
Представьте, что вы работаете в e-commerce. У вас есть 50 таблиц в Postgres (заказы, товары, пользователи, отзывы...), и каждую из них нужно переливать в ClickHouse по одной и той же схеме: Скачать -> Очистить -> Загрузить. Новичок создаст 50 файлов: dag_orders.py, dag_users.py, dag_items.py... В каждом файле будет одинаковый код,...

Если Postgres - это надежный банковский сейф, где каждая транзакция на вес золота, то ClickHouse - это промышленная мясорубка. Ему все равно, уникальны ли ваши записи (по умолчанию), он не поддерживает классические транзакции, но зато он умеет делать SELECT count(*) FROM hits по миллиарду строк за доли секунды. Для...

Установка Claude Code на Ubuntu 24.04 — процесс довольно прямолинейный, но требующий аккуратности с версиями Node.js и правами доступа. Как «самоучка», я рекомендую использовать официальный скрипт установки или NPM, но без использования sudo для самого пакета, чтобы избежать проблем с правами в будущем. Claude Code - это специализированный CLI-инструмент от...

До этого момента все наши DAG-и жили по расписанию. schedule_interval='@daily' - это классика. Но современный бизнес не хочет ждать "утреннего отчета". Если данные прилетели в 14:00, отчет должен быть готов в 14:10, а не на следующее утро. Здесь мы сталкиваемся с фундаментальным конфликтом: Airflow - это Batch-инструмент (запускает задачи...

В прошлых статьях мы выяснили: если задача тяжелая и требует Java (Spark), мы используем SparkSubmitOperator. Но что делать, если у вас "тяжелый" Python? Типичная ситуация когда вы написали отличный код на Pandas внутри PythonOperator. На тестовом файле в 100 Мб все летало. В продакшене пришел файл на 10 Гб. Как...

Мы построили пайплайн, где данные забираются из базы и бережно складываются в HDFS. Теперь они лежат там мертвым грузом. Чтобы превратить сырые CSV в полезные отчеты, их нужно обработать: отфильтровать, агрегировать, джойнить. Делать это внутри самого Airflow (через PythonOperator и Pandas) - плохая идея если: Память: Если файл весит...

В мире Big Data технологии меняются с бешеной скоростью, но слон (Hadoop) все еще в комнате. Несмотря на популярность облачных S3-хранилищ, распределенная файловая система HDFS остается стандартом де-факто для многих корпоративных хранилищ Data Lake и on-premise кластеров. Даже если вы не пишете MapReduce-задачи на Java, ваш Airflow, скорее всего,...

В прошлой статье мы научили Airflow работать со структурированными данными в Postgres. Но в мире Big Data базы данных - это лишь верхушка айсберга. Основная масса данных (логи, картинки, JSON-выгрузки, бэкапы) хранится в виде файлов. Хранить эти файлы на локальном диске сервера, где крутится Airflow - плохая идея. Диск не...

Оркестратор сам по себе бесполезен. Apache Airflow - это дирижер, а не музыкант. Его задача - не хранить данные и не (всегда) обрабатывать их, а говорить другим системам, что делать. "Postgres, выполни этот запрос", "Spark, посчитай эту витрину", "S3, отдай файл". Но чтобы сказать "Postgres, выполни запрос", Airflow должен...

Эта статья открывает наш цикл посвященный бесплатному курсу лекций по "Apache Airflow для новичков" и закладывает фундамент для осовения всей темы. Мы разберемся, зачем вообще нужен оркестратор, как Airflow устроен внутри и как его запустить за пять минут, чтобы начать первые эксперименты. Архитектура и философия: почему Apache Airflow...

Зачем в Apache AirFlow 3.0 добавлена поддержка Go и как работает этот экспериментальный SDK: возможности и ограничения разработки и запуска задач на компилируемом языке программирования. Мультиязычность в Apache AirFlow 3.0 Одной из ключевых новинок недавно выпущенного Apache AirFlow 3.0, о котором мы писали здесь, стала его мультиязычность. Теперь фреймворк поддерживает...

22 апреля 2025 вышел долгожданный крупный релиз Apache Airflow. Знакомимся с главными новинками версии 3.0: изменения архитектуры и пользовательского интерфейса для повышения устойчивости и безопасности фреймворка. Еще раз про версионирование DAG в Apache AirFlow 3.0 Недавно мы писали про бета-релиз Apache AirFlow 3.0. Теперь мажорная версия вышла официально и доступна...

Как LLM упрощают работу дата-инженера: новые декораторы TaskFlow API в Apache Airflow для внедрения больших языковых моделей в DAG. Обзор Airflow AI SDK на основе Pydantic AI с практическим примером про анализ отзывов. ИИ в инженерии данных Мультимодальность современных инструментов машинного обучения, когда одна ML-модель может принимать на вход данные...

Изоляция рабочих процессов и универсальное выполнение на удаленных машинах в обновленной клиент-серверной архитектуре, версионирование DAG, активы данных и изменения интерфейсов: главные новинки Apache AirFlow 3.0. Изоляция рабочих процессов и универсальное выполнение В марте 2025 года ожидается выпуск бета-релиза Apache AirFlow, а общедоступная версия (GA) выйдет в середине апреля. До этого...
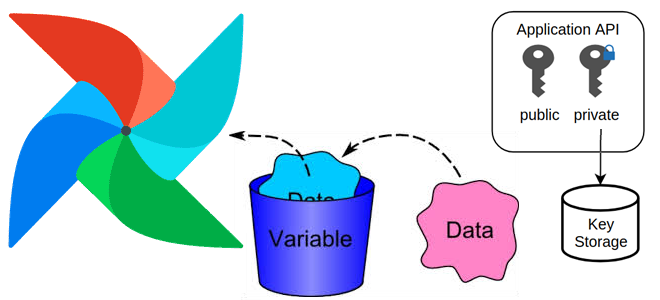
Зачем нужны переменные в Apache AirFlow, какие они бывают, как создать переменную и использовать ее: примеры и рекомендации для эффективной дата-инженерии. Зачем нужны переменные в Apache AirFlow, и какие они бывают Чтобы хранить информацию, которая редко меняется, например, ключи API, пути к конфигурационным файлам, в Apache Airflow используются переменные. Переменные...

Как работает исполнитель Celery в Apache AirFlow, зачем ему очередь сообщений и каким образом это помогает масштабировать параллельное выполнение задач. Как работает исполнитель Celery в Apache AirFlow Именно исполнитель (Executor) в Apache Airflow отвечает за выполнение задач в рабочих процессах, определяя их локацию и последовательность, а также использование ресурсов. Хотя...

Чем BranchPythonOperator отличается от ShortCircuitOperator, что и когда выбирать для ветвления DAG в Apache Airflow: принципы работы и примеры использования. Ветвления DAG в Apache AirFlow с помощью операторов Чтобы поддерживать реализацию сложных конвейеров обработки данных, в Apache Airflow есть соответствующие механизмы ветвления графа задач, т.е. DAG (Directed Acyclic Graph). По...

Что такое Python-декораторы в Airflow, зачем они нужны, какие они бывают и чем полезны: ликбез по TaskFlow API на практическом примере DAG. Что такое Python-декораторы в Airflow и какие они бывают Будучи написанным на Python, Apache Airflow использует именно этот язык в качестве средства разработки дата-конвейеров. После определения функции в...

Чем обмен данными через XCom отличается от использования Dataset и какой из механизмов выбирать для обмена данными между задачами Apache Airflow: разбираем на практическом примере. Обмен данными через XCom В Apache Airflow есть несколько механизмов для обмена данными между задачами: XCom и набор данных (Dataset). При общей цели они предназначены...

Как разработать свой плагин Apache AirFlow: пошаговое руководство с наглядной демонстрацией. Добавляем свои пункты меню в веб-интерфейс фреймворка и встраиваем пользовательскую HTML-страницу с новым эскизом Flask. Разработка своего плагина для AirFlow Вчера я рассказывала, как расширить функциональные возможности Apache AirFlow с помощью плагинов. Сегодня рассмотрим, как это сделать на практике....