 98
98
Содержание
Большие данные (Big Data) – совокупность непрерывно увеличивающихся объемов информации одного контекста, но разных форматов представления, а также методов и средств для эффективной и быстрой обработки [1].
Big Data: какие данные считаются большими
Благодаря экспоненциальному росту возможностей вычислительной техники, описанному в законе Мура [2], объем данных не может являться точным критерием того, являются ли они большими. Например, сегодня большие данные измеряются в терабайтах, а завтра – в петабайтах. Поэтому главной характеристикой Big Data является степень их структурированности и вариантов представления.
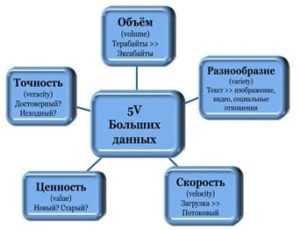
Яркая иллюстрация больших данных – это непрерывно поступающая информация с датчиков или устройств аудио- и видеорегистрации, потоки сообщений из соцсетей, метеорологические данные, координаты геолокации абонентов сотовой связи и т.п. [3]. Например, вот здесь мы рассказывали, как ПАО «Газпромнефть» собирал и анализировал более 200 миллионов разновариантных записей с контроллеров систем управления на нефтяных скважинах, записи рестартов напряжения из аварийных журналов, особенности эксплуатации насосов и характеристики скважинных условий для формирования и проверки гипотез о причинах сбоев и выявления ранее неизвестных взаимосвязей в работе насосного оборудования [4].
Таким образом, источниками больших данных могут быть [5]:
- интернет — соцсети, блоги, СМИ, форумы, сайты, интернет вещей (Internet of Things, IoT);
- корпоративная информация – транзакции, архивы, базы данных и файловые хранилища;
- показания приборов — датчиков, сенсоров, регистраторов и пр.
Этапы работы с Big Data
Чтобы получить рабочую гипотезу о причинах возникновения конкретных ситуаций, в частности, как связаны отказы оборудования с условиями подачи напряжения, или спрогнозировать будущее, например, вероятность своевременного возврата кредита частным заемщиком, анализ больших объемов структурированной и неструктурированной информации выполняется в несколько этапов [6]:
- чистка данных (data cleaning) – поиск и исправление ошибок в первичном наборе информации, например, ошибки ручного ввода (опечатки), некорректные значения с измерительных приборов из-за кратковременных сбоев и т.д.;
- генерация предикторов (feature engineering) – переменных для построения аналитических моделей, например, образование, стаж работы, пол и возраст потенциального заемщика;
- построение и обучение аналитической модели (model selection) для предсказания целевой (таргетной) переменной. Так проверяются гипотезы о зависимости таргетной переменной от предикторов. Например, сколько дней составляет просрочка по кредиту для заемщика со средним образованием и стажем работы менее 3-х месяцев.
Методы и средства работы с Big Data
К основным методам сбора и анализа больших данных относят следующие:
- Data Mining – обучение ассоциативным правилам, классификация, кластерный и регрессионный анализ;
- краудсорсинг — категоризация и обогащение данных народными силами, т.е. с добровольной помощью сторонних лиц;
- смешение и интеграция разнородных данных, таких как, цифровая обработка сигналов и обработка естественного языка;
- машинное обучение (Machine Learning), включая искусственные нейронные сети, сетевой анализ, методы оптимизации и генетические алгоритмы;
- распознавание образов;
- прогнозная аналитика;
- имитационное моделирование;
- пространственный и статистический анализ;
- визуализация аналитических данных — рисунки, графики, диаграммы, таблицы.

Программно-аппаратные средства работы с Big Data предусматривают масштабируемость, параллельные вычисления и распределенность, т.к. непрерывное увеличение объема – это одна из главных характеристик больших данных. К основным технологиям относят нереляционные базы данных (NoSQL), модель обработки информации MapReduce, компоненты кластерной экосистемы Hadoop, языки программирования R и Python, а также специализированные продукты Apache (Spark, AirFlow, Kafka, HBase и др.) [3]. Все это и многое другое мы рассматриваем на наших практических курсах для аналитиков, инженеров и администраторов по работе с большими данными.
Хотите в совершенстве освоить теорию и практику Big Data, чтобы стать высококлассным специалистом и эффективно решать прикладные задачи повышения эффективности любого бизнеса: от нефтегазовой промышленности до кредитного скоринга? Тогда выбирайте свою образовательную программу и до встречи на занятиях!
Источники
- https://habr.com/ru/company/dca/blog/267361/
- https://ru.wikipedia.org/wiki/Закон_Мура
- https://ru.wikipedia.org/wiki/Большие_данные
- https://bigdataschool.ru/blog/machine-learning-в-нефтегазовой-отрасли/
- https://www.uplab.ru/blog/big-data-technologies/
- https://rb.ru/story/dscientist-fscorelab/