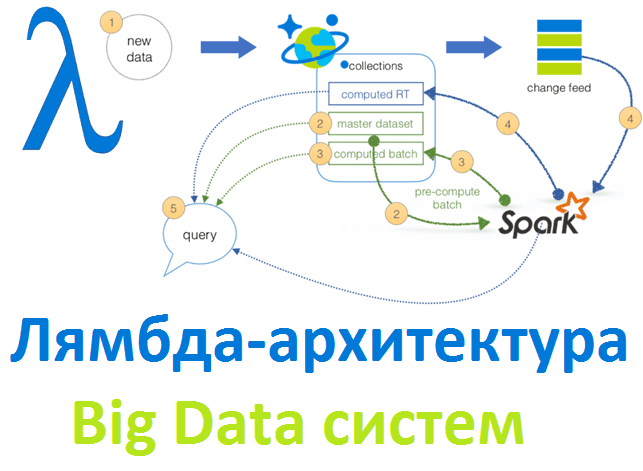
Рассматривая основы больших данных, сегодня мы расскажем лямбда-архитектуру, одну из двух главных подходов к построению Big Data систем. Читайте в нашей статье, зачем нужна эта концепция и как она работает, а также при чем тут машинное обучение, интернет вещей, Apache Spark и Hadoop.
Что такое Лямбда-архитектура и зачем она нужна
Рассмотрим типичный кейс по рассылке контекстной рекламы о скидках в ближайшем офлайн-магазине. Для повышения конверсии необходимо персонализировать маркетинговое предложение. Для этого следует быстро и точно сегментировать каталог клиентов с учетом анализа исторических данных по каждому из них, одновременно определив местоположение конкретного абонента в режиме реального времени. За сегментирование и предиктивную аналитику клиентских потребностей отвечают алгоритмы машинного обучения (Machine Learning). При этом реклама становится нерелевантной при физическом перемещении потребителя, поэтому нужно успеть сообщить потенциальному покупателю маркетинговое предложение, пока он находится в зоне пешей досягаемости торгового объекта. Таким образом, требуется выполнить онлайн-анализ непрерывного потока геоданных.
Этот пример отлично иллюстрирует задачи Big Data системы, когда есть потребность в интерактивной предиктивной аналитике на базе исторического бэкграунда. Разумеется, большие данные предполагают высокую скорость их обработки. Однако, на практике, некоторые операции, в частности, классический MapReduce на Hadoop, могут выполняться достаточно долго. В ряде случаев подобная задержка приведет к устареванию информации и потери ее актуальности. Чтобы предупредить эту проблему, необходимо объединить потоковую обработку данных в режиме реального времени с результатами пакетной аналитики. Для этого была предложена лямбда-архитектура, когда обработка данных разделяется на 2 пути [1]:
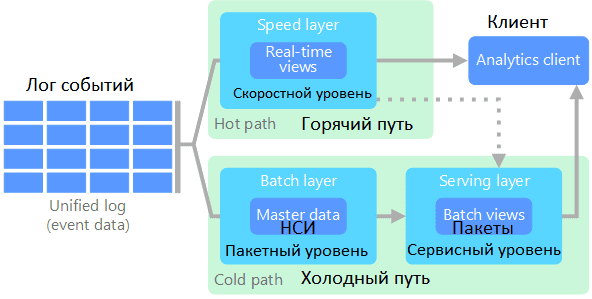
- «холодный путь» — пакетный уровень, где все входящие данные хранятся в необработанном виде и обрабатываются в пакетном режиме. Обычно пакетный уровень представлен озерами больших данных (Data Lake) на базе Apache Hadoop, где содержится «сырая» информация, которая не изменяется и не обновляется, а лишь пополняется новыми данными. Именно здесь содержатся так называемые мастер-данные или нормативно-справочная информация (НСИ), важная для бизнеса о клиентах, продуктах, услугах, персонале, технологиях, материалах и прочих доменных знаниях, которые достаточно редко изменяются и не являются транзакционными. В рассмотренном примере алгоритмы Machine Learning используют пакетные данные для сегментирования клиентов и составления прогнозных моделей, анализируя сохраненную историю пользовательского поведения. Также важно, что именно этот уровень используется для обработки данных по расписанию, т.е. формирования пакетных заданий.
- «горячий путь» — скоростной уровень (или уровень ускорения), где данные анализируются в режиме реального времени. Этот уровень обеспечивает минимальную задержку обработки с некоторой потерей точности. Он представляет собой совокупность складов данных, где в отдельные представления реального времени добавляется информация с коротким жизненным циклом, чтобы исключить дублирование данных. Для реализации скоростного уровня обычно используются Big Data фреймворки потоковой обработки: Apache Spark, Storm или Flink.
Hadoop для инженеров данных
Код курса
HDDE
Ближайшая дата курса
17 июня, 2024
Продолжительность
40 ак.часов
Стоимость обучения
120 000 руб.
В этой архитектуре также выделяют сервисный уровень (или уровень обслуживания), который индексирует пакетное представление – результаты пакетного уровня для эффективного выполнения запросов. За счет индексации и обработки поступающей информации, результаты немного отстают во времени. Уровень ускорения обновляет уровень обслуживания, отправляя ему добавочные обновления с учетом последних данных [1].
Таким образом, лямбда – это архитектурный подход, при котором произвольная функция применяется к произвольному набору данных за минимальное время. Универсальность концепции обеспечивает быстроту решения любых задач, в т.ч. сложных [2]. Если формализовать этот подход в виде функционального уравнения, которое определяет любой запрос в большой области данных, оно будет выглядеть так [3]:
Query = λ (Complete data) = λ (live streaming data) * λ (Stored data)
Это уравнение означает, что все связанные с данными запросы могут обрабатываться путем объединения результатов из исторического хранилища в форме пакетов и потоковой передачи в реальном времени с помощью скоростного уровня [3].
