
Apache Samza часто сравнивают с другими Big Data фреймворками распределенных потоковых вычислений в реальном времени (Real Time, RT): Kafka Streams, Spark Streaming, Flink и Storm. Apache Spark и Flink обладают практически одинаковым набором функциональных возможностей и компонентов, поэтому их можно сравнивать между собой более-менее объективно. Apache Samza является более простой средой, которая в некоторых случаях может конкурировать с Kafka Streams и Storm. Сегодня мы расскажем, как именно Apache Samza используется на практике и почему крупные data-driven компании выбирают этот фреймворк потоковых RT-вычислений.
За и против Apache Samza: когда выбирать
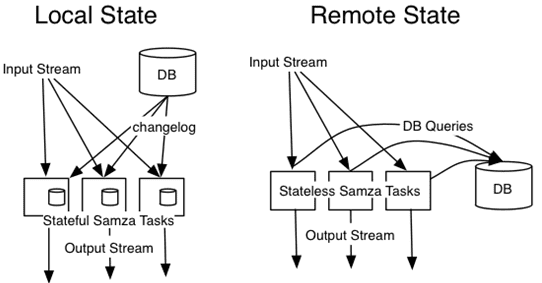
Прикладные варианты использования Apache Samza (use-cases) обусловлены достоинствами и недостатками этой Big Data системы. В частности, Samza сохраняет состояние приложений (stateful), используя отказоустойчивую систему контрольных точек, реализованную как локальное хранилище значений ключей. Это позволяет Samza предлагать гарантированную доставку хотя бы один раз (at-least-once), но не обеспечивает точного восстановления агрегированного состояния, например, количества в случае сбоя, поскольку данные могут быть доставлены более одного раза [1].
Однако, Самза будет отличным выбором, если необходимо работать с состоянием, имеющим большой объем, например, несколько гигабайт на раздел. Поскольку данные обрабатываются на тех же узлах кластера, где хранится состояние, это позволяет эффективно работать с ним, когда оно уже не помещается в памяти. Также, по аналогии с Apache Storm, стоит отметить гибкость подключения сторонних модулей к Samza. Модули выполнения, обмена сообщениями и хранения могут быть заменены любыми альтернативами с минимальным приложением времени и сил. Тем не менее, несмотря на наличие Beam-совместимого API-интерфейса, позволяющего обрабатывать данные на других, не только Java-подобных, языках программирования, включая Python [2], говорить о том, что Смаза может в этом отношении конкурировать с Apache Storm, пока рановато [1].
Таким образом, можно сделать вывод, что Apache Samza – подходящий вариант для потоковых рабочих RT-нагрузок в совокупности с Hadoop и Kafka, в т.ч. когда несколько команд потоки данных на разных этапах обработки. Samza значительно упрощает многие части обработки потоков и обеспечивает низкую задержку. Однако, если требуется обработка с чрезвычайно низкой задержкой со гарантией строго однократной доставки сообщений (exactly once), лучше выбирать между Apache Flink, Kafka Streams или Storm (вместе с API Trident) [1].
3 примера практического использования Самза в реальных Big Data проектах
Поскольку изначально Самза была разработана командой LinkedIn, неудивительно, что именно этот проект является наиболее известным кейсом использования этой Big Data среды распределенной потоковой обработки. Большая часть обработки, которая происходит в LinkedIn, — это обработка данных в стиле удаленного вызова процедур (RPC, Remote Procedure Call), где ожидается очень быстрый ответ. В качестве основной Big Data системы используется Apache Hadoop с пакетной, а не потоковой обработкой данных. Чтобы не ждать много времени для пакетной обработки в Hadoop, используется Самза, которая позволяет выполнять вычисления в потоковом режиме, асинхронно и быстро, от нескольких миллисекунд, практически в реальном времени [3].

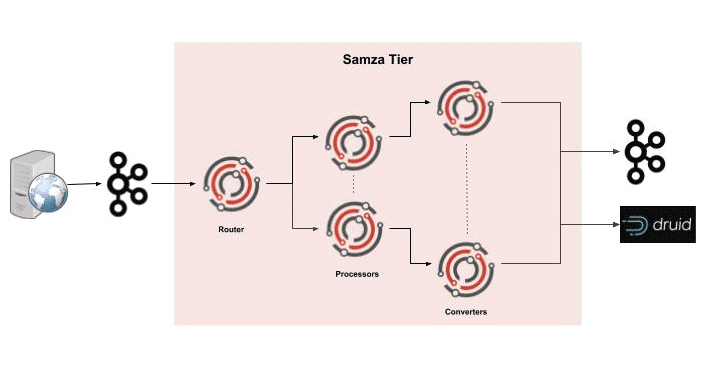
Однако, Самза применяется и в других крупных ИТ-компаниях. Например, инженерная команда корпоративного мессенджера Slack построила свою платформу данных на основе Apache Samza. Все сервисы в Slack генерируют свои данные в виде журналов, которые агрегируются кластером Kafka. Журналы обрабатываются маршрутизатором Samza (Router), который десериализует входящие события и отправляет на другие обработчики (Processors). Processor выполняет агрегацию с использованием хранилища состояний и посылает обработанные данные конвертеру (Coverter), который направляет информацию в колоночную базу данных Druid для аналитики и запросов. При обнаружении аномальных событий, например, пиков производительности, автоматически генерируется предупреждение. Описанная платформа является расширяемой, чтобы каждая команда Slack могла создавать собственные приложения на ее основе.
Еще одним примечательным примером использования Samza в Slack является их экспериментальная среда для измерения результатов A/B-тестирования практически в реальном времени. Samza применяется для объединения потока показателей, связанных с производительностью и дополнительными данными об экспериментах с клиентами. Это позволяет Slack узнать, как именно каждый эксперимент влияет на их общее поведение клиента [4].
Отметим, что Самза также активно используется в eBay, TripAdvisor, Redfin, Optimizely [5], Intuit, Metamarkets, Quantiply, Fortscale [6] многих других компаниях по всему миру.
Все особенности потоковой обработки больших данных в режиме реального времени рассматриваются на наших специализированных курсах для руководителей, архитекторов, инженеров, администраторов, аналитиков Big Data и Data Scientist’ов в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
Источники
- https://quasar.site/tutorials/499/hadoop-storm-samza-spark-i-flink-sravnenie-platform-bolshikh-dannykh
- https://www.zdnet.com/article/real-time-data-processing-just-got-more-options-linkedin-releases-apache-samza-1-0-streaming/
- https://www.infoq.com/articles/linkedin-samza/
- http://samza.apache.org/case-studies/slack
- http://samza.apache.org/
- http://datareview.info/article/obrabotka-potokovyx-dannyx-storm-spark-i-samza

