Разграничение доступа на основе атрибутов (Attribute-Based Access Control, ABAC) — модель контроля доступа к объектам, основанная на анализе правил для атрибутов объектов или субъектов, возможных операций с ними и окружения, соответствующего запросу. Системы управления доступом на основе атрибутов обеспечивают мандатное и избирательное управление доступом. Рассматриваемый вид разграничения доступа дает возможность создать огромное количество комбинаций условий...

Agentic AI (агентный искусственный интеллект) — это тип искусственного интеллекта, который способен самостоятельно действовать, принимать решения и выполнять задачи без постоянных указаний человека. В отличие от традиционных ИИ-моделей, которые требуют четких инструкций, Agentic AI действует проактивно. Он ставит перед собой промежуточные цели для достижения конечного результата. Эта способность делает его...

Agile – набор методов и практик для гибкого управления проектами в разных прикладных областях, от разработки ПО до реализации маркетинговых стратегий, с целью повышения скорости создания готовых продуктов и минимизации рисков за счет итерационного выполнения, интерактивного взаимодействия членов команды и быстрой реакцией на изменения. История зарождения Agile Изначально термин Agile...
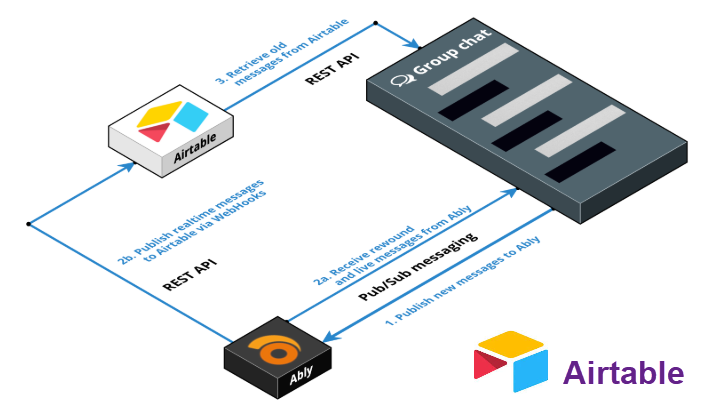
Airtable — это облачная low-code платформа для создания и совместного использования реляционных баз данных. Ключевая особенность Airtable заключается в его уникальном гибридном подходе: он предлагает простой, интуитивно понятный и визуально привлекательный интерфейс, похожий на электронные таблицы (spreadsheets), но под этим дружелюбным фасадом скрывается мощная функциональность настоящей базы данных. Это...

Apache Airflow — это открытая платформа для программного создания, планирования и мониторинга рабочих процессов. Изначально созданная в стенах Airbnb, она быстро эволюционировала в индустриальный стандарт для оркестровки сложных конвейеров данных. Важно сразу провести черту: Apache Airflow не обрабатывает данные самостоятельно, как Apache Spark, а выступает в роли «дирижёра»...

Apache Flink – это распределенная отказоустойчивая платформа обработки информации с открытым исходным кодом, используемая в высоконагруженных Big Data приложениях для анализа данных, хранящихся в кластерах Hadoop. Разработанный в 2010 году в Техническом университете Берлина в качестве альтернативы Hadoop MapReduce для распределенных вычислений больших наборов данных, Flink использует подход ориентированного...

Hbase - это нереляционная распределенная система управления базами данных (СУБД) с открытым исходным кодом, написанная на языке Java. Hbase является проектом экосистемы Hadoop и работает поверх распределенной файловой системы HDFS (Hadoop Distributed File System) [1].

Hive – это система управления базами данных (СУБД) в рамках платформы Hadoop для хранения и обработки больших данных в распределенной среде. Хайв позволяет проектировать структуры Big Data (таблицы, партиции, бакеты) с помощью SQL-подобного языка, называемого HiveQL.

Apache Hudi (Hadoop Upserts Deletes and Incrementals) — это открытый формат таблиц и платформа для управления данными в озере данных (Data Lake), которая предоставляет возможности потоковой обработки непосредственно поверх пакетных данных. Основная функция Hudi заключается в обеспечении атомарных операций вставки, обновления (upsert) и удаления данных на уровне отдельных...

Apache Iceberg - это открытый формат таблиц для огромных аналитических наборов данных в озерах данных (Data Lake). По своей сути, Apache Iceberg не является ни системой хранения, ни движком для обработки запросов; это спецификация, которая определяет, как организовать файлы данных (например, Parquet, Avro, ORC) и метаданные, чтобы обеспечить функциональность, присущую...
Apache Kafka – это высокопроизводительная распределенная потоковая платформа с открытым исходным кодом, разработанная изначально в LinkedIn, которая позволяет приложениям публиковать, подписываться, хранить и обрабатывать потоки записей в реальном времени, обеспечивая при этом высокую пропускную способность, масштабируемость и отказоустойчивость для широкого круга сценариев использования, включая обработку больших данных и микросервисные архитектуры....

