANGES.
- Механика: Клиент открывает постоянное соединение (HTTP/2). Сервер «проталкивает» (push) каждую новую строку, удовлетворяющую условию, как только она появляется.
- Применение: Алертинг, мониторинг, обновление веб-сокетов на фронтенде.
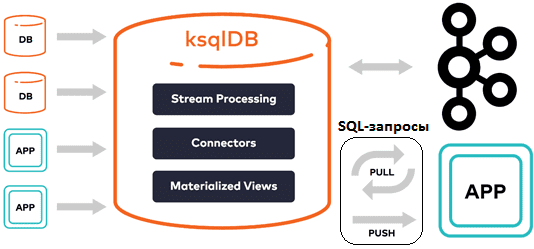
Pull Queries (Точечный запрос)
Это классические запросы, похожие на SELECT в PostgreSQL.
- Механика: Клиент запрашивает текущее состояние по ключу. Сервер идет в локальную RocksDB, мгновенно достает значение и закрывает соединение.
- Применение: Отрисовка профиля пользователя, проверка баланса, REST API микросервисов.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
13 июля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Практика — Развертывание в Yandex Cloud
Для работы с вашими нодами (kafka-lab9-01…03) через протокол PLAIN, используйте следующий конфиг docker-compose. Это позволит поднять сервер локально, но обрабатывать данные из облака.
services:
ksqldb-server:
image: confluentinc/ksqldb-server:0.29.0
hostname: ksqldb-server
container_name: ksqldb-server
ports:
- "8088:8088"
environment:
KSQL_LISTENERS: "http://0.0.0.0:8088"
KSQL_BOOTSTRAP_SERVERS: "klab8-01.ru-central1.internal:9092,klab8-02.ru-central1.internal:9092,klab8-03.ru-central1.internal:9092"
KSQL_SECURITY_PROTOCOL: "PLAINTEXT"
KSQL_KSQL_LOGGING_PROCESSING_STREAM_AUTO_CREATE: "true"
KSQL_KSQL_LOGGING_PROCESSING_TOPIC_AUTO_CREATE: "true"
Запустите контейнер командой docker-compose up -d и подключитесь к консоли: docker exec -it ksqldb-server ksql http://localhost:8088.
Сценарий — Аналитика Retail-датасета
Для сквозного примера используем Retail Real-Time Dataset (события: view, cart, purchase).
Для вставки данных из csv используем python скрипт load_data.py из нашего репозитория кода для данной статьи .
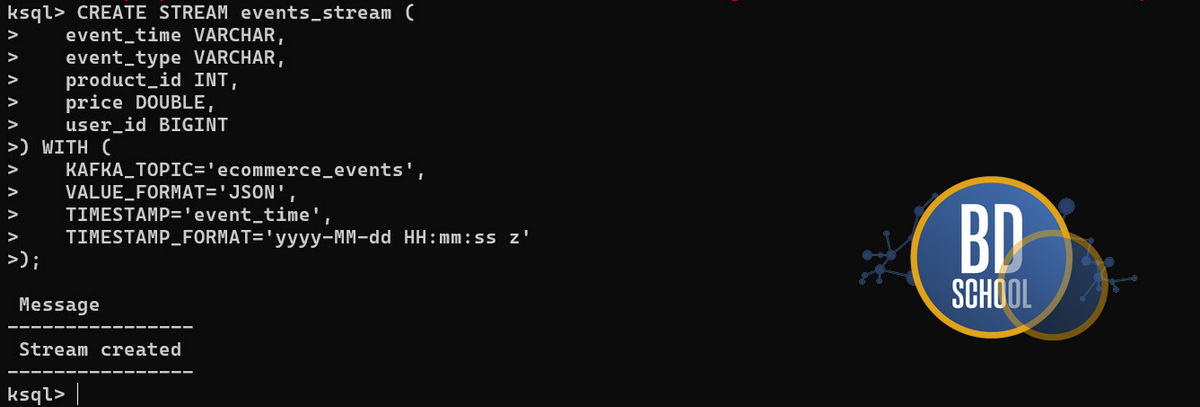
Шаг 1: Регистрация потока (Ingestion)
Опишем структуру входящих JSON-событий из топика ecommerce_events:
CREATE STREAM events_stream (
event_time VARCHAR,
event_type VARCHAR,
product_id INT,
category_id BIGINT,
price DOUBLE,
user_id BIGINT
) WITH (
KAFKA_TOPIC='ecommerce_events',
VALUE_FORMAT='JSON',
TIMESTAMP='event_time',
TIMESTAMP_FORMAT='yyyy-MM-dd HH:mm:ss z'
);
Проверяем созданную таблицу и импорт данных из kafka топика

Шаг 2: Оконные функции (Windowing)
Посчитаем трендовые товары. Найдем продукты, которые покупали чаще всего за последний час, обновляя рейтинг каждую минуту (Hopping Window). Создадим таблицу
CREATE TABLE trending_products AS
SELECT product_id, COUNT(*) AS purchases
