 2159
2159 
Содержание
- NoSQL vs. SQL. Глубокие отличия
- Фундаментальные концепции NoSQL
- Теорема CAP
- MPP (Massively Parallel Processing)
- WORM (Write Once, Read Many)
- Обзор 6-ти типов NoSQL
- Key-Value (Ключ-значение)
- Document (Документные)
- Columnar (Колоночные)
- Graph (Графовые)
- Search (Поисковые)
- In-Memory (В оперативной памяти)
- Актуальные тренды 2025: NoSQL на "HypeCycle" Gartner
- Как выбрать правильную NoSQL-базу?
- Заключение: Эра "Polyglot Persistence"
- Референсные ссылки
NoSQL (Нереляционные базы данных) — это базы данных, которые используют для хранения информации модели, отличающиеся от привычных нам плоских таблиц. Термин NoSQL («Not Only SQL») означает, что эти решения не ограничиваются жесткими рамками реляционной логики. Они предлагают более гибкие способы организации данных.
В отличие от классического подхода, где структура данных (схема) должна быть утверждена заранее, NoSQL фокусируется на том, чтобы хранить данные в их «естественном» виде. Если это профиль пользователя — храним его как JSON-документ. Если это социальные связи — храним как граф. Если это поток событий — храним как колонки.
Главная задача NoSQL — обеспечить эффективное хранение и быстрый доступ (чтение/запись) к огромным массивам неструктурированной информации, с которой обычные таблицы уже не справляются.
NoSQL vs. SQL. Глубокие отличия
Выбор между NoSQL и SQL — это выбор способа мышления о данных. Он определяет, как ваше приложение будет расти и обрабатывать запросы.
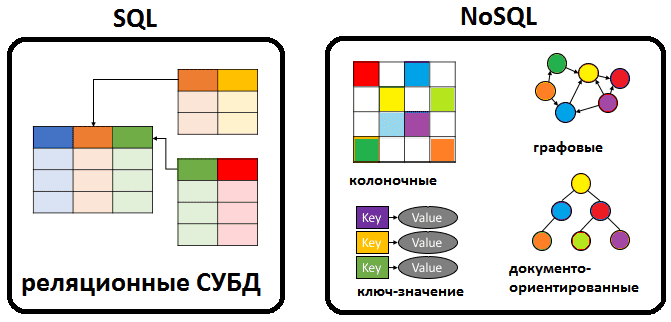
Различия можно свести к четырем практическим аспектам.
- Язык запросов и доступ. Доступ к данным в NoSQL не регламентируется формально стандартом ANSI SQL. Каждая NoSQL-база использует свой уникальный API или специализированный язык. Операции UPDATE и DELETE могут быть сильно ограничены.
- Гарантии (ACID vs. BASE). SQL-базы жестко следят за транзакциями (ACID). NoSQL часто выбирает модель BASE. Здесь важнее, чтобы система всегда ответила на запрос. Это допускает временное запаздывание синхронизации данных.
- Масштабирование (Рост). SQL растет «вверх» (Scale-Up): нужен более мощный сервер. NoSQL растет «вширь» (Scale-Out): данные просто распределяются по десяткам обычных серверов.
- Схема (Гибкость). SQL требует порядка: сначала создай таблицу, потом пиши. NoSQL разрешает хаос: пиши данные любой структуры сейчас, а разберешься с полями при чтении (Schema-on-Read).
Фундаментальные концепции NoSQL
Чтобы эффективно использовать эти инструменты, нужно понимать три принципа, на которых строится работа с большими данными.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
27 июля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Теорема CAP
Это правило «треугольника» для распределенных систем. Оно гласит, что при сбоях в сети вы не можете гарантировать все три свойства одновременно.
- C (Consistency) — Согласованность. Все видят одни и те же данные одновременно.
- A (Availability) — Доступность. Система отвечает на запросы всегда.
- P (Partition Tolerance) — Устойчивость к разделению. Система работает, даже если связь между серверами пропала.
