 1862
1862 
Содержание
Apache Kafka – не единственный программный брокер сообщений и система управления очередями, используемая в высоконагруженных Big Data проектах. Кафка часто сравнивают с другим популярным продуктом аналогичного назначения – RabbitMQ. В сегодняшней статье мы рассмотрим, чем похожи и чем отличаются Apache Kafka и RabbitMQ, а также поговорим о том, что следует выбирать в конкретных случаях для практического применения.
Что такое RabbitMQ и как он работает
RabbitMQ – это программный брокер сообщений на основе стандарта AMQP, написанный на языке Erlang и состоящий из следующих основных компонентов [1]:
- Mnesia – распределенная СУБД реального времени для хранения сообщений, также написанная на языке Erlang – надстройка над ETS- и DETS-таблицами, предоставляющая уровень транзакций и распределённого выполнения [2];
- сервер;
- библиотеки поддержки протоколов HTTP, XMPP и STOMP, клиентские библиотеки AMQP для Java и .NET Framework [1];
- различные плагины (для мониторинга и управления через HTTP и веб-интерфейс, для передачи сообщений между брокерами и др.) [1].
RabbitMQ поддерживает несколько языков программирования (Perl, Python, Ruby, PHP), а также обеспечивает горизонтальное масштабирование для построения кластерных решений [1]. Поэтому RabbitMQ, который неформально называют «Кролик», довольно часто применяется в различных Big Data проектах. Однако, в связи с некоторыми его технологическими особенностями реализации, он не является полноценной заменой Apache Kafka.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
5 октября, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
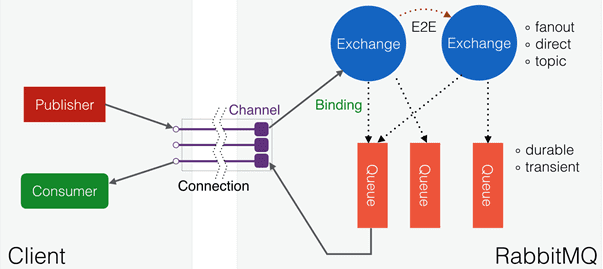
В упрощенном виде управление сообщениями выполняется в RabbitMQ следующим образом [3]:
- отправители (publishers) отправляют сообщения на обменники (exchange);
- обменники отправляют сообщения в очереди и в другие обменники;
- при получении сообщения RabbitMQ отправляет подтверждения отправителям;
- получатели (consumers) поддерживают постоянные TCP-соединения с RabbitMQ и объявляют, какую очередь они получают;
- RabbitMQ проталкивает (push) сообщения получателям;
- получатели отправляют подтверждения успеха или ошибки получения сообщения;
- после успешного получения сообщение удаляется из очереди.
Сходства Apache Kafka и RabbitMQ
Несмотря на принципиальные отличия этих систем обмена сообщениями, между ними довольно много общих моментов [4]:
- Прикладное назначение – Apache Kafka и RabbitMQ являются брокерами программных сообщений и используются для обмена информацией между различными приложениями.
- Схема обмена сообщениями – оба брокера работают по схеме «издатель-подписчик» (отправитель-получатель), когда источники данных направляют потоки информации, а получатели обрабатывают их по мере потребности.
- Потоки и пакеты сообщений – Кафка и Кролик в первую очередь позиционируются для работы с непрерывными потоками информации, однако, они позволяют объединять сообщения в пакеты. Kafka делает это более явно, повышая эффективность от пакетирования благодаря своим возможностям по распределению пакетов, а в RabbitMQ пакетирование является скорее «мнимым» из-за пассивной модели приёма, не препятствующей конфликтам получателей.
- Уведомления о сообщениях — Kafka и RabbitMQ обмениваются сигналами с отправителями и получателями при отправке и получении сообщений.
- Стратегии доставки – оба брокера способны реализовать стратегии «как максимум однократная доставка» и «как минимум однократная доставка», что позволяет сократить риски потери или дублирования сообщений.
- Репликация – обе системы обеспечивают репликацию сообщений.
- Гарантии отправки – Apache Kafka и RabbitMQ гарантируют порядок отправки сообщений с помощью уведомлений и стратегий доставки.
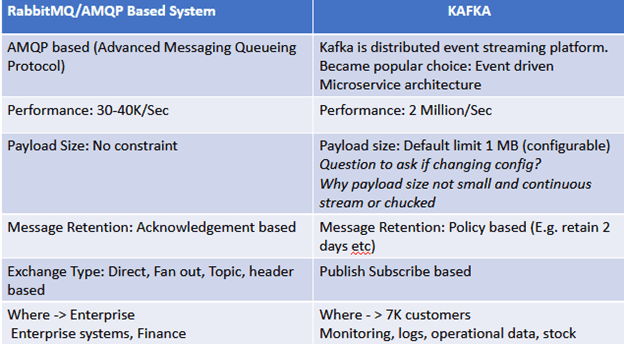
Чем Кафка отличается от Кролика
Основные отличия Apache Kafka и RabbitMQ обусловлены принципиально разными моделями доставки сообщений, реализуемыми в этих системах. В частности, Kafka действует по принципу вытягивания (pull), когда получатели (consumers) сами достают из топика (topic) нужные им сообщения. RabbitMQ, напротив, реализует модель проталкивания, отправляя необходимые сообщения получателям. В связи с этим Кафка отличается от Кролика по следующим критериям [3]:
- Сохранение сообщений – RabbitMQ помещает сообщение в очередь FIFO (First Input – First Output) и отслеживает статус этого сообщения в очереди, а Kafka добавляет сообщение в журнал (записывает на диск), предоставляя получателю самому заботиться о получении нужной информации из топика. Кролик удаляет сообщение после доставки его получателю, а Кафка хранит сообщение до тех пор, пока не наступит момент запланированной очистки журнала. Таким образом, Apache Kafka сохраняет текущее и все прежние состояния системы и может использоваться в качестве достоверного источника исторических данных, в отличие от RabbitMQ.