FROM events_stream
WINDOW HOPPING (SIZE 1 HOUR, ADVANCE BY 1 MINUTE)
WHERE event_type = 'purchase'
GROUP BY product_id
EMIT CHANGES;

Шаг 3: Объединение потоков (JOIN)
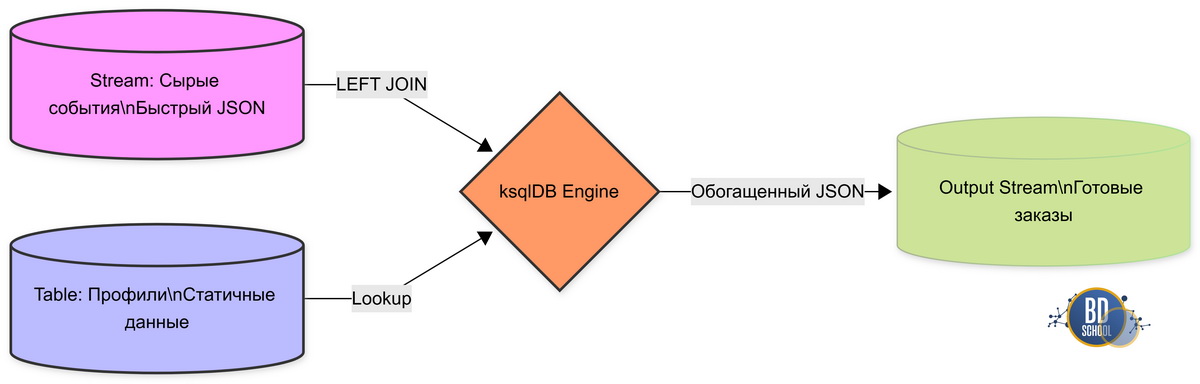
Часто поток событий содержит только ID, и его нужно обогатить данными о пользователе. Создадим справочную таблицу и объединим её с потоком.
Сначала создаем таблицу профилей. При работе с данной таблицей может возникнуть ошибка «number of partitions don’t match», которая возникает из-за механики работы джоинов под капотом. Чтобы объединить данные локально и быстро, без пересылки огромных массивов по сети между нодами кластера, ksqlDB строго требует, чтобы объединяемые потоки и таблицы имели одинаковое количество партиций и были сгруппированы по одному и тому же ключу. В нашем случае 9 партиций в исходной и объединяемой user_profiles.
CREATE TABLE user_profiles ( user_id BIGINT PRIMARY KEY, email VARCHAR, status VARCHAR ) WITH ( KAFKA_TOPIC='user_profiles', VALUE_FORMAT='JSON', PARTITIONS=9 );
Поскольку у нас нет готового топика с регистрациями пользователей из исходного датасета, наша новая таблица сейчас абсолютно пустая. Чтобы склейка отработала наглядно и подтянула какие-то реальные значения, давай добавим пару тестовых записей руками. ksqlDB отлично поддерживает стандартный INSERT.
INSERT INTO user_profiles (user_id, email, status) VALUES (123456789, 'test1@mail.ru', 'GOLD'); INSERT INTO user_profiles (user_id, email, status) VALUES (987654321, 'test2@ya.ru', 'BASIC');
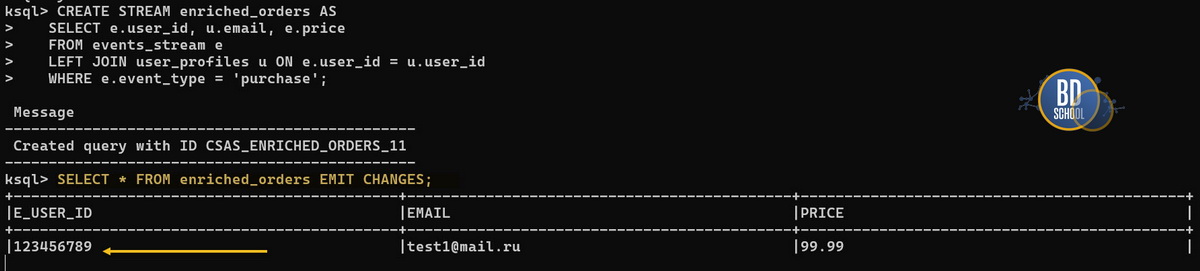
Вот теперь справочник готов к работе. Можешь смело запускать свой первоначальный запрос на создание обогащенного потока. Теперь выполняем Stream-Table JOIN для обогащения каждой покупки email-адресом:
CREATE STREAM enriched_orders AS SELECT e.user_id, u.email, e.price FROM events_stream e LEFT JOIN user_profiles u ON e.user_id = u.user_id WHERE e.event_type = 'purchase';
Если запустить бесконечный Push-запрос командой SELECT * FROM enriched_orders EMIT CHANGES;. Твоя консоль перейдет в режим ожидания. Она начнет выводить каждую новую покупку на экран. и при вставке новой транзакции мы отловим новое срабатывание
INSERT INTO events_stream (event_time, event_type, product_id, price, user_id)
VALUES ('2023-10-01 12:00:00 UTC', 'purchase', 777, 99.99, 123456789);
Управление коннекторами
ksqlDB позволяет управлять загрузкой и выгрузкой данных без прямого обращения к REST API Kafka Connect. Вы можете запускать коннекторы прямо через SQL.