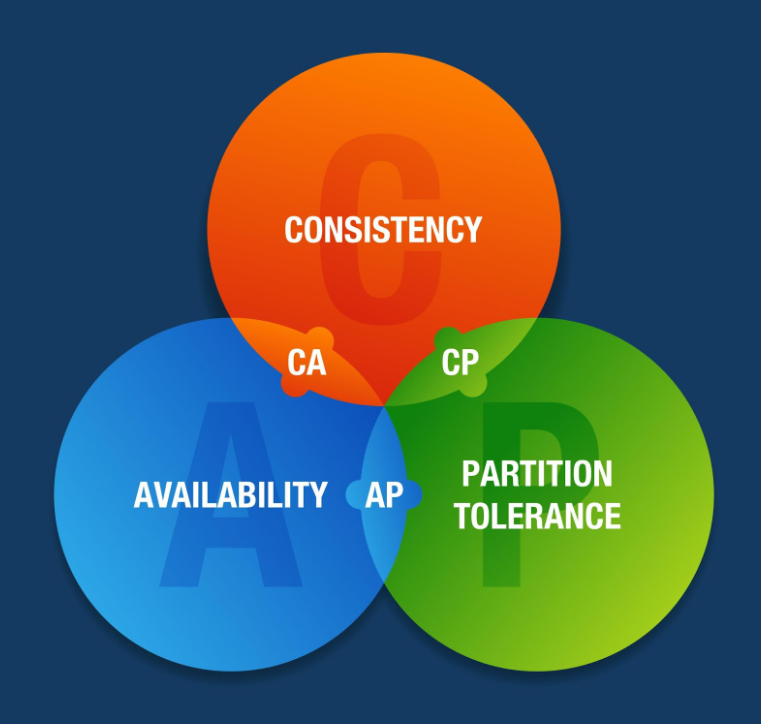
На практике мы всегда имеем P (сеть может упасть), поэтому выбираем между CP (надежность данных, но возможен отказ в доступе) и AP (система работает всегда, но данные могут запаздывать).
MPP (Massively Parallel Processing)
MPP (Массово-параллельная обработка) — это архитектура для скорости. Представьте, что вместо одного мощного «грузчика» (сервера), ваш запрос обрабатывают сто «грузчиков» поменьше.
Данные разбиты на куски и разложены по разным узлам. Когда приходит сложный запрос, каждый узел обрабатывает свой маленький кусочек параллельно с другими. Потом результаты просто склеиваются. Именно так аналитические базы перемалывают терабайты за секунды.
WORM (Write Once, Read Many)
WORM (Однократная Запись, Многократное Чтение) — это принцип «бухгалтерской книги» для данных или старых форматов записи DVD-R / CD-R.
Этот принцип критически важен для аналитики и логов. Он гласит, что данные после записи неизменяемы (immutable). В WORM-системах, таких как многие колоночные базы, это означает, что операции UPDATE и DELETE логически запрещены или значительно ограничены. Изменение данных происходит через запись новой версии (новый INSERT), а старые данные остаются для аудита.
Этот подход гарантирует, что история не будет повреждена (переписана). Это идеально для аудита и хранения логов.
Обзор 6-ти типов NoSQL

NoSQL — это не одна технология, а набор из шести разных семейств баз данных (разбиение чисто условное и меняется со временем). Каждое из них оптимизировано для своего круга задач.
Key-Value (Ключ-значение)
- Суть: Самый простой и быстрый формат. Данные лежат как в камере хранения: есть номерок (Ключ) и ячейка с содержимым (Значение).
- Где применяется: Там, где нужна максимальная скорость доступа по известному ключу. Это кэширование, корзины покупок, сессии пользователей.
- Примеры: Redis (Opensource-лидер), Apache ZooKeeper (для координации), YDB (можно использовать как высокодоступное KV-хранилище), Memcached.
- Ссылка: Базы данных «Ключ-значение»
Document (Документные)
- Суть: Хранение данных в виде иерархических документов (обычно JSON). Это позволяет хранить объект целиком в одном месте, а не размазывать его по десяти таблицам.
- Где применяется: Основное хранилище для веб-приложений. Управление контентом (CMS), каталоги товаров, профили.
- Примеры: MongoDB (Opensource-стандарт), YDB (поддерживает документную модель), Couchbase.
- Ссылка: Документные базы данных
Columnar (Колоночные)
- Суть: Данные хранятся не по строкам, а по столбцам. Это позволяет мгновенно читать один конкретный параметр из миллиарда записей, не считывая лишнюю информацию.
- Где применяется: Big Data аналитика (OLAP), обработка логов, Интернет вещей (IoT). Идеальны для сценариев WORM (неизменяемых данных).
- Примеры: ClickHouse (Opensource-лидер, созданный в Яндекс), Greenplum (классика MPP), Apache Cassandra (Opensource, AP-система), HBase.
- Ссылка: Колоночные базы данных
Graph (Графовые)
- Суть: База хранит не только объекты (Вершины), но и связи между ними (Ребра) как физическую часть данных. Это позволяет мгновенно «ходить» по связям.
- Где применяется: Социальные сети, рекомендательные системы, выявление мошеннических схем.
- Примеры: Neo4j (Opensource-лидер), YDB (позволяет строить графовые запросы поверх своих таблиц), Amazon Neptune.
- Ссылка: Графовые базы данных (Graph)
Search (Поисковые)
- Суть: Специализированные движки, которые строят Обратный индекс. Они знают, в каких документах встречается каждое конкретное слово.
- Где применяется: Полнотекстовый поиск на сайтах, глубокий анализ текстовых логов.
- Примеры: OpenSearch (Opensource-форк Elasticsearch), Apache Solr (Opensource), Elasticsearch.
