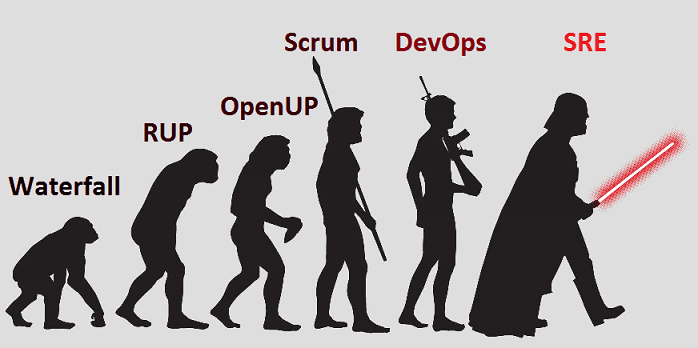
Большие данные требуют огромной гибкости и большой надежности – сегодня мы расскажем, что кто обеспечивает бесперебойную работу Google и других ИТ-гигантов и что нас ждет после DevOps. Читайте в нашей новой статье, как развиваются Agile-подходы к организации процессов разработки и эксплуатации Big Data систем и сколько это стоит.
Что такое SRE и зачем это нужно Big Data
Big Data системы функционируют в условиях повышенной нагрузки: постоянно увеличивающиеся потоки данных из множества разных источников хранятся и обрабатываются на распределенных серверах одного или нескольких кластеров. Благодаря механизму репликации, который поддерживает наиболее распространенная файловая система больших данных, HDFS, выход некоторых узлов из строя в большинстве случаев не приведет к полной потере информации. Однако, даже временный отказ или замедление работы приложения может быть катастрофичным для бизнеса.
Поэтому большие данные нуждаются в повышенной надежности всех компонентов системной инфраструктуры. Это достигается не только за счет программного и аппаратного обеспечения, но и с помощью специальных методов организации работы всех участников процессов создания и эксплуатации Big Data приложений. Одним из таких методов является SRE (Site/System Reliability Engineering) – обеспечение эксплуатационной надежности системы, набор инженерных практик, поддерживающих надежную и безотказную работу приложений в настоящем и будущем, с учетом требуемой масштабируемости и внезапных форс-мажоров [1]. Большое влияние на SRE оказали принципы Agile, в частности, подход DevOps, а также дисциплина анализа рисков и библиотека лучших практик организации работы ИТ-подразделений – ITIL (Information Technology Infrastructure Library).
Концепция SRE развивалась с начала 2000-х годов в одном из главных пионеров Big Data, компании Google для решения внутренних задач: четкого измерения времени безотказной работы сервисов и точного определения их доступности. Еще несколько лет назад Google не говорил о SRE публично, считая эту концепцию своим конкурентным преимуществом, которое следует держать в секрете от конкурентов и клиентов.
Но с 2016 года было решено «открыть» SRE для повышения надежности клиентских сервисов, в частности, облачной платформы Google Cloud Platform. В рамках этого для обучения потребителей практикам SRE Google запустил программу Customer Reliability Engineering (CRE) [2].
Развивая общие ценности Agile, в частности DevOps, SRE нацелен на бесперебойную работу приложений в настоящем и будущем за счет устранения организационных барьеров, единых индикаторов оценки и общей ответственности всех участников, от разработчиков до эксплуатационщиков. Таким образом, SRE расширяет DevOps, пролонгируя его за счет взаимодействия со всеми участниками проекта на протяжении всего жизненного цикла разработки ПО. Особое значение придается этапам проектирования и начальной разработки, чтобы заблаговременно заложить в систему возможности беспроблемного масштабирования и безотказности функционирования. Это гарантирует бесперебойную работу создаваемых решений не только сейчас, но и в будущем [1].
Что общего между SRE и DevOps и чем они отличаются
Появление DevOps связано с развитием Agile, облачных вычислений и микросервисной архитектуры, а также стремлением сократить разрыв между разработкой и эксплуатацией ПО. Однако, DevOps определяет лишь общее поведение участников процессов, но не даёт четких рецептов достижения успеха. SRE уточняет концепцию DevOps, включая дополнительные методы и практические рекомендации, в частности, содержит требования к оценке и критериям качественной совместной работы разработки и эксплуатации.
Как и DevOps, поддерживающий принципы Agile, SRE ориентирован на то, чтобы создавать, тестировать и выпускать новые продукты, их обновления и исправления как можно быстрее. SRE связывает разработчиков, эксплуатанционщиков и заинтересованных лиц со стороны бизнеса, стремящихся добиться бесперебойной работы всех сервисов, чтобы справиться с растущими потребностями и притязаниями клиентов [1].
Цель SRE сделать так, чтобы команды разработки и эксплуатации заранее согласовывали порог ошибок, которые необходимо устранить перед запуском продукта. DevOps и SRE лучше подходят для крупных предприятий с устоявшимися бизнес-процессами и Big Data системами. В малом бизнесе и стартапах обязанности DevOps- и SRE-инженеров делят между собой разработчики ПО, инженеры по инфраструктуре и системные администраторы [1].
