Вчера мы рассказывали, почему важна наблюдаемость данных какие платформы помогают комплексно обеспечить все ее аспекты. В продолжение этой темы сегодня заглянем под капот происхождения данных в Apache Spark с помощью агента Spline и других способов.
Трудности data lineage в Apache Spark
Когда конвейер данных выходит из строя, дата-инженеру нужно скорее понять, где произошел сбой и на что он повлиял. Время простоя данных дорого обходится. Без знаний о происхождении данных (data lineage) сортировка инцидентов и анализ основных причин занимает много времени. Data lineage выступает наглядной картой того, как данные связаны и перемещаются в течение своего жизненного цикла. На практике отследить происхождение данных в сложных распределенных конвейерах на базе Apache Spark не самая тривиальная задача. Spark поддерживает несколько различных API для создания заданий на языках Scala, Python или R, которые интерпретируются и компилируются в команды. После этого Spark создает направленный ациклический граф выполнения (DAG, Directed Acyclic Graph) всех последовательных шагов для чтения данных из источников данных, выполнения ряда преобразований и записи их в место выхода. Это делает DAG эквивалентом плана выполнения SQL-запроса, который содержит всю информацию о происхождении данных.
Spark имеет внутреннюю структуру под названием QueryExecutionListeners, которую можно настроить для прослушивания событий, когда команда выполняется, а затем передать эту команду слушателю – специальному перехватчику событий, о чем мы писали здесь. Так можно увидеть исходный код реализации слушателя, используемого агентом прослушивания с открытым исходным кодом. Именно эта идея лежит в основе некоторых платформ класса data observability, в частности, Monte Carlo. С помощью агента Spark для прослушивания внутренних событий, выполняется захват метаданных происхождения данных и преобразования их в формат графа, т.е. плана выполнения запроса. Далее это представление плана выполнения отправляется в шлюз интеграции (Integration Gateway), а затем в нормализатор, который преобразует его во внутреннее представление платформы Monte Carlo о происхождении события. Эти данные интегрируются с другими источниками происхождения данных и метаданных, чтобы обеспечить единое сквозное представление для каждого клиента.
Разработчики Monte Carlo отмечают изящность данного решения, но подчеркивают его недостатки из-за сильной привязки к специфике Scala-кода, когда способ добавления файлов JAR в путь к классам среды выполнения Spark зависит от того, как и где клиенты выполняли свои задания и какие комбинации версий Scala и Spark там использовались. Вторая проблема в том, что, как и операторы SQL, словарь команд Spark постоянно расширяется. И каждый раз, когда вводится новая команда, необходимо писать код для извлечения метаданных происхождения из нее. Это затрудняет парсинга агента слушателя Spark с командами, которые еще не поддерживались. Поэтому разработчики платформы Monte Carlo делают собственное решение, о котором мы расскажем в другой раз. А пока более подробно рассмотрим, как отследить происхождение данных в Spark с помощью типового способ через агента Spline.
Зачем вам Spline и как он работает
Spline — это бесплатный инструмент с открытым исходным кодом для автоматического отслеживания происхождения данных и структуры конвейера данных. Spline расшифровывается как Spark Lineage — изначально он создавался как инструмент отслеживания происхождения специально для Apache Spark. Однако, после 2018 года видение проекта было расширено, а конструкция системы была адаптирована для использования с другими технологиями обработки данных, а не только со Spark. Сегодня Spline – это кроссплатформенное решение для отслеживания происхождения данных, которое можно использовать для управления данными. Помимо UI, Spline состоит из 2-х основных частей:
- сервер, который получает сведения о происхождении данных от агентов через API продюсера и сохраняет их в свободной мультимодельной СУБД ArangoDB. Сервер также предоставляет API потребителя для чтения и запроса сведений о происхождении данных. API потребителя используется пользовательским интерфейсом Spline и сторонними приложениями.
- агент собирает метаданные происхождения из конвейеров преобразования данных и отправляют их на сервер Spline в стандартизированном формате через кросс-платформенный API продюсера с использованием HTTP (REST) или Kafka в качестве транспорта. В настоящее время доступен только агент для Apache Spark, который мы подробно рассмотрим далее.
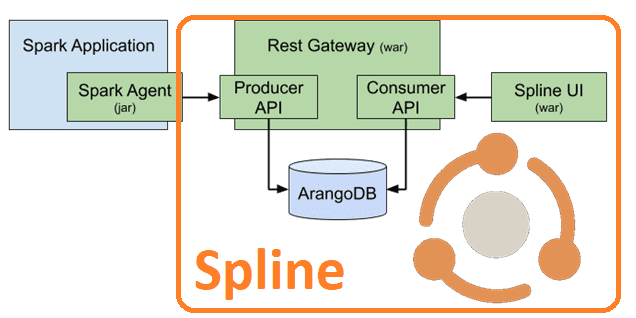
Агент Spline для Apache Spark — это дополнительный модуль к проекту Spline, который собирает информацию о происхождении данных во время выполнения из заданий Spark. Агент представляет собой библиотеку Scala, встроенную в драйвер Spark, которая прослушивает события Spark-задания и собирает логические планы выполнения. Затем собранные метаданные передаются диспетчеру происхождения, откуда их можно либо отправить на сервер Spline, например, через REST API или Kafka, или использовать по-другому, в зависимости от выбранного типа диспетчера. Агент можно использовать с сервером Spline или без него.
Агент Spline Spark следует принципам семантического управления версиями. Общедоступный API определяется как набор классов точек входа (SparkLineageInitializer, SplineSparkSessionWrapper), API расширений (подключаемых модулей, фильтры, диспетчеры), свойств конфигурации и набора поддерживаемых версий Spark. Другими словами, общедоступный API агента Spline Spark охватывает все сущности и абстракции, предназначенные для использования или расширения клиентскими приложениями.
Номер версии напрямую не отражает отношение Агента к API продюсера и серверу Spline. И сервер Spline, и агент спроектированы так, чтобы быть максимально совместимыми друг с другом, предполагая долгосрочную работу и разрыв в датах выпуска сервера и агента. Такое требование продиктовано характером агента, который может быть встроен в некоторые задания Spark и обновляться очень редко или вообще никогда без риска прекращения работы из-за возможного обновления сервера Spline. Аналогично, есть возможность обновить агент в любое время, например, для исправления ошибки или поддержки более новой версии Spark или функции, которую не поддерживала более ранняя версия агента без необходимости обновления сервера Spline.
В агенте есть 2 основных артефакта:
- agent-core —библиотека Java, которую можно использовать с любой совместимой версией Spark. Она нужна, чтобы включить агент Spline в пользовательское приложение Spark и самостоятельно управлять всеми транзитивными зависимостями.
- spark-spline-agent-bundle — JAR-файл, который предназначен для встраивания в драйвер Spark путем его копирования вручную в каталог /jars или с использованием аргумента —jars или —packages для spark-submit, команды spark-shell или pyspark. Этот артефакт самодостаточен и предназначен для использования большинством пользователей.
Поскольку пакет предварительно собран со всеми необходимыми зависимостями, важно выбрать правильную его версию, которая соответствует дополнительным версиям Spark и Scala целевой среды развертывания распределенного приложения.
Поскольку агент Spline является слушателем запросов, его необходимо зарегистрировать в сеансе Spark, прежде чем его можно будет использовать. Самая простая инициализация – это включить включите слушатель Spline в свойство конфигурации spark.sql.queryExecutionListeners:
pyspark \ --packages za.co.absa.spline.agent.spark:spark-2.4-spline-agent-bundle_2.12:<VERSION> \ --conf "spark.sql.queryExecutionListeners=za.co.absa.spline.harvester.listener.SplineQueryExecutionListener" \ --conf "spark.spline.lineageDispatcher.http.producer.url=http://localhost:9090/producer"
Тот же подход работает для команд spark-submit и spark-shell. При этом все свойства Spline, установленные через Spark conf, должны иметь префикс spark., чтобы быть видимым для агента Spline. Начиная со Spline 0.6, большинство компонентов агента можно настраивать или даже заменять декларативным образом c помощью конфигурации или Plugin API. Также есть возможность использовать метод программной инициализации:
// given a Spark session ... val sparkSession: SparkSession = ??? // ... enable data lineage tracking with Spline import za.co.absa.spline.harvester.SparkLineageInitializer._ sparkSession.enableLineageTracking() // ... then run some Dataset computations as usual. // The lineage will be captured and sent to the configured Spline Producer endpoint.
Анализ данных с Apache Spark
Код курса
SPARK
Ближайшая дата курса
13 мая, 2024
Продолжительность
32 ак.часов
Стоимость обучения
96 000 руб.
Агент ищет свойства конфигурации в следующих источниках (в порядке приоритета):
- конфигурация Hadoop (файл core-site.xml);
- Конфигурация Spark;
- системные свойства JVM;
- файл spline.properties в пути к классам. Файл spline.default.properties содержит значения по умолчанию для всех свойств сплайна, а также дополнительную документацию.
Трейт LineageDispatcher отвечает за отправку захваченной информации о происхождении данных. По умолчанию используется HttpLineageDispatcher, который отправляет данные о происхождении в конечную точку REST Spline. В Splie доступны следующие диспетчеры:
- HttpLineageDispatcher — отправляет lineage по HTTP;
- KafkaLineageDispatcher — отправляет родословную через Kafka;
- ConsoleLineageDispatcher — отправляет lineage в консоль;
- LoggingLineageDispatcher — отправляет lineage в лог;
- CompositeLineageDispatcher — позволяет объединить несколько диспетчеров.
Каждый диспетчер может иметь разные параметры конфигурации. Чтобы конфиги были четко разделены, у каждого диспетчера есть свое пространство имен, в котором определены все его параметры.
В заключение отметим, что используя API-интерфейс плагина, можно получить происхождение данных от стороннего провайдера. Spline автоматически обнаруживает плагины, сканируя путь к классам, поэтому для регистрации и настройки плагина не требуется никаких специальных действий. Все, что нужно, это создать класс, расширяющий трейт маркера za.co.absa.spline.harvester.plugin.Plugin, смешанный с одним или несколькими трейтами *Processing. Общие трейты:
- DataSourceFormatNameResolving — возвращает имя используемого провайдера/формата данных;
- ReadNodeProcessing — обнаруживает команду чтения и собирает метаинформацию;
- WriteNodeProcessing — обнаруживает команду записи и собирает метаинформацию;
Есть также два дополнительных трейта, которые обрабатывают распространенные случаи чтения и записи:
- BaseRelationProcessing — аналогичен ReadNodeProcessing, но вместо захвата всех узлов логического плана реагирует только на LogicalRelation;
- RelationProviderProcessing — похож на WriteNodeProcessing, но захватывает только
Ожидается, что класс плагина будет иметь только один конструктор. Конструктор может не иметь аргументов или иметь один или несколько из следующих типов (значения будут автоматически связаны):
- SparkSession;
- PathQualifier;
- PluginRegistry.
Для использования надо скомпилировать свой плагин и поместить его в путь к классам Spline/Spark. Как прервать DAG lineage в Apache Spark и зачем это нужно, читайте в нашей новой статье.
Узнайте больше практических деталей по применению Apache Spark для задач дата-инженерии, разработки распределенных приложений и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

