
Сегодня поговорим про основные программные компоненты и принципы работы Apache AirFlow: как DAG состоит из задач, в чем разница между операторами и датчиками, зачем нужны правила триггеров, а также каким образом фреймворк защищает переменные.
DAG и задачи: зависимости, состояния, триггеры
Основной концепцией Apache AirFlow является DAG – направленный ациклический граф, который представляет собой набор задач с отношениями и зависимостями друг от друга. Каждая задