
В этой статье мы продолжим рассказывать про практическое использование отечественных Big Data решений на примере российского дистрибутива Arenadata Hadoop (ADH) и массивно-параллельной СУБД для хранения и анализа больших данных Arenadata DB (ADB). Сегодня мы приготовили для вас еще 3 интересных кейса применения этих решений в проектах цифровизации бизнеса и государственном управлении.
Великолепная 5-ка в отечественном Big Data конкурсе
Далее рассмотрим следующие Big Data проекты:
- технологическая платформа для объединения федеральных хранилищ данных (ХД) и аналитики в ПАО «Ростелеком»;
- цифровая платформа Счетной палаты РФ;
- озеро данных (Data Lake) Новолипецкого металлургического комбината;
- распределённая СУБД для аналитики больших данных в X5 Retail Group.
Все эти проекты, участвовали в конкурсе ИТ-портала Global CIO «Проект года-2019» и вошли в ТОП-5 лучших решений, наряду с «умным» озером данных ПАО «Газпром нефть», о котором мы писали здесь [1]. Помимо уникальных особенностей реализации и глубокой практической направленности их также объединяет использование продуктов компании Arenadata: распределенной масштабируемой СУБД на основе open-source Greenplum и отечественного дистрибутива Apache Hadoop. Как это было сделано, разберем далее.
Arenadata DB в Ростелекоме
Начнем с глобального проекта ПАО «Ростелеком», суть которого состоит в разработке единой технологической платформы с целью объединения разрозненных ХД и множества отчетных систем федерального и регионального уровней. На решение возлагается роль информационного-аналитического пространства для полномасштабной цифровизации компании, включая следующие задачи [2]:
- реализация процессов управления данными, в т.ч. консолидация отчетности, управление НСИ (Master Data Management, MDM), поддержка бизнес-глоссария, обеспечение качества данных, мониторинг происхождения данных (data lineage и provenance) и другие функции Data Governance;
- снижение затрат на разработку и эксплуатацию информационных систем (Total Cost Ownership, TCO);
- повышение монетизации и демократизации данных;
- сокращение сроков разработки (Time to Market, T2M) за счет практик прототипирования решений и автоматизированного управления ETL-процессами;
- развитие бизнес-аналитики, в т.ч. за счет Data Science инструментов (Predictive Analytics, Machine Learning, Text Mining).
Дополнительно была учтена директива Правительства РФ по импортозамещению с помощью собственных разработок, отечественного ПО и open-source решений. Это условие стало еще одним аргументом в пользу выбора Arenadata DB как отказоустойчивой распределенной СУБД для аналитики и хранения больших данных. В частности, именно она выступает основой для развертывания на production-серверах так называемых «аналитических песочниц» — изолированного набора актуальных данных с ограниченным доступом определенной категории пользователей, например, Data Scientist’ов.
Помимо ADB в решении также используются Apache Hadoop, Hive и Spark, PostgreSQL, Oracle DB, IBM DataStage, IBM CDC. Сбор данных, а также пакетные и потоковые ETL-процессы обеспечиваются с помощью Apache Kafka, Airflow и NiFi соответственно. Разумеется, такая глобальная платформа интеграции множества информационных массивов и систем не обошлась без озера данных. Data Lake Ростелекома организовано на Hadoop HDP (коммерческий дистрибутив от Hortonworks Data Platform), куда загружаются данные, к которым не предъявляются высокие требования к скорости обработки и предоставления конечным пользователям. С помощью Apache Hive, популярного SQL-on-Hadoop средства, выполняется первичная обработка данных из Data Lake.
Цифровизация Счетной палаты РФ
Похожий стек Big Data технологий используется в другом крупном проекте цифровизации государственного сектора – Счетной палате РФ. Однако здесь также задействован еще 1 продукт компании Arenadata – отечественный Apache Hadoop для хранилища сырых данных в Data Lake. Arenadata DB используется для хранения витрин данных и промежуточных таблиц. Метаданные хранятся в NoSQL-СУБД MongoDB, а для пакетных ETL-задач используется Apache Airflow. Сырые данные Data Lake в формате JSON имеют дополнительно слой метаданных по модели RDF для описания структуры их хранения и взаимосвязей. Для обработки RDF-данных используется специализированный язык запросов SPARQL. Таким образом, цифровая платформа Счетной палаты РФ реализует некоторые идеи концепции Data Vault для построения современных DWH, когда между хранилищем сырых данных (Raw Vault) и узкопрофильными витринами данных для конечных бизнес-потребителей реализуется слой промежуточных таблиц. Это сделано за счет ETL-процессов и обогащения сырых данных из Data Lake метаданными с помощью самописных решений на языке Python. Примечательно, что созданная цифровая платформа используется для целого ряда проектов: построения аналитических моделей, организации единой среды предоставления отчетных показателей внешним ведомствам и прочих задач цифровизации Счетной палаты РФ [3].