Apache Ozone S3 — это распределенное, масштабируемое и согласованное хранилище объектов, созданное для экосистемы Apache Hadoop. Оно спроектировано для решения фундаментальных проблем масштабируемости HDFS (Hadoop Distributed File System), в первую очередь связанных с ограничением на количество файлов из-за метаданных, хранящихся в памяти NameNode. В отличие от HDFS, которое является...

Apache Spark – это Big Data фреймворк с открытым исходным кодом для распределённой пакетной и потоковой обработки неструктурированных и слабоструктурированных данных, входящий в экосистему проектов Hadoop [1]. История появления Спарк и сравнение с Apache Hadoop Основным автором Apache Spark считается Матей Захария (Matei Zaharia), румынско-канадский учёный в области информатики....
Apache Superset — это современная платформа для исследования и визуализации данных. Изначально ее создали в компании Airbnb. Впоследствии, проект стал частью Apache Software Foundation. По сути, Superset помогает создавать интерактивные дашборды. Он также предоставляет мощные инструменты для анализа данных. Основные функциональные возможности Apache SuperSet Кстати, Superset предлагает пользователям множество полезных...

Группа Arenadata — ведущий российский разработчик ПО и лидер по количеству коммерческих внедрений на рынке систем управления и обработки данных. Группа представлена во всех ключевых нишах рынка и занимает лидирующие позиции в большинстве продуктовых категорий. Эксперты Arenadata вносят существенный вклад в развитие глобальных Open Source проектов. Arenadata среди мирового сообщества...

Autonomous Prompting (Автономный Промптинг) — это продвинутая методология взаимодействия с ИИ, при которой система (или "агент") способна самостоятельно генерировать, выполнять и итерировать последовательность запросов (промптов) для достижения сложной, высокоуровневой цели, поставленной человеком. Вместо того чтобы пассивно ждать от пользователя следующей точной команды, модель ИИ сама инициирует запросы, разбивает...

Avro – это линейно-ориентированный (строчный) формат хранения файлов Big Data, активно применяемый в экосистеме Apache Hadoop и широко используемый в качестве платформы сериализации. Как устроен формат Avro для файлов Big Data: структура и принцип работы Avro сохраняет схему в независимом от реализации текстовом формате JSON (JavaScript Object Notation), что облегчает...
Big Data (Большие данные) Big Data - данные большого объема, высокой скорости накопления или изменения и/или разновариантные информационные активы, которые требуют экономически эффективных, инновационных формы обработки данных, которые позволяют получить расширенное понимание информации, способствующее принятию решений и автоматизации процессов. Для каждой организации или компании существует предел объема данных (Volume) которые...

Bloom filter ( Фильтр Блума) - это высокоэффективная вероятностная структура данных. Она позволяет очень быстро проверять, принадлежит ли элемент некоторому множеству. Представьте себе охранника на входе в эксклюзивный клуб. У него нет полного списка имен гостей, а есть только блокнот с отметками. Когда гость приходит, охранник быстро проверяет отметки....
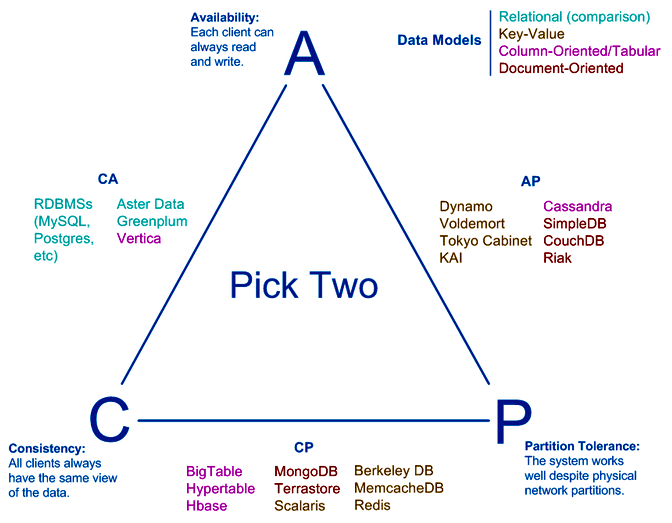
CAP – это акроним от англоязычных слов Consistency (Согласованность, Целостность), Availability (Доступность) и Partition tolerance (Устойчивость к разделению). Согласно утверждению профессора Калифорнийского университета в Беркли, Эрика Брюера, сделанному в 2000-м году, в распределенных системах осуществимы лишь 2 свойства из указанных 3-х. В частности, считается что нереляционные базы данных жертвуют согласованностью данных в...