Пример запуска JDBC Source коннектора для забора данных из PostgreSQL:
CREATE SOURCE CONNECTOR jdbc_source WITH ( 'connector.class' = 'io.confluent.connect.jdbc.JdbcSourceConnector', 'connection.url' = 'jdbc:postgresql://db-host:5432/postgres', 'topic.prefix' = 'pg-', 'table.whitelist' = 'users, products', 'mode' = 'incrementing', 'incrementing.column.name' = 'id' );
Это превращает ksqlDB в единую панель управления (Control Plane) для всего пайплайна данных.
Сравнение технологий потоковой обработки
При проектировании архитектуры важно понимать, где заканчиваются возможности ksqlDB и начинаются задачи для более мощных инструментов.
| Характеристика | ksqlDB | ClickHouse Kafka Engine | Apache Flink (Flink SQL) |
| Метод чтения | Построчный (Consumer) | Батчевый (вставка пачками) | Потоковый (Native Streaming) |
| Latency | Миллисекунды | Секунды | Миллисекунды |
| Сложные JOIN | Ограничены окнами | Почти безграничны (в БД) | Максимальная гибкость |
Вердикт:
- ksqlDB лучше подходит для простых трансформаций и логики мгновенной реакции.
- ClickHouse незаменим для глубокой исторической аналитики.
- Apache Flink — это «тяжелая артиллерия», которая позволяет выполнять сложнейшие Join-ы (включая Temporal и Versioned Joins) с сохранением минимальной задержки.
Заключение
На данный момент самой актуальной самостоятельной версией ksqlDB является 0.29.0. Этот релиз вышел в середине 2023 года. Для пользователей Confluent Platform инструмент доступен по умолчанию в актуальных ветках 7.6 и 8.x. Однако архитекторам стоит учитывать важный стратегический сдвиг на рынке. Компания Confluent официально сместила фокус развития потоковой обработки на Apache Flink.
Смена ключевого вектора развития обусловлена несколькими объективными архитектурными ограничениями самого ksqlDB.
-
Управление состоянием. Локальная база RocksDB отлично работает на одиночных узлах. Но при масштабировании сложных агрегаций Flink предлагает более надежные механизмы распределенных чекпоинтов.
-
Сложные объединения потоков. Инструмент ksqlDB требует строгого копартиционирования для выполнения запросов JOIN. Движок Flink умеет делать динамическое перераспределение данных прямо в оперативной памяти.
-
Поддержка языков программирования. Декларативный SQL подходит не для всех бизнес-задач. Экосистема Flink позволяет писать сложную императивную логику на Java или Python.
По этим причинам выход новых мажорных версий ksqlDB сильно замедлился. Все главные инновации вендор сейчас направляет исключительно в экосистему Flink.
Что это значит для новых проектов? Проект ksqlDB поддерживается и работает абсолютно стабильно. Если вам нужно просто фильтровать сырой трафик или делать легкое обогащение данных, он остается отличным выбором. Для построения тяжелой аналитики реального времени лучше сразу изучать возможности Flink SQL.
Референсные ссылки
- [Официальная документация ksqlDB] (https://docs.ksqldb.io/)
- [Kaggle: Retail Real-Time Dataset] (https://www.kaggle.com/datasets/mkechinov/ecommerce-events-history-in-cosmetics-shop)
- [Confluent: Push vs Pull Queries] (https://www.confluent.io/blog/ksqldb-pull-queries-aggregations/)
- [ClickHouse Kafka Engine Documentation] (https://clickhouse.com/docs/en/engines/table-engines/integrations/kafka)