 1328
1328 
Проанализировав сходства и различия Apache Kafka Streams и Spark Streaming, можно сделать некоторые выводы относительно выбора того или иного решения в качестве основного инструмента потоковой обработки Big Data. В этой статье мы собрали для вас аргументы в пользу Кафка Стримс и Спарк Стриминг в конкретных ситуациях, а также нашли некоторые примеры их практического использования.
Когда стоит выбрать Apache Kafka Streams
Напомним, что Apache Kafka Streams – это клиентская библиотека для разработки распределенных потоковых приложений и микросервисов, в которых входные и выходные данные хранятся в кластерах Кафка. Кафка Стримс будет отличным инструментом потоковой обработки информации в следующих случаях:
- если источники входных и выходных данных находятся только в кластере Кафка, без подключения к сторонним Big Data системам [1];
- когда необходим быстрый запуск микросервисной Big Data платформы, которая будет обслуживать изолированные потоковые бизнес-приложения согласно DevOps-подходу [2];
- требуется «горячее» масштабирование (в режиме эксплуатации кластера) – именно Apache Kafka считается наиболее масштабируемой среди Big Data систем, а, как было отмечено выше, ее библиотека Кафка Стримс позволяет быстро разрабатывать, разворачивать и эксплуатировать распределенные потоковые приложения как обыкновенные Java-подобные программы, без использования дополнительных development-, test- и production-кластеров [3];
- нужно обеспечить транзакционный механизм потоковой обработки со сложной логикой исполнения, например, в случае ETL-систем [2];
- необходимо обрабатывать большие данные «на лету» – ключевым преимуществом Kafka Streams перед Spark Streaming является время задержки (latency). Кафка Стримс позволяет обрабатывать информационные потоки в режиме реального времени (с задержкой не более 1 миллисекунды), тогда как Спарк Стриминг допускает задержку в несколько секунд (в зависимости от размера пакета), что может быть критично для некоторых бизнес-задач, например, в случае биржевых транзакций [3].
Также стоит отметить, что Apache Kafka Streams, благодаря непрерывному режиму работы с потоками Big Data, в отличие от микропакетного подхода Spark Streaming, потребляет меньше оперативной памяти для stateless-задач [2]. При этом автоматическая генерация внутренних хранилищ для stateful-приложений в топиках Кафка может привести к увеличению объема обрабатываемых данных, немного снизив скорость работы. Однако, несмотря на эти потенциальные недостатки, если требуется выполнить простое преобразование топиков Kafka, подсчитать сообщения по ключам, обогатить поток данными из другого топика, выполнить агрегацию или только потоковую обработку Big Data в реальном времени, то Кафка Стримс превосходно справится со всеми этими задачами [1].
