 1708
1708 
Содержание
Tarantool – open-source продукт российского происхождения, сервер приложений на языке Lua, интегрированный с резидентной NoSQL-СУБД, которая содержит все обрабатываемые данные и индексы в оперативной памяти, а также включает быстрый движок для работы с постоянным хранилищем (жесткие диски). Благодаря своим архитектурным особенностям, Тарантул позволяет быстро обрабатывать большие объемы данных, поэтому эта СУБД широко применяется в различных Big Data проектах [1].
История разработки и развития проекта Tarantool
Отметим наиболее значимые вехи развития проекта Tarantool [2]:
- 2008 год – отечественная компания Mail.ru Group начала разработку программного продукта для своих внутренних нужд и собственных сервисов;
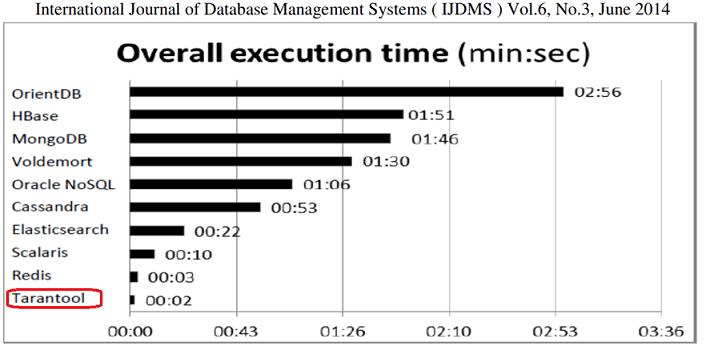
- 2014 год – участие системы в первом официальном независимом тесте на производительности NoSQL-СУБД, который проводили исследователи португальских университетов. Вместе с Tarantool также тестировались и другие популярные Big Data системы класса NoSQL: Cassandra, Apache HBase, MongoDB, Elasticsearch, Redis, Voldemort, Scalaris, Oracle NoSQL и Примечательно, что Tarantool показал наилучшие результаты в 4 из из 5 тестов на обработку 600 тысяч записей под нагрузкой, продемонстрировав свое главное преимущество – высочайшую скорость [3].
- 2014 год – Тарантул внедрен в сервисы соцсетей Badoo и Одноклассники;
- 2016 год – корпорация Mail.ru Group опубликовала исходный код Tarantool в открытом доступе под лицензией BSD;
- 2018 год – Tarantool используется в Мегафоне, Аэрофлоте и Альфа-банке;
- 2019 год – компания Arenadata, разработчик первого отечественного дистрибутива Apache Hadoop и других Big Data Решений, на основе Tarantool создала собственную платформу резидентных вычислений – Arenadata Grid [4].
Как устроен Tarantool: архитектура и принципы работ
Прежде всего отметим наиболее важные концепции Tarantool с точки зрения разработчика Big Data приложений [2]:
- поддержка SQL и документо-ориентированных запросов на скриптовом мультипарадигмальном языке Lua;
- поддержка ACID-транзакций (Atomicity, Consistency, Isolation, Durability – атомарность, согласованность, изоляция, стойкость);
- индексация по первичным ключам, с поддержкой неограниченного числа вторичных ключей и составными ключами в индексах;
- разделение доступа на основе ACL-модели (Access Control List);
- единый механизм упреждающей записив журнал (WAL, Write Ahead Log), который обеспечивает согласованность и сохранность данных в случае сбоя – изменения не считаются завершенными, пока не проходит запись в WAL;
- синхронная и асинхронная репликация локально и на удаленных серверах, когда сразу несколько узлов могут обрабатывать входящие данные и получать информацию от других узлов.
Основными программными компонентами Tarantool являются следующие [1]:
- JIT (Just In Time) Lua-компилятор – LuaJIT;
- Lua-библиотеки для самых распространенных приложений;
- сервер документоориентированной NoSQL-СУБД Tarantool с 2-мя движками – резидентным (In-memory, memtx), который хранит все данные в оперативной памяти, и дисковый (vinyl), который эффективно сохраняет данные на жесткий диск, используя разделение на диапазоны, журнально-структурированные деревья со слиянием (log-structured merge trees) и классические B-деревья.
