 2342
2342 
Содержание
Apache Parquet — это бинарный, колоночно-ориентированный формат хранения больших данных, изначально созданный для экосистемы Hadoop, позволяющий использовать преимущества сжатого и эффективного колоночно-ориентированного представления информации. Паркет позволяет задавать схемы сжатия на уровне столбцов и добавлять новые кодировки по мере их появления [1]. Вместе с Apache Avro, Parquet является очень популярным форматом хранения файлов Big Data и часто используется в Kafka, Spark и Hadoop.
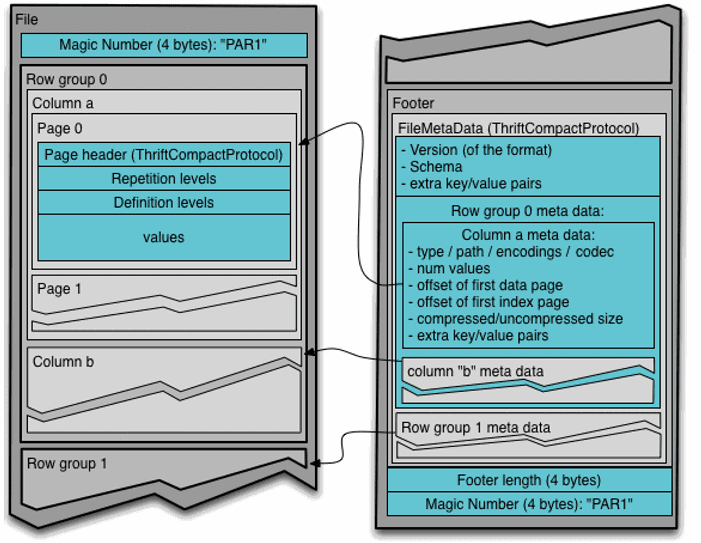
Структура файла Apache Parquet
Из-за архитектурных особенностей структура представления информации в Parquet сложнее, чем, например, в JSON, который также часто используется для Big Data. В частности, уровни определения (definition levels) и уровни повторения (repetition levels) позволяют оптимально хранить пустые значения и эффективно кодировать данные, информацию о схеме в метаданные [2].
Уровни определения определяют количество необязательных полей в пути для столбца. Уровни повторения указывают, для какого повторяемого поля в пути, значение имеет повторение. Максимальные уровни определения и повторения могут быть вычислены из схемы. Эта степень вложенности определяет максимальное количество битов, необходимых для хранения уровней. В свою очередь, уровни определены для всех значений в столбце [1].
Благодаря многоуровневой системе разбиения файлов на части реализуется параллельное исполнение важных Big Data операций (MapReduce, ввод-вывод, кодирование и сжатие) [2]:
- Row-group— логическое горизонтальное разбиение данных на строки для распараллеливания работы на уровне MapReduce. Не существует физической структуры, которая гарантирована для группы строк. Группа строк состоит из фрагмента столбца для каждого столбца в наборе данных.
- Column chunk— блок данных для столбца в определенной группе строк – разбиение для распределения операций ввода-вывода на уровне колонок, оптимизирует работу с жестким диском, записывая данные не по строкам, а по колонкам;
- Page— концептуально неделимая единица (с точки зрения сжатия и кодирования – разбиение колонок на страницы для распределения работ по кодированию и сжатию данных, например, с помощью кодеков snappy, gzip, lzo. Страницы содержат метаинформацию и закодированные данные.
Типы и представления данных в формате Паркет
Иерархически файл Parquet состоит из одной или нескольких групп строк. Группа строк содержит ровно один фрагмент столбца на столбец. Фрагменты столбцов содержат одну или несколько страниц.
Группы строк используются HDFS (распределенной файловой системой Apache Hadoop) для реализации концепции локальности данных, когда каждый узел кластера считывает лишь ту информацию, которая хранится непосредственно на его жестком диске.
В Apache Spark группа строк является единицей работы для каждой задачи MapReduce. При этом группа строк помещается в память, что следует учитывать при настройке размера группы – каков минимальный объём памяти, выделяемый на задачу на самом слабом узле кластера. Чтобы разбить входные данные на несколько row groups и эффективно распределить MapReduce-задачи по ресурсам кластера, можно использовать операцию разделения RDD-таблиц (Resilient Distributed Datasets) [2], которые являются объектами всех манипуляций с данными в Apache Spark – об этом мы рассказывали здесь.