- Балансировка – благодаря pull-модели доставки сообщений RabbitMQ сокращает время задержки, однако возможно переполнение получателей, если сообщения прибудут в очередь быстрее, чем те могут их обработать. Поскольку в RabbitMQ каждый получатель запрашивает/выгружает разное количество сообщений, то распределение работы может стать неравномерным, что повлечет задержки и потерю порядка сообщений во время обработки. Для предупреждения этого каждый получатель Кролика настраивает предел предварительной выборки (QoS) – ограничение на количество скопившихся неподтвержденных сообщений. В Apache Kafka балансировка нагрузки выполняется автоматически путем перераспределения получателей по разделам (partition) топика.
- Пропускная способность – Kafka гарантирует порядок сообщений в разделе топика (partition) без конкурирующих получателей, что позволяет объединять сообщения в пакеты для более эффективной доставки и повышает пропускную способность системы.
- Масштабируемость – Кафка считается более адаптивной к масштабированию, обеспечивая ежедневный обмен миллиардами сообщений. Однако, стоит отметить, что далеко на каждый Big Data проект нуждается в таких высоких цифрах.
- Маршрутизация – RabbitMQ включает 4 способа маршрутизации на разные обменники (exchange) для постановки в различные очереди, что позволяет использовать мощный и гибкий набор шаблонов обменов сообщениями. Кафка реализует лишь 1 способ записи сообщений на диск, без маршрутизации.
- Упорядочивание сообщений – Кролик позволяет поддерживать относительный порядок в произвольных наборах (группах) событий, а Кафка обеспечивает простой способ поддержания упорядочения с поддержкой масштабирования путем последовательной записи сообщений в реплицированный журнал (топик).
- Работа с клиентом – про Apache Kafka говорят «тупой сервер, умный клиент», что означает необходимость реализации логики работы с сообщениями на клиентской стороне, т.е consumer заботится о получении нужных сообщений. RabbitMQ – наоборот, «умный сервер, тупой клиент», поскольку этот брокер сам обеспечивает всю логику работы с сообщениями.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
24 августа, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Кафка или Кролик: что выбирать для Big Data проекта
Обратной стороной широких и разнообразных возможностей RabbitMQ по гибкому управлению очередями сообщений (маршрутизация, шаблоны доставки, мониторинг получения) является повышенное потребление ресурсов и, соответственно, снижение производительности в условиях увеличенных нагрузок. А, поскольку именно такой режим работы характерен для Big Data систем, то в большинстве случаев Apache Kafka является наилучшим средством для управления сообщениями. Например, в случае сбора и агрегации множества событий от IoT-устройств, клиентских метрик, лог-файлов и аналитики Big Data с перспективой увеличения источников информации понадобится Кафка. А если необходим быстрый сообщениями между несколькими сервисами, RabbitMQ отлично справится с этой задачей [5]. Кролик можно использовать для обработки событий в режиме реального времени, т.е. этот брокер — решение только для реагирования на события, которые происходят сейчас. Кафка, напротив, обеспечивает полную историческую достоверность и сохранность всех данных, а также упрощает их распространение. Исходные данные принадлежат только отправителю, но каждый получатель может их фильтровать, трансформировать, дополнять данными из других источников и сохранять в собственных базах данных [6].
Подводя итог сравнению Apache Kafka и RabbitMQ, можно сделать вывод, что выбор того или иного брокера в первую очередь зависит от нагрузки, в которой предполагается его использование. В случае адекватного применения каждая из этих систем обмена сообщениями будет эффективным инструментом реализации Big Data проекта.
О другой популярной альтернативе Kafka, Apache Pulsar, читайте здесь. А в этой статье вы узнаете про тонкости работы с недоставленными сообщениями в Kafka и RabbitMQ.
Освойте администрирование и эксплуатацию Apache Kafka на практических курсах в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов, для руководителей, архитекторов, инженеров, администраторов, аналитиков Big Data и Data Scientist’ов в Москве:
- https://ru.wikipedia.org/wiki/RabbitMQ
- https://ru.wikipedia.org/wiki/Mnesia
- https://habr.com/ru/company/itsumma/blog/416629/
- https://habr.com/ru/company/itsumma/blog/437446/
- https://medium.com/@vozerov/kafka-vs-rabbitmq-38e221cf511b
- https://habr.com/ru/company/itsumma/blog/418389/