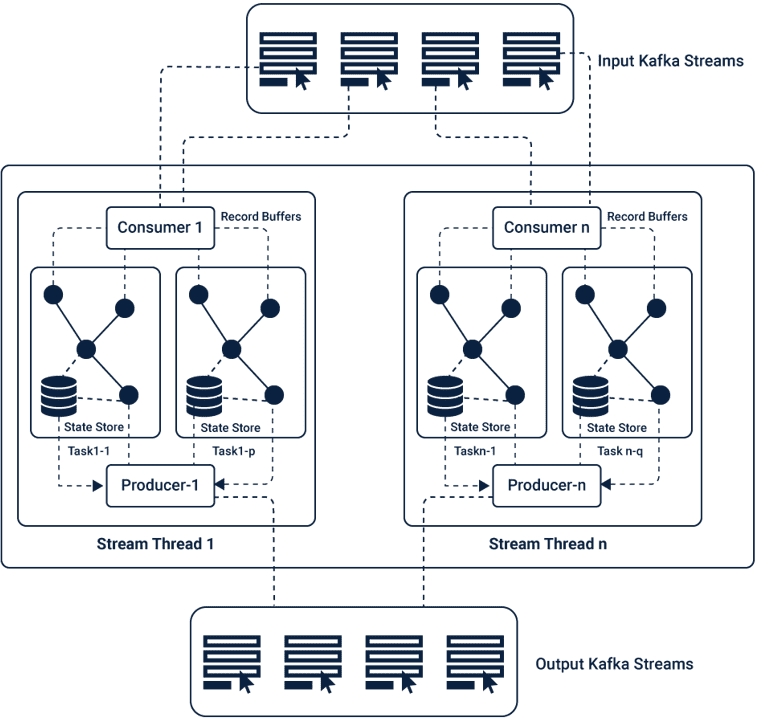
Аргументы в пользу Spark Streaming
Spark Streaming – это компонент фреймворка Apache Spark для распределённой обработки неструктурированных и слабоструктурированных потоковых данных. Его целесообразно выбирать в следующих условиях:
- требуется поддержка Лямбда-архитектуры (Lambda Architecture) – универсального подхода, направленного на применение произвольной функции к произвольному набору данных с минимальным период ожидания возвращения искомого значения [4]. При этом сочетание пакетной обработки данных по расписанию и в режиме онлайн [5] обеспечивается широким набором интеграции Apache Spark с различными Big Data системами и хранилищами данных (Hadoop HDFS, OpenStack Swift, NoSQL-СУБД Cassandra, HBase, Hive, Amazon S3 и т.д.) [3];
- есть необходимость использования других компонентов Apache Spark – GraphX, MLlib, Spark SQL, например, для графовых операций, машинного обучения или SQL-аналитики [6];
- необходимо разрабатывать распределенные stateful-приложения на языке Python и обрабатывать большие данные с использованием языка R – Спарк Стриминг позволяет делать это с помощью своего мощного API и DSL [6], тогда как Кафка Стримс поддерживает только Java и Scala [1];
- отсутствуют жесткие требования к минимальной задержке в обработке данных, т.е. latency в несколько секунд не является критичной для распределенного приложения [1].
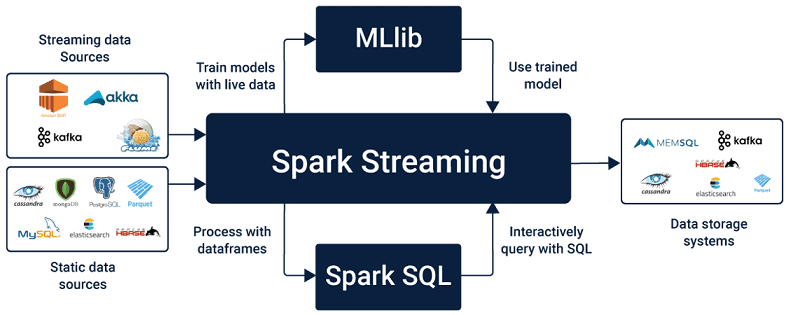
Итак, выбор оптимального варианта зависит от конкретных условий. Также стоит помнить, что Apache Kafka Streams и Spark Streaming – это не единственные средства обработки информационных потоков Big Data. Существует еще множество альтернатив, например, Apache Flink, Storm, Samza, о которых мы расскажем отдельно. В частности, здесь мы сравнили Flink и Spark, тут — рассказали про примеры практического использования Apache Storm, а в этой статье — про Apache Samza. А про сходства и различия Apache Kafka Streams, Spark Streaming, Flink, Storm и Samza мы говорим в этом материале.
Как обрабатывать потоки больших данных «на лету» с помощью Apache Kafka Streams и Spark Streaming, узнайте на наших специализированных курсах для руководителей, архитекторов, инженеров, администраторов, аналитиков Big Data и Data Scientist’ов в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
Источники
- https://dzone.com/articles/spark-streaming-vs-kafka-stream-1
- https://meritis.fr/bigdata/spark-streaming-or-kafka-streaming-deep-dive-in-a-hard-choice/
- https://www.cuelogic.com/blog/analyzing-data-streaming-using-spark-vs-kafka
- http://datareview.info/article/lyambda-arhitektura-novyiy-podhod-k-analizu-dannyih/
- https://habr.com/ru/post/279491/
- http://datareview.info/article/obrabotka-potokovyx-dannyx-storm-spark-i-samza/