Поскольку типы данных влияют на объем занимаемого пространства, их стремятся минимизировать при проектировании форматов файла. Например, 16-разрядные числа явно не поддерживаются в формате хранения, поскольку они покрыты 32-разрядными числами с эффективным кодированием. Благодаря такой стратегии снижается сложность реализации чтения и записи формата. Parquet поддерживает следующие типы данных [1]:
- BOOLEAN – 1-битный логический;
- INT32 – 32-битные подписанные числа;
- INT64 – 64-битные подписанные числа;
- INT96 – 96-битные подписанные числа;
- FLOAT – IEEE 32-битные значения с плавающей точкой;
- DOUBLE – IEEE 64-битные значения с плавающей точкой;
- BYTE_ARRAY – произвольно длинные байтовые массивы.
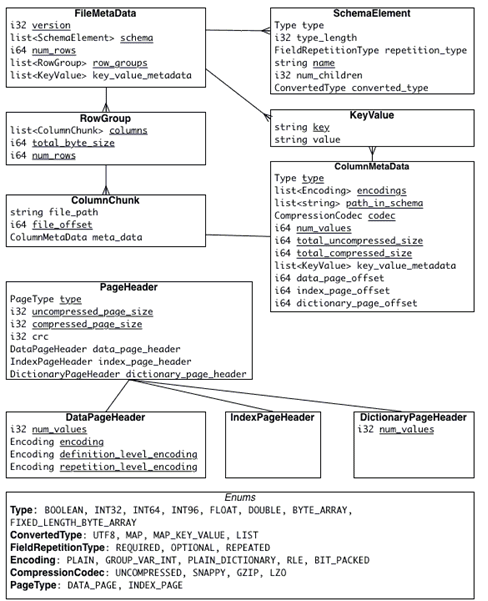
Метаданные файла Apache Parquet
Формат Parquet явно отделяет метаданные от данных, что позволяет разбивать столбцы на несколько файлов, а также иметь один файл метаданных, ссылающийся на несколько файлов паркета. Метаданные записываются после значащих данных, чтобы обеспечить однопроходную запись. Таким образом, сначала прочитаются метаданные файла, чтобы найти все нужные фрагменты столбцов, которые дальше будут прочтены последовательно [1].
При повреждении метаданных сам файл теряется – данное правило актуально также в случае столбцов и страниц [2]:
- при повреждении метаданных столбца, потеряется этот фрагмент столбца, но его фрагменты в других группах строк останутся неизменны;
- при повреждении заголовка страницы, остальные страницы в этом столбце также будут потеряны;
- если данные на странице повреждены, эта страница теряется.
Таким образом, файл с небольшими группами строк является более устойчивым к повреждению. Однако, в этом случае размещение метаданных в конце файла будет проблемой, т.к. при возникновении сбоя при записи метаданных, все записанные данные станут нечитаемыми. Это можно исправить, записав метаданные файла в каждую N-ю группу строк. Метаданные каждого файла будут включать все группы строк, написанные до сих пор. Комбинируя это с маркерами синхронизации, можно восстановить частично записанные файлы [1].
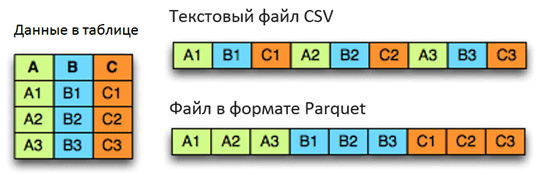
Сжатие, кодирование и отображение файлов Big Data в формате Parquet
В формате Parquet сжатие больших данных выполняется столбец за столбцом, что позволяет использовать разные схемы кодирования для текстовых и целочисленных данных, в т.ч. вновь изобретенные. Также, благодаря колоночной структуре, формат Parquet существенно ускоряет процесс работы с данными, поскольку можно считывать не весь файл, а лишь необходимые столбцы, т.к. на практике для аналитических задач в конкретный момент нужны лишь несколько колонок. Кроме того, такое структурирование информации упрощает сжатие и кодирование данных за счёт их однородности и похожести [2]. В связи с этим, по сравнению с Avro и JSON, другими популярными форматами Big Data, Паркет быстрее сохраняет и сжимает данные, а также занимает меньше дискового пространства [3].
Источники
- https://ru.bmstu.wiki/Apache_Parquet
- https://habr.com/ru/company/wrike/blog/279797/
- http://datareview.info/article/test-proizvoditelnosti-apache-parquet-protiv-apache-avro/