 2439
2439 
Содержание
Apache Spark – это Big Data фреймворк с открытым исходным кодом для распределённой пакетной и потоковой обработки неструктурированных и слабоструктурированных данных, входящий в экосистему проектов Hadoop [1].
История появления Спарк и сравнение с Apache Hadoop
Основным автором Apache Spark считается Матей Захария (Matei Zaharia), румынско-канадский учёный в области информатики. Он начал работу над проектом в 2009 году, будучи аспирантом Университета Калифорнии в Беркли. В 2010 году проект опубликован под лицензией BSD, в 2013 году передан фонду Apache Software Foundation и переведён на лицензию Apache 2.0, а в 2014 году принят в число проектов верхнего уровня Apache. Изначально Спарк написан на Scala, затем была добавлена существенная часть кода на Java, что позволяет разрабатывать распределенные приложения непосредственно на этом языке программирования [1].
Классический MapReduce, Apache компонент Hadoop для обработки данных, проводит вычисления в два этапа:
- Map, когда главный узел кластера (master) распределяет задачи по рабочим узлам (node)$
- Reduce, когда данные сворачиваются и передаются обратно на главный узел, формируя окончательный результат вычислений.
Пока все процессы этапа Map не закончатся, процессы Reduce не начнутся. При этом все операции проходят по циклу чтение-запись с жесткого диска. Это обусловливает задержки в обработке информации. Таким образом, технология MapReduce хорошо подходит для задач распределенных вычислений в пакетном режиме, но из-за задержек (latency) не может использоваться для потоковой обработки в режиме реального времени [2]. Для решения этой проблемы был создан Apache Spark и другие Big Data фреймворки распределенной потоковой обработки (Storm, Samza, Flink).
В отличие от классического обработчика ядра Apache Hadoop c двухуровневой концепцией MapReduce на базе дискового хранилища, Spark использует специализированные примитивы для рекуррентной обработки в оперативной памяти. Благодаря этому многие вычислительные задачи реализуются в Спарк значительно быстрее. Например, возможность многократного доступа к загруженным в память пользовательским данным позволяет эффективно работать с алгоритмами машинного обучения (Machine Learning) [1].

Как устроен Apache Spark: архитектура и принцип работы
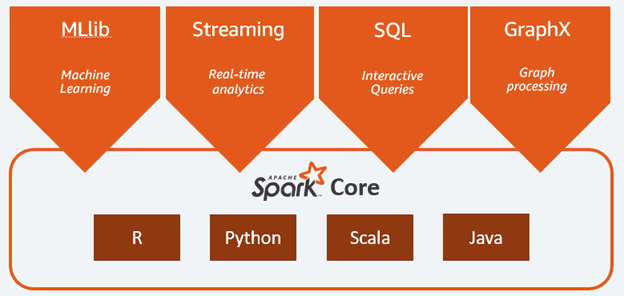
Спарк состоит из следующих компонентов:
- Ядро (Core);
- SQL – инструмент для аналитической обработки данных с помощью SQL-запросов;
- Streaming – надстройка для обработки потоковых данных, о которой подробно мы рассказывали здесь и здесь;
- MLlib – набор библиотек машинного обучения;
- GraphX – модуль распределённой обработки графов.
Spark может работать как в среде кластера Hadoop под управлением YARN, так и без компонентов ядра хадуп, например, на базе системы управления кластером Mesos. Спарк поддерживает несколько популярных распределённых систем хранения данных (HDFS, OpenStack Swift, Cassandra, Amazon S3) и языков программирования (Java, Scala, Python, R), предоставляя для них API-интерфейсы.
Справедливости ради стоит отметить, что Spark Streaming, в отличие от, например, Apache Storm, Flink или Samza, не обрабатывает потоки Big Data целиком. Вместо этого реализуется микропакетный подход (micro-batch), когда поток данных разбивается на небольшие пакеты временных интервалов. Абстракция Spark для потока называется DStream (discretized stream, дискретизированный поток) и представляет собой микро-пакет, содержащий несколько отказоустойчивых распределенных датасетов, RDD (resilient distributed dataset) [3].
Именно RDD является основным вычислительным примитивом Спарк, над которым можно делать параллельные вычисления и преобразования с помощью встроенных и произвольных функций, в том числе с помощью временных окон (window-based operations) [3]. Подробнее про временные окна мы рассказывали здесь на примере Apache Kafka Streams.
