Зачем Databricks выпустил Arc, чем это отличается от Splink, и как эти инструменты позволяют решать проблему связывания данных с помощью алгоритмов машинного обучения. Как работает связывание данных Продолжая разговор про качество данных и разрешение сущностей (entity resolution) , сегодня подробно рассмотрим этап связывания записей с использованием логики на основе правил...
Знай своего клиента: качество данных с identity resolution в Zingg и Splink
Как качество данных связано с разрешением сущностей, чем entity resolution отличается от identity resolution, зачем нужны графы идентичности, как их построить и где использовать. Борьба за качество данных с entity resolution Результаты аналитической обработки данных напрямую зависят от их качества, о ключевых показателях и задачах обеспечения которого мы писали здесь....
Барьерный режим выполнения в Apache Spark и при чем здесь глубокое обучение
Что такое барьерный режим выполнения в Apache Spark, чем он отличается от вычислительной модели MapReduce, как связан с глубоким машинным обучением и где используется на практике. Что такое барьерный режим выполнения в Apache Spark Способ выполнения заданий Spark определяется режимом выполнения приложения, заданным на уровне фреймворка. На платформе. Именно от...
Кластерный анализ графов с медоидами: алгоритм k-medoids
Что такое алгоритм k-medoids, чем он отличается от k-means и как этот метод кластеризации применяется для анализа графов: принципы и инструменты. Что такое медоид и как устроен алгоритм кластеризации k-medoids Кластеризация — это метод машинного обучения для поиска кластеров или сообществ в наборе данных. Цель в том, чтобы найти кластеры,...
Кибербезопасность в MLOps: угрозы и лучшие практики
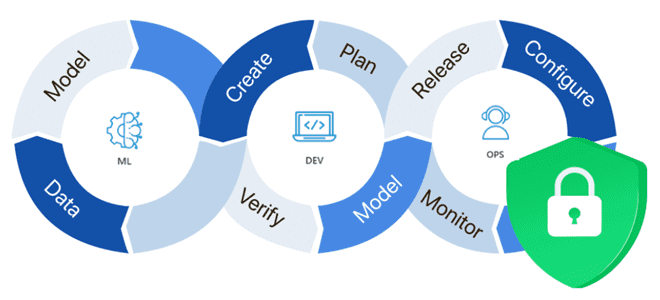
Почему безопасность ML-систем становится все более важным вопросом и как ее обеспечить: MLOps-подходы, практики и технологии защиты данных, моделей машинного обучения, а также вычислительных и инфраструктурных конвейеров. Защита данных для машинного обучения В связи с активным внедрением система машинного обучения в производственное использование, вопрос безопасности становится все более актуальным. ML-системы...
Что такое LLMOps или MLOps для больших языковых моделей

Зачем управлять трансферным обучением больших языковых моделей и что входит в это управление: знакомимся с расширением MLOps для LLM под названием LLMOps. Что такое LLMOps Большие языковые модели, воплощенные в генеративных нейросетях (ChatGPT и прочие аналоги), стали главной технологией уходящего года, которая уже активно используется на практике как частными лицами,...
MLOps с Tecton и Apache AirFlow

Что представляет собой MLOps-платформа Tecton и как запустить на ней конвейеры машинного обучения, используя провайдер Tecton-AirFlow, чтобы управлять ресурсами Tecton в этом ETL-оркестраторе. Что такое Tecton и при чем здесь MLOps Поскольку концепция MLOps направлена на безбарьерную автоматизацию всех этапов жизненного цикла систем машинного обучения, для этого нужны специализированные средства....
Машинное обучение с Greenplum: обзор ML-расширений

Как использовать Greenplum в проектах машинного обучения: знакомимся с расширением PostgresML и модулем pgvector. Возможности и ограничения плагинов, превращающих MPP-СУБД в полноценный MLOps-инструмент. Как превратить Greenplum в векторную базу данных с расширением pgvector Будучи вариацией PostgreSQL с механизмами массово-параллельной загрузки, Greenplum отлично справляется с огромным объемом данных. Однако, к хранилищам...
Автоматизированное тестирование в MLOps: что и как проверять?
Мы уже писали про особенности тестирования систем машинного обучения. Чтобы не повторяться, сегодня рассмотрим фреймворки для реализации идей MLOps, а также рассмотрим, какие тесты должны быть пройдены для проверки работоспособности ML-продукта. 3 категории тестов для ML-систем Согласно концепции MLOps, полный конвейер разработки включает в себя три основных компонента: конвейер данных,...
RAG-приложения и Neo4j: поддержка векторного индекса для LLM
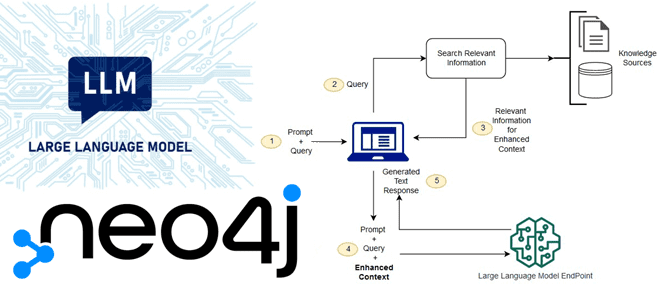
Что не так с большими языковыми моделями, как RAG-приложения расширяют возможности LLM и зачем в графовой СУБД Neo4j добавлена поддержка векторного индекса. Зачем нужны RAG-приложения: ограничения базовых LLM-сетей С появлением ChatGPT и других генеративных нейросетей, большие языковые модели (LLM, Large Language Models) стали активно применяться для решения множества бизнес-задач, связанных...