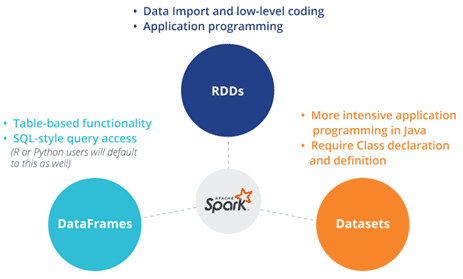
Продолжая говорить о сходствах и отличиях структур данных Apache Spark, сегодня мы рассмотрим, чем похожи датафрейм (DataFrame), датасет (DataSet) и RDD с позиции разработчика Big Data. Читайте в нашей статье, как обеспечивается оптимизация кода, безопасность типов при компиляции и прочие аспекты, важные при разработке распределенных программ и интерактивной аналитике больших данных с помощью Spark SQL.
Сравнение RDD, DataFrame и DataSet с позиции разработчика Big Data
Прежде всего перечислим, какие именно аспекты разработки программного обеспечения мы будем учитывать при сравнении структур данных Apache Spark:
- поддерживаемые языки программирования;
- безопасность типов при компиляции;
- оптимизация;
- сборка мусора (Garbage Collection);
- неизменность (Immutability) и совместимость (Interoperability).
Начнем с языков программирования: API-интерфейсы RDD и DataFrame доступны в Java, Scala, Python и R. А Dataset API поддерживается только в Scala and Java. Apache Spark 2.1.1 не поддерживает Python и R. Также рассматриваемые структуры данных Apache Spark существенно отличаются друг от друга в плане безопасности типов при компиляции [1]:
- RDD реализует объектно-ориентированный стиль программирования с безопасностью типов во время компиляции.
- DataFrame не позволит заранее (до компиляции) обнаружить ошибку в коде. Например, если пытаться получить доступ к столбцу, которого нет в таблице, ошибка возникнет только во время выполнения программы.
- DataSet обеспечивает безопасность типов во время компиляции.
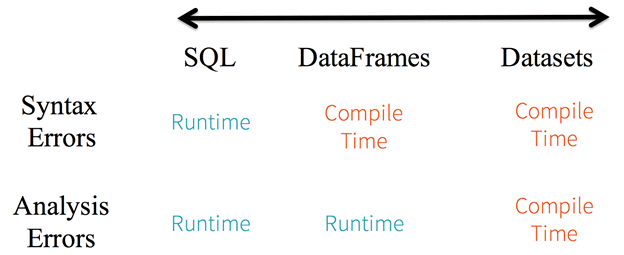
Рассматривая статическую типизацию и безопасность во время выполнения (Run Time) и во время компиляции (Compile Time), можно к сравнению DataSet и DataFrame также добавить SQL-запрос. Например, в строковых SQL-запросах Spark не сообщит о синтаксической ошибке до времени выполнения, тогда как в DataFrame и Dataset можно отловить их во время компиляции, что существенно экономит время разработчика Big Data. В частности, при вызове функции в DataFrame, которая не является частью API, компилятор ее перехватит. Однако, как мы отметили раньше, он не обнаружит несуществующее имя столбца до выполнения программы [2].
Благодаря строгой типизации DataSet, когда данные представлены как типизированные JVM-объекты, а API-процедуры выражаются как лямбда-функции, любое несоответствие типов будет обнаружено во время компиляции. Помимо синтаксических ошибок, DataSet API может обнаружить аналитическую ошибку во время компиляции, например, дублирование функций, что также облегчает работу программиста, экономя его время. Таким образом, DataSet за счет своих строгих ограничений повышает продуктивность разработчика, не позволяя тому совершать некоторые типичные ошибки [2].
Как поддерживается оптимизация, неизменность и совместимость структур данных Apache Spark
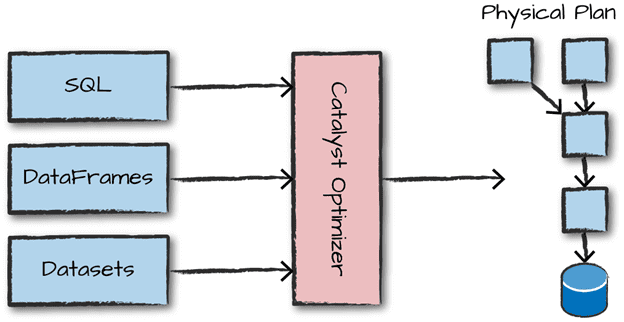
Встроенный механизм оптимизации недоступен в RDD, поэтому при работе со структурированными данными API распределенных коллекций не могут использовать преимущества оптимизаторов Apache Spark (CataLyst и Tungsten). Разработчик Big Data оптимизирует каждый RDD на основе его атрибутов. В DataFrame оптимизация кода выполняется с помощью оптимизатора CataLyst в 4 этапа:
- анализ логического плана для разрешения ссылок;
- оптимизация логического плана;
- физическое планирование;
- генерация кода для компиляции частей запроса в байт-код Java.
DataSet включает в себя концепцию оптимизатора Catalyst для оптимизации плана запросов. Подробнее об SQL-оптимизаторе Catalyst мы рассказываем здесь.
С точки зрения неизменности (Immutability) и совместимости (Interoperability) данных рассматриваемые структуры данных Apache Spark также ведут себя по-разному [1]:
- RDD содержит коллекцию записей, которые разбиты на разделы (partition) – базовые единицы параллелизма. Каждый раздел представляет собой одно логическое разделение данных, которое является неизменным и создается путем преобразования существующих разделов. Неизменность помогает добиться согласованности в вычислениях. Например, можно перейти от RDD к DataFrame, если RDD в табличном формате с помощью метода toDF() или наоборот, используя метод .rdd.
- После преобразования в DataFrame невозможно восстановить исходный объект. Например, сгенерировав датафрейм из RDD, нельзя восстановить исходную распределенную коллекцию данных.
- DataSet преодолевает ограничение DataFrame для восстановления RDD из Dataframe, позволяя конвертировать существующие RDD и датафреймы в датасеты.
Наконец, поговорим о сборке мусора (Garbage Collection) Для автоматического управления памятью за счет удаления неиспользуемых объектов [3]. В RDD накладные расходы на сборку мусора возникают в результате создания и уничтожения отдельных объектов. DataFrame позволяет избежать затрат на сборку мусора при создании отдельных объектов для каждой строки в наборе данных. При работе с DataSet автоматическому сборщику мусора также не нужно уничтожать объект, потому что сериализация проходит с помощью инструмента Tungsten, который явно управляет памятью и динамически генерирует байт-код для оценки выражений [4]. Благодаря динамической генерации байт-кода с сериализованными данными можно выполнить много операций, не требуя десериализации всего объекта [1].
В каком именно случае стоит выбирать между RDD, DataFrame и DataSet и почему, читайте в нашей следующей статье – реальные примеры (use cases). А как работать со всеми этим структурами больших данных на практике вы узнаете в нашем прикладном курсе SPARK2: Анализ данных с Apache Spark в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве.
Источники
- https://data-flair.training/blog/apache-spark-rdd-vs-DataFrame-vs-DataSet/
- https://databricks.com/blog/2016/07/14/a-tale-of-three-apache-spark-apis-rdds-DataFrames-and-DataSets/
- https://ru.wikipedia.org/wiki/Сборка_мусора
- https://databricks.com/glossary/tungsten

