 1421
1421 Apache Storm (Сторм, Шторм) – это Big Data фреймворк с открытым исходным кодом для распределенных потоковых вычислений в реальном времени, разработанный на языке программирования Clojure.
Изначально созданный Натаном Марцем и командой из BackType, этот проект был открыт с помощью исходного кода, приобретенного Twitter. Первый релиз состоялся 17 сентября 2011 года, а с сентября 2014 Storm стал проектом верхнего уровня Apache Software Foundation [1].
Как устроен Apache Storm: архитектура и принцип работы
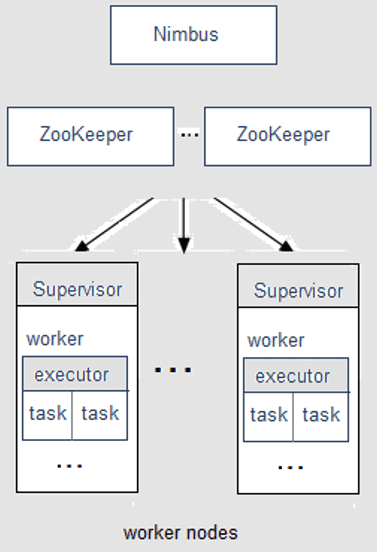
Кластер Apache Storm, работающий по принципу master-slave, состоит из следующих компонентов [1]:
- Ведущий узел (master) с запущенной системной службой (демоном) Nimbus, который назначает задачи машинам и отслеживает их производительность.
- Рабочие узлы (worker nodes), на каждом из которых запущен демон Supervisor (супервизор), который назначает задачи (task) другим рабочим узлам и управляет ими по необходимости.
Storm самостоятельно не отслеживает состояние кластера, поэтому для связи Nimbus с супервизорами и управления кластером используется служба ZooKeeper.
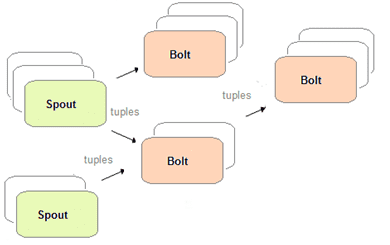
Топология вычислений реального времени в приложениях Storm представляет собой ориентированный ациклический графа (DAG, Directed Acyclic Graph). Узлами (вершинами) графа являются обработчики 2-х типов [2]:
- спаут (spout), который генерирует кортежи (tuple) – потоки данных в виде неизменяемых наборов пар ключ-значение;
- болт (bolt), который выполняет преобразование потока (подсчет, фильтрация, map, reduce и пр.) и передает данные другим болтам для последующей обработки.
Таким образом, поток представляет собой неограниченный конвейер кортежей, а Spout является источником потоков, который преобразует данные в кортеж потоков и отправляет их на обработку в Bolt. В итоге топология действует как конвейер преобразования данных. На поверхностном уровне общая структура топологии аналогична задаче MapReduce в Apache Hadoop, однако в Storm данные обрабатываются в режиме реального времени, а не в отдельных пакетах. Также, в отличие от классического Hadoop, топологии Storm работают неопределенно долго (пока не будут уничтожены), а DAG-задача MapReduce имеет ограниченный срок существования [1].
Преимущества и недостатки Сторм
Ключевыми достоинствами Apache Storm можно назвать следующие [3]:
- интеграция с любыми системами управления очередью и брокерами сообщений (Kestrel, RabbitMQ, Kafka, JMS, Amazon Kinesis), а также базами данных;
- масштабируемость – вычислительные топологии Storm изначально параллельны и предназначены для кластерной работы с технологиями Big Data. Различные части топологии можно масштабировать по отдельности, изменяя их параллелизм и регулируя параллельность запуска на лету;
- вычислительная мощность – благодаря распределенному параллелизму Сторм может обрабатывать очень большое количество сообщений с очень низкой задержкой;
- отказоустойчивость — когда фоновые задачи перестают работать, Storm автоматически перезапустит их на этом же узле кластера или на другом, в случае его сбоя. Фреймворк самостоятельно обрабатывает параллелелизм, разделение данных и повтор действий в случае ошибок.
- гарантия обработки данных – Сторм обеспечивает обработку каждого кортежа данных за счет семантики минимум однократной доставки (at least once) или в точности однократной доставки (exactly once) с использованием высокоуровневого API-интерфейса Trident;
- поддержка множества языков программирования — Storm использует Apache Thrift – язык описания интерфейсов, который используется для определения и создания служб под разные языки программирования, а также является фреймворком к удалённому вызову процедур. Благодаря этому можно создавать программные топологии на любом языке программирования: Java, Scala, Python, C#, Ruby и пр. [2];
- наличие собственной RPC-подсистемы – за счет инструмента распределенного удаленного вызова процедур Сторм позволяет выполнять кластерные вычисления по требованию, когда клиент синхронно ожидает результат [2];
- низкая задержка (latency) – Storm обеспечивает обработку потоковых данных в реальном времени с задержкой менее 1 секунды, показывая лучшие результаты по сравнению с Apache Spark, другим популярным Big Data фреймворком потоковой обработки;
- простота развертывания и поддержки – Шторм обладает стандартным набором конфигураций для развертывания кластера, а при работе с вычислительным облаком Amazon Elastic Compute Cloud (Amazon EC2), проект со Storm можно подготовить, настроить и установить с нуля нажатием одной кнопки.
При всех вышеуказанных достоинствах, Шторм отличается следующими недостатками [4]:
- отсутствие возможностей гибкой обработки событий в различных периодах, например, временные и сеансовые окна, как в Apache Kafka Streams и Flink;
- не поддерживает управление состоянием приложений (stateful);
- поддержка минимум однократной доставки сообщений (at least once).
Впрочем, последние 2 проблемы решаются с помощью высокоуровневого API-интерфейса Trident. Storm с помощью высокоуровневого API Trident сохраняет состояние в памяти и периодически отправляет его в удаленную базу данных (например, Cassandra), поэтому стоимость удаленного вызова базы данных амортизируется по нескольким обработанным кортежам. Поддерживая метаданные вместе с состоянием, Trident может достичь семантики обработки ровно один раз (exact only), что обеспечивает, например, корректность счетчиков событий, даже в случае сбоя кластерных узлов и перезапуска кортежей. Впрочем, при больших объемах состояния в каждом обработчике типа Bolt (более 100 КБ) этот подход становится неэффективен, поскольку возрастают потери производительности при вызовах базы данных для каждого обработанного кортежа. Однако, для простых случаев, например, отслеживание счетчиков и метрик (минимальных, максимальных и средних значений) Шторм с Trident вполне справятся [5].
А где используется Apache Storm и с какими другими Big Data системами потоковой обработки конкурирует этот фреймворк, мы рассказываем в отдельной статье.
Источники
- https://en.wikipedia.org/wiki/Storm_(event_processor)
- http://datareview.info/article/obrabotka-potokovyx-dannyx-storm-spark-i-samza/
- https://ru.bmstu.wiki/Apache_Storm
- https://medium.com/@chandanbaranwal/spark-streaming-vs-flink-vs-storm-vs-kafka-streams-vs-samza-choose-your-stream-processing-91ea3f04675b
- http://samza.apache.org/learn/documentation/0.7.0/comparisons/storm/