- Ссылка: Поисковые базы данных (Search)
In-Memory (В оперативной памяти)
- Суть: Хранение данных прямо в оперативной памяти (RAM), без обращения к диску. Это убирает самую медленную часть процесса — работу с жестким диском.
- Где применяется: Сценарии реального времени. Биржевые торги, игровые таблицы лидеров, сверхбыстрый кэш.
- Примеры: Redis (Opensource-стандарт), Memcached, решения на базе YDB (использует In-Memory хранение для горячих данных).
- Ссылка: Базы данных In-Memory
Актуальные тренды 2025: NoSQL на «HypeCycle» Gartner
Анализ трендов, таких как Hype Cycle от Gartner, показывает, что концепция NoSQL не просто актуальна, она является основой для большинства новых архитектур, связанных с AI. Далее вы видите один из фрагментов NoSQL хранилищ популярных в 2025 году по версии консалтинговой компании Mattturck где вы видите уже появление других типов No SQL хранилищ которые завоевывают все большее влияние на рынке Data Storage

Вот ключевые тренды в управлении данными, на которые стоит обратить внимание в 2025 году.
- Lakehouse (Озеро-Хранилище). Эта архитектура, объединяющая лучшие черты озер данных и хранилищ данных, продолжает набирать обороты. Lakehouse, по оценке Gartner, имеет Трансформационный потенциал.
- Open Table Formats (Открытые табличные форматы). Форматы, такие как Apache Iceberg, являются ключом к Lakehouse-архитектуре. Они позволяют накладывать строгую метаструктуру поверх данных, хранящихся в гибком объектном хранилище.
- Data Products (Продукты данных). Тренд, который диктует необходимость создавать из данных не просто «отчеты», а многоразовые, сертифицированные, готовые к употреблению активы. Это напрямую влияет на то, как мы организуем данные в документных и колоночных NoSQL-базах.
- Векторные базы данных. Эти специализированные базы, используемые для Retrieval-Augmented Generation (RAG) и семантического поиска в AI, активно интегрируются в существующие NoSQL-системы.
Эти тенденции демонстрируют, что успех в мире Big Data и AI в 2025 году зависит от стратегического использования NoSQL-технологий.
Как выбрать правильную NoSQL-базу?
Универсальность — удел больше SQL систем. NoSQL — это всегда специализация. Выбор NoSQL-базы — это всегда выбор правильного узкоспециализированного инструмента для конкретного сценария.
Как практик, вы можете задать себе следующие вопросы, прежде чем принять решение.
- Какой у меня основной паттерн запросов? Если по ID — беру Key-Value или Columnar. Если по содержимому полей — Document. Если по тексту — Search. Если нужны сложные отчеты — Columnar. Read доминантные запросы или на Запись.
- Каковы требования к CRUD? Мне нужно часто обновлять и удалять (тогда нужен SQL или DocumentDB)? Или я работаю с неизменяемыми логами, где UPDATE/DELETE ограничены (тогда лучше WORM-база, Columnar)?
- Насколько важна согласованность (CAP)? Что важнее: чтобы система всегда была доступна (AP), или чтобы данные всегда были на 100% согласованы (CP)?
- Какой объем данных и скорость записи? Речь идет о гигабайтах или петабайтах? Мы пишем 100 раз в секунду или 100 000 раз в секунду (тогда смотрим на MPP-системы)?
Ответы на эти вопросы обычно сужают выбор до 2-3 вариантов.
Заключение: Эра «Polyglot Persistence»
NoSQL не «убил» SQL и не является его заменой. Он стал дополнением. Внедрение NoSQL привело нас к эре «Polyglot Persistence» («Многоязыкое хранение»).
Эта философия проста: «используй правильный инструмент для правильной работы». Современные сложные системы используют несколько типов баз данных одновременно.
Типичное современное приложение может использовать PostgreSQL (SQL) для хранения финансовых транзакций, MongoDB (Document) для профилей пользователей, Redis (In-Memory) для кэширования сессий и Elasticsearch (Search) для поисковой строки. NoSQL дал нам инструментарий для создания более гибких, отказоустойчивых и масштабируемых систем.
Практическая архитектура данных
Код курса
PRAR
Ближайшая дата курса
14 сентября, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Референсные ссылки
- Что такое NoSQL? (MongoDB) (https://www.mongodb.com/resources/basics/databases/nosql-explained)
- Теорема CAP простыми словами (IBM) (https://www.ibm.com/think/topics/cap-theorem)
- MPP Architecture (CData) (https://www.cdata.com/blog/massively-parallel-processing)
- Polyglot Persistence (Medium) (https://medium.com/@rachoork/polyglot-persistence-a-strategic-approach-to-modern-data-architecture-e2a4f957f50b)
- NoSQL Guide 2025 (Vinova) (https://vinova.sg/guide-to-nosql-databases-in-2025/)