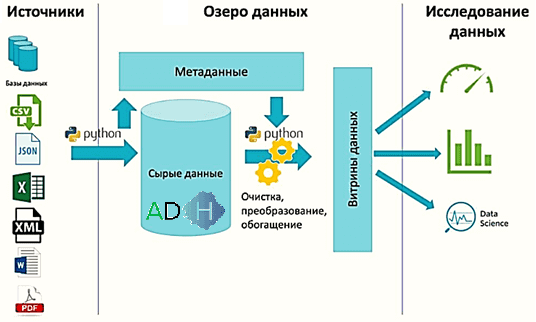
Промышленный Data Lake на ADH: кейс Новолипецкого металлургического комбината
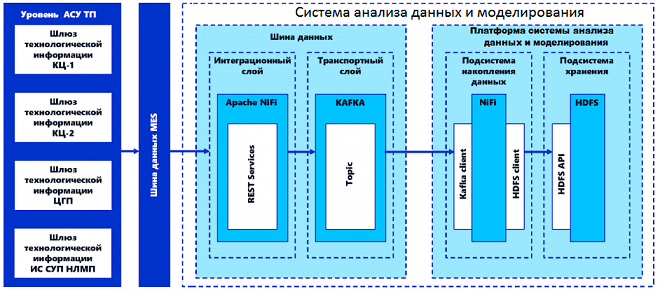
Интересен также опыт одной из НЛМК, одной из ведущих сталелитейных компаний мира с активами в России, ЕС и США. Arenadata Hadoop использовался для построения системы анализа данных и моделирования для отслеживания производственной цепочки и построения точных ML-моделей с целью оптимизации технологических процессов на основе цифровых двойников. ADH выполняет роль хранилища сырых данных из 70 различных источников: датчики промышленного интернета вещей (IIoT), MES- и АСУТП-системы. Также в это Data Lake на 300 терабайт загружены исторические данные за последние несколько лет работы предприятия, на основании чего созданы карты данных технологических и производственных процессов. Как и в ранее описанных примерах, для сбора данных и ETL-процессов использовались соответствующие Big Data инструменты: Apache Kafka, NiFi и Hive.
В рамках проекта разработана модель унифицированной витрины данных, а также реализовано управление метаданными с помощью Apache Atlas (тегирование, поиск и пр.). Для обеспечения информационной безопасности настроена централизованная ролевая модель доступа к данным, интегрированная со службой каталогов Active Directory. Благодаря этому Data Scientist’ы, основные бизнес-пользователи озера данных, быстро получают нужную им информацию для построения ML-моделей и проверки аналитических гипотез. Ожидается, что такая цифровизация производства сэкономит до 300 миллионов рублей в год за счет выявления дефектного сырья и оптимизации расхода дорогостоящих ферросплавов. Это позволит предотвращать до 40% брака и экономить до 10% на обслуживании оборудования за счет мониторинга его износа и предиктивной аналитики потенциальных отказов [4].
В следующей статье мы продолжим рассказывать про успехи применения отечественных Big Data продуктов и рассмотрим пример использования Arenadata DB в Х5 Retail Group — одной из ведущих отечественных компаний розничного ритейла. О новых призерах конкурса GlobalCIO с проектами Аренадата читайте здесь. А пока напоминаем, что наша Школа Больших Данных, как единственный авторизованный партнер компании Arenadata по сертификации специалистов и обучению, реализует специализированные курсы по ADH и ADB:
Как эффективно и безопасно развернуть озеро данных на кластере Apache Hadoop вы узнаете на практических курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Hadoop
- Администрирование кластера Hadoop
- Безопасность озера данных Hadoop
- Hadoop для инженеров данных
Источники
- https://www.ibs.ru/media/news/5-proektov-postroennykh-na-arenadata-popali-v-short-list-global-cio-proekt-goda/
- https://globalcio.ru/live/projects/3130
- https://globalcio.ru/live/projects/3135
- https://www.comnews.ru/digital-economy/content/205026/2020-03-16/2020-w12/ozero-znaniy-zachem-nlmk-postroili-data-lake