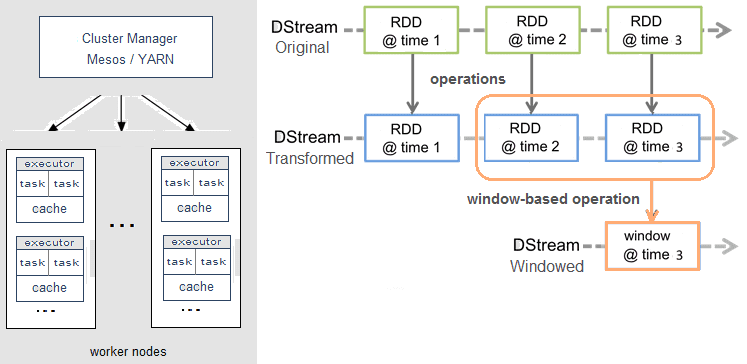
Внутреннее устройство Spark
Программные приложения, разрабатываемые с использованием фреймворка Spark, предназначены для выполнения в распределенной среде, такой как кластер, объединяющий несколько узлов. Архитектура этой распределенной (параллельной) среды включает в себя два основных компонента:
- драйвер Spark
- исполнители Spark
Драйвер Spark, выполняет распределение поступающих от пользователя задач среди действующих исполнителей. Таким образом, Spark-драйвер преобразует пользовательское приложение в набор задач (tasks) для исполнения. Экземпляр Spark-драйвера создается при запуске сессии Spark (когда создается сессия Spark), активен с момента первого запуска приложения и остается в активном состоянии до завершения сессии (пока приложение выполняется и не произошел сбой):
conf = pyspark.SparkConf().setAppName(MyApp).setMaster('local')
sc = pyspark.SparkContext(conf=conf)
#запуск Spark-драйвера
spark = SparkSession(sc)
Во время запуска драйвера ему выделяется определенное количество оперативной памяти (по умолчанию 1Гб). Разработчик может самостоятельно изменить объем выделяемой оперативной памяти с помощью метода config(). Для этого метода используется параметр spark.driver.memory:
spark = SparkSession.builder\
.config ("spark.driver.memory", "16g")\
.getOrCreate()
Приложение может разбиваться на несколько сотен и даже тысяч заданий (в зависимости от функционала). На основе составленного плана со всеми задачами драйвер Spark контролирует передачу этих задач исполнителям. При запуске каждый исполнитель регистрирует себя в драйвере.
Spark-исполнители (Spark executors) представляют собой рабочие процессы, ответственные за выполнение задач, поступающих от драйвера. Исполнители запускаются один раз при старте приложения Spark и продолжают свою работу на протяжении всего жизненного цикла программы. Они выполняют задачи, поступающие от драйвера, и передают результат обратно драйверу Spark. Каждому исполнителю, аналогично драйверу, выделяется определенное количество оперативной памяти, по умолчанию установленное на уровне 1 Гб. Каждый исполнитель также обладает определенным числом ядер (cores), и каждое ядро исполнителя отвечает за параллельное выполнение задач этим исполнителем. Чем больше количество ядер, тем больше задач может одновременно выполнять один исполнитель. Однако стоит контролировать количество ядер в каждом исполнителе, так как каждое ядро требует значительных затрат мощности процессора. Слишком большое количество ядер может привести к сбою приложения. Следующий код на языке Python отвечает за настройку конфигурации Spark-исполнителей:
spark = SparkSession.builder\
# Количество исполнителей
.config("spark.executor.instances", "4")\
# Память для каждого исполнителя
.config("spark.executor.memory", "2g")\
#Количество ядер для каждого исполнителя
.config('spark.executor.cores','2')\
Таким образом, распределенная архитектура приложения Spark позволяет выполнять большие объемы Big Data задач, требующих высокое количество вычислений.
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
21 сентября, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Где и как используется Apache Spark
Благодаря наличию разнопрофильных инструментов для аналитической обработки данных «на лету» (SQL, Streaming, MLLib, GraphX), Спарк активно используется в системах интернета вещей (Internet of Things, IoT) на стороне IoT-платформ, а также в различных бизнес-приложениях, в т.ч. на базе методов Machine Learning. Например, Спарк применяется для прогнозирования оттока клиентов (Churn Predict) и оценки финансовых рисков [4]. Однако, если временная задержка обработки данных (latency) – это критичный фактор, Apache Spark не подойдет и стоит рассмотреть альтернативу в виде клиентской библиотеки Kafka Streams или фреймворков Storm, Flink, Samza.
По набору компонентов и функциональным возможностям Spark можно сравнить с другим Big Data инструментом распределенной потоковой обработки – Apache Flink. Этому детальному сравнению в части потоковых вычислений мы посвятили отдельную статью. А о проблемах Спарк читайте здесь.
Источники
- https://dis-group.ru/company-news/articles/6-faktov-ob-apache-spark-kotorye-nuzhno-znat-kazhdomu/
- http://datareview.info/article/obrabotka-potokovyx-dannyx-storm-spark-i-samza/
- https://www.cloudera.com/developers/how-tos/apache-spark-how-tos/