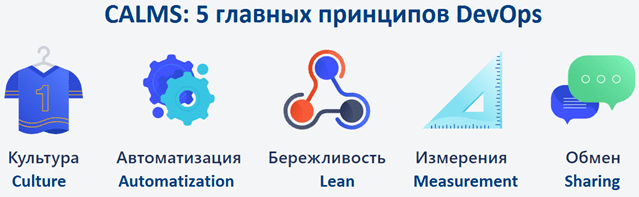
Ниже в таблице показано, как SRE реализует CALMS — 5 основных принципов DevOps: Культуру (Culture), Автоматизацию (Automatization), Бережливость (Lean), Измерения (Measurement), Обмен (Sharing) [2].
|
Принцип DevOps |
SRE |
|
Культура (Culture) |
Поощрение быстрого движения вперед за счет снижения стоимости неудач |
|
Автоматизация (Automatization) |
Автоматизировать операции и уменьшить ручной труд, фокусируясь на усилиях, несущих долгосрочные выгоды системе |
|
Бережливость (Lean) |
Необходим баланс между авариями и отказами по отношению к новым релизам |
|
Измерения (Measurement) |
Необходимы точные измерения доступности, времени безотказной работы, простоя, активной нагрузки и т.д. Эти индикаторы SRE (SLI, SLO, SLA, RPO и RTO) и их важность для бизнеса мы рассматриваем в отдельной статье. |
|
Обмен (Sharing) |
Совместное владение кодом и инфраструктурой благодаря использованию единых инструментов и техник |
Чем занимается инженер по эксплуатационной надежности и сколько это стоит
Помимо автоматизации процессов администрирования и конфигурирования серверов, SRE-инженер также отвечает за скорость работы и доступность инфраструктуры [3]. Чаще всего такие специалисты востребованы в крупных Big Data проектах, а также SaaS-, PaaS- и IaaS-провайдерами, которые должны обеспечивать безотказную работу своих сервисов в режиме 24 часа 7 дней в неделю и все 365 дней в году, ведь каждая минута простоя оборачивается серьезными потерями для бизнеса [1].
Основными рабочими обязанностями инженера по эксплуатационной надежности являются следующие [3]:
- разработка и поддержание документации в актуальном состоянии – поскольку каждая секунда простоя инфраструктуры приводит к реальным финансовым потерям для бизнеса, для максимально быстрого реагирования SRE-инженеры создают инструкцию (runbook) с перечислением действий, которые надо выполнить для оперативного решения проблем, и с указанием систем проверки в случае сбоев;
- оптимизация всего технологического стека на различных уровнях, от программного кода до устройства датацентра и развертывания в нем оборудования;
- выбор и внедрение новых технологий – SRE-инженеры работают не с отдельными продуктами и сервисами, а со всем ИТ-комплексом, поэтому им необходимо выбирать новые технологии с учетом стратегического развития компании в целом.
В настоящее время по причине ограниченного количества крупных data-driven компаний уровня Google, Facebook, Amazon, Dropbox и т.д., спрос на инженеров по эксплуатационной надежности пока не слишком высок. Однако, постепенная цифровизация частных и государственных предприятий, их миграция в облака и получение сервисов от сторонних разработчиков повышают потребность в SRE-инженерах. По мере распространения технологий Big Data, DevOps и принятия Agile-принципов спрос на SRE будет расти, а роль эта начнет принимать все более четкие очертания [1]..
Тем не менее, даже в условиях пока ограниченного спроса, SRE-инженеры являются самыми высокооплачиваемыми специалистами в ИТ-сфере. Например, в США на 1-ю половину 2019 года медиана зарплаты SRE-инженера находится в районе 85 тысяч долларов в год (около 500 тысяч рублей в месяц), тогда как DevOps зарабатывает примерно 71 тысячу долларов в год (около 400 тысяч рублей в месяц) [4]. Сейчас в России инженеры по эксплуатационной надежности требуются в крупные ИТ-компании (Яндекс, Лаборатория Касперского), банки (Сбербанк, Тинькофф-банк) и ритейл-сектор (X5 Retail Group) с месячной зарплатой от 70 до 200 тысяч рублей (по данным рекрутинговой площадки HeadHunter).

Узнайте, как успешно использовать лучшие практики Agile, DevOps и SRE, не разорившись на дорогих специалистов, на обучающем курсе «Аналитика больших данных для менеджеров» в нашем учебном центре для руководителей, аналитиков, архитекторов, инженеров и исследователей Big Data в Москве.
Источники

[…] Тем не менее, несмотря на указанные проблемы, DevOps и прочие Agile-инструменты цифровизации продолжают внедряться в нашу жизнь, меняя рабочие процессы и сознание их участников. Концепция девопс тоже продолжает свое развитие, трансформируясь в обеспечение эксплуатационной надежности — SRE, о чем мы рассказываем в следующей стать&…. […]
[…] надежности в материале про эволюцию […]