Где и как используется λ-подход в Big Data
Итак, лямбда-архитектура позволяет обрабатывать большие данные в режиме, близкому к реальному времени. При этом этот подход является отказоустойчивым и масштабируемым. Благодаря функциям пакетного и скоростного уровней можно добавлять новые данные в основное хранилище, обеспечивая при этом сохранность существующих данных. Поэтому лямбда-архитектура широко используется на практике, во многих Big Data проектах, в частности, Twitter, Netflix и Yahoo [3].
Обобщая кейсы применения λ-архитектуры, можно сказать, что она актуальна для тех корпоративных моделей обработки данных, где [3]:
- требуется разовая обработка пользовательских запросов с использованием неизменяемого хранилища данных;
- нужны быстрые ответы и различные обновления в форме новых потоков данных;
- необходима сохранность исторических данных, когда ни одна из записей не должна быть удалена, с возможностью добавления обновления и новых данных в хранилище.
Таким образом, лямбда-подход актуален не только для бизнес-приложений с пакетной и потоковой обработкой Big Data, но и для систем интернета вещей (Internet of Thing, IoT), в т.ч. промышленного (Industrial IoT, IIoT). Напомним, архитектура таких систем предполагает сбор малых данных со множества различных датчиков, их сохранение, агрегацию и облачную обработку в т.ч. с использованием алгоритмов Machine Learning. Пример реализации лямбда-архитектуры для IoT-системы смотрите в нашей новой статье.
С прикладной точки зрения интересно использование Apache Spark в построении λ-архитектуры, т.к. этот фреймворк позволяет обрабатывать большие данные как в пакетном, так и в потоковом режиме. Справедливости ради здесь стоит отметить, что Spark реализует не строго потоковую обработку данных, а микро-пакетный подход (micro-batch), однако, эти вычисления укладываются в концепцию near real-time. Кроме того, библиотека машинного обучение Spark MLLib включает расширенный набор современных алгоритмов Machine Learning. А средства Spark SQL дает возможность работать с данными с помощью привычных инструментов BI-аналитики: структурированных запросов реляционной логики.
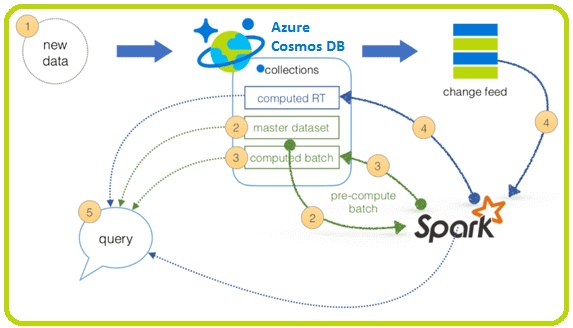
Поэтому Apache Spark используется во множестве Big Data систем на базе лямбда-архитектуры, в частности, в Azure Cosmos DB – распределенной многомодельной базе данных, интегрированной с аналитической платформой HDInsight [4]:
- все данные отправляются в Azure Cosmos DB для обработки;
- пакетный уровень предполагает неизменяемый набор мастер-данных и предварительно вычисляет пакетные представления;
- сервисный уровень предусматривает представления пакетов данных для быстрой отправки запросов;
- скоростной уровень компенсирует время обработки данных, используя только последние обновления;
- ответ на любой запрос получается за счет объединения результатов пакетного представления и вычислений в режиме реального времени.
Достоинства и недостатки архитектуры
Итак, лямбда-архитектура предоставляет следующие преимущества для Big Data системы [3]:
- высокая сохранность исторических данных за счет пакетного уровня на базе Hadoop Data Lake или другого отказоустойчивого распределенного хранилища с низкой вероятностью ошибок и сбоев;
- баланс скорости и надежности;
- масштабируемость.
Однако, λ-подходу свойственны следующие недостатки [2]:
- невозможность изменения стратегии анализа данных «на лету» — конечная непротиворечивость данных делает невозможной отправку информации обратно на пакетный уровень. Требуется повторное проведение всех вычислений, из-за привязки к долговременному хранилищу НСИ, данные трудно перенести или реорганизовать. А затраты на повторное вычисление каждого пакетного цикла не всегда оправданы на практике [3].
- отсутствие BI-средств – большинство инструментов, ориентированных на лямбда-архитектуру, не поддерживает SQL-запросы или другие типичные средства бизнес-аналитики, относясь к стеку Big Data, в частности NoSQL.
- сложность – множество разнородных компонентов, которые передают данные друг другу, что задерживает вычисления в реальном времени. Логика обработки информации дублируется в холодном и горячем путях с использованием различных структур данных, усложняя общее управление. Также увеличиваются накладные расходы на разработку.
Впрочем, это частично данные недостатки компенсируются с помощью Apache Spark. Однако, для быстрой обработки событий в режиме реального времени без пакетного представления более целесообразен другой подход – Каппа-архитектура, о чем мы поговорим в следующей статье.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
15 июля, 2024
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Больше практических подробностей про архитектуры больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Архитектура Данных
- Hadoop для инженеров данных
- Интеграция Hadoop и NoSQL
- Apache Spark для разработчиков
- https://docs.microsoft.com/ru-ru/azure/architecture/data-guide/big-data/
- http://datareview.info/article/lyambda-arhitektura-novyiy-podhod-k-analizu-dannyih/
- https://www.machinelearningmastery.ru/a-brief-introduction-to-two-data-processing-architectures-lambda-and-kappa-for-big-data-4f35c28005bb/
- https://docs.microsoft.com/ru-ru/azure/cosmos-db/lambda-architecture