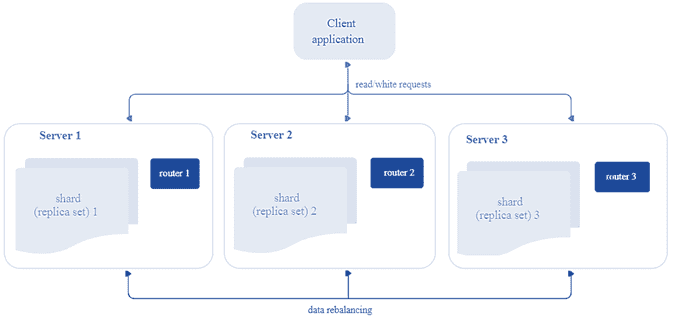
Перейдем к архитектуре: распределенный кластер Tarantool состоит из подкластеров, которые называются шарды (shard). Каждый шард хранит некоторую часть данных и представляет собой набор реплик, одна из которых является ведущим узлом, обрабатывающим все запросы на чтение и запись. При разделении (шардинге) данных они распределяются на заданное количество виртуальных сегментов с уникальными номерами. Рекомендуется задавать количество сегментов в 100-1000 раз больше, чем потенциальное число кластерных узлов с учетом масштабирования кластера в перспективе. Однако, слишком большое число сегментов может потребовать дополнительную память для хранения информации о маршрутизации, а слишком маленькое – привести к снижению степени детализации балансировки.
Итак, каждый шард хранит уникальное подмножество сегментов, причем один сегмент не может относиться к нескольким шардам одновременно. Таким образом, с архитектурной точки зрения сегментированный кластер Tarantool включает следующие компоненты [5]:
- хранилище (storage) – узел, который хранит подмножество набора данных. Несколько реплицируемых хранилищ составляют набор реплик (шард, shard). У каждого хранилища в наборе реплик есть роль: мастер или реплика. Мастер обрабатывает запросы на чтение и запись. Реплика обрабатывает запросы только на чтение.
- Роутер (router) – автономный компонент, который обеспечивает маршрутизацию запросов чтения и записи от клиентского приложения к шардам. В зависимости от функций приложения, роутер работает на его уровне или на уровне хранилища. Он сохраняет топологию сегментированного кластера прозрачной для приложения, скрывая такие детали, как номер и местоположение шардов, процесс балансировки данных, отказы реплики и восстановление после них. Роутер может сам идентифицировать сегмент, если приложение четко определяет правила вычисления идентификатора сегмента на основе запроса. Для этого роутеру необходимо знать схему данных. У роутера нет постоянного статуса, он не хранит топологию кластера и не выполняет балансировку данных. Роутер поддерживает постоянный пул соединений со всеми хранилищами, созданными при запуске, что помогает избежать ошибок конфигурации.
- Балансировщик – фоновый процесс равномерного распределения сегментов по шардам, во время которого выполняется миграция сегментов по наборам реплик. Балансировщик запускает периодически, перераспределяя данные из наиболее загруженных узлов в менее загруженные, когда предел дисбаланса в наборе реплик превышает показатель, указанный в конфигурации.
Основные сценария использования в Big Data и примеры внедрения
Благодаря высокой скорости обработки данных, типовыми сценариями применения Tarantool в Big Data считаются следующие:
- ускорение распределенных вычислений, в т.ч. на Apache Hadoop и Spark, а также выполнение аналитических SQL-запросов с большими данными в MPP-СУБД, таких как Arenadata DB на базе Greenplum;
- гибридная транзакционно-аналитическая обработка больших данных;
- оперативное кэширование для систем потоковой передачи и шин данных.
На практике это встречается в следующих бизнес-задачах:
- управление телекоммуникационным оборудованием;
- биржевые торги на финансовых рынках и аукционах интернет-рекламы;
- персонализированный маркетинг – формирование персональных маркетинговых предложений с привязкой ко времени и месту;
- игровые рейтинговые таблицы.
Также Tarantool может использоваться и в системах интернета вещей (Internet of Things, IoT), в т.ч. промышленного (Industrial IoT, IIoT). Tarantool IIoT поддерживает основные протоколы работы с датчиками (MQTT и MRAA), которые генерируют большие объемы данных для обработки в реальном времени. Еще эта версия Тарантул позволяет создавать скрипты для описания процессов получения показателей с промышленных устройств, их обработки, сохранения и передачи [6].
Подробнее про примеры использования Tarantool в реальных проектах мы рассказываем в отдельной статье.
Источники
- https://www.tarantool.io/ru/doc/2.3/intro/
- https://ru.wikipedia.org/wiki/Tarantool
- http://airccse.org/journal/ijdms/papers/6314ijdms01.pdf
- https://www.cnews.ru/news/line/2019-11-11_mailru_group_i_ibs_podpisali_soglashenie
- https://www.tarantool.io/ru/doc/2.2/reference/reference_rock/vshard/vshard_architecture/
- https://www.osp.ru/os/2017/02/13052224/