Недавно мы рассказывали об особенностях запуска приложений Apache Spark в кластере Kubernetes с учетом новшеств релиза 3.1.1, где с этого варианта развертывания снят экспериментальный режим. В дополнение к ранее рассмотренным способам оптимизации Спарк-приложений, сегодня разберем, как инженеру Big Data ускорить их при запуске на платформе K8s.
Как ускорить Spark-приложения на Kubernetes
Прежде всего отметим, что само по себе развертывание Spark-заданий в кластере Kubernetes не увеличивает их производительность по сравнению с другими менеджерами ресурсов, таких как Hadoop YARN, Apache Mesos и пр. Однако, дополнительный уровень абстракции, который накладывает контейнеризация, не снижает скорость выполнения распределенных приложений, что доказывает бенмаркинговое сравнение, проведенное в июле 2020 года компанией Data Mechanics. В рамках этого TPC-DS теста, который считается стандартом де факто для оценки Big Data фреймворков, Hadoop YARN и Kubernetes показали примерно одинаковую производительность при обработке 1 ТБ данных и 100 SQL-запросов. В исследовании участвовали Спарк-приложения, запущенные в облаках под управлением Google Kubernetes Engine и Dataproc от Google Cloud Platform с Hadoop YARN [1].
Тем не менее, дополнительно к наиболее распространенным способам ускорения Spark-заданий, о которых мы рассказывали здесь, здесь и здесь, можно еще более повысить производительность распределенных приложений, запущенных на платформе K8s. Для этого рекомендуется выполнить следующие действия [2]:
- использовать SSD-диски или другие твердотельные накопители с повышенной емкость, чтобы увеличить пропускную способность shuffle-операций;
- оптимизировать размеры подов, где развернуты Спарк-приложения, чтобы эффективно использовать вычислительные ресурсы каждого узла. К примеру, превышение значения параметра executor.cores в 2-3 раза, чем spark.kubernetes.executor.request.cores, называется избыточной подпиской и может значительно повысить производительность для рабочих нагрузок с низкой загрузкой ЦП.
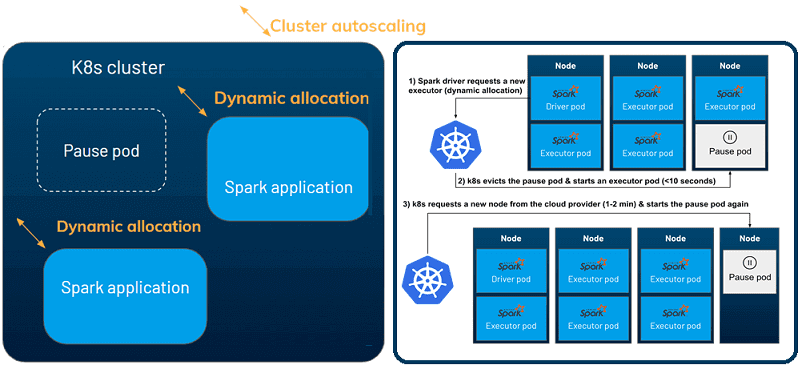
- включить динамическое распределение (dynamic allocation), подробнее о котором мы поговорим далее;
- следить за памятью подов, потребляемых Спарк-заданиями, что также детально рассмотрим ниже.
Чем полезно dynamic allocation для Spark-приложений в K8s
Включение динамического распределения на уровне приложения и автомасштабирования на уровне кластера позволит облачной инфраструктуре быстро реагировать на изменения рабочих нагрузок и повысит рентабельность всей Big Data системы. Есть два уровня динамического масштабирования:
- на уровне приложения, что позволяет каждому приложению Спарк запрашивать исполнителей во время выполнения, когда есть ожидающие задачи, и удалять их, когда они простаивают. Динамическое размещение доступно в Kubernetes с версии Спарк 3.0 через установку в значение TRUE конфигураций Spark.dynamicAllocation.enabled и spark.dynamicAllocation.shuffleTracking.enabled.
- автомасштабирование на уровне кластера, когда кластер Kubernetes может запрашивать больше узлов у облачного провайдера, если нужно планировать дополнительные поды, и наоборот, удалять узлы, которые не используются.
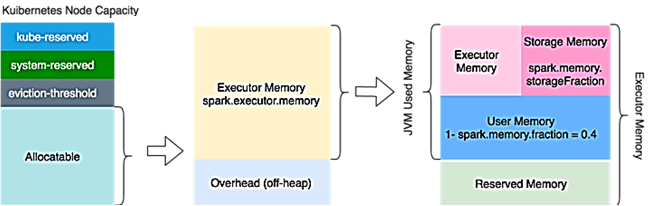
Управление памятью в Kubernetes
Узлы Kubernetes обычно запускают множество системных служб (демонов) операционной системы в дополнение к сервисам Kubernetes. Они потребляют много ресурсов и их доступность критична для стабильности узлов K8s [3]:
- Kubelet предоставляет Node Allocatable, чтобы зарезервировать системные ресурсы для критических демонов;
- с kube-reserved можно зарезервировать вычислительные ресурсы для kubelet, среды выполнения контейнера и пр.
- system-reserved позволяет зарезервировать ресурсы для sshd, udev и т.д.;
- с помощью параметра Allocatable можно зарезервировать вычислительные ресурсы для подов.
По умолчанию Kubernetes выделяет память с помощью контрольных групп на основе запроса/ограничения, заданного в определении пода с конфигурацией spark.executor.memory. Еще Kubernetes учитывает spark.kubernetes.memoryOverheadFactor или минимум 384 МБ в качестве дополнительной памяти, отличной от JVM, включая выделение памяти вне кучи, а также задачи, не связанные с JVM, и различные системные процессы. Изменить настройки по умолчанию и переопределить это поведение, можно, задав конфигурации spark.executor.memoryOverhead требуемое значение.
Для настроек кучи Spark в Kubernetes рекомендуется задать значения -Xms (минимальная куча) и -Xmx (максимальная куча) равными параметру spark.executor.memory. В этом случае Xmx чуть меньше предела памяти пода, что помогает избежать отказа исполнителей из-за ошибок OOM (OutOfMemory), о которых мы рассказывали здесь. Напомним, при запуске Spark-приложений на Kubernetes под отказывает из-за ошибок OOM по следующим причинам [3]:
- когда Spark-приложение потребляет больше памяти кучи (Xmx), ядро ОС контейнера уничтожает Java-программу;
- если используемая память превысила лимит пода (memory.limit), то контрольная группа ОС хоста уничтожает контейнер, а Kubelet пытается перезапустить его на том же или другом хосте;
- если рабочие узлы испытывают нехватку памяти, Kubelet попытается уничтожить случайные поды, чтобы освободить память. Причем это не обязательно означает, что будут уничтожены только те поды, которые потребляют больше памяти.
Избежать этих OOM-ошибок позволит непрерывный мониторинг потребления памяти Spark, включая отслеживание метрик памяти (container_memory_cache и container_memory_rss), например, через cadvisor в Prometheus или в аналогичных решениях для администратора Big Data кластера.
Далее мы рассмотрим еще один важный фактор оптимизации Spark-приложений в кластере Kubernetes с точки зрения затрат на облачные сервисы. Читайте в следующих статьях, что такое спотовые или вытесняемые узлы и как эффективно выполнять миллиардов операций на AWS S3.
Как разрабатывать высокоскоростные приложения аналитики больших данных с Apache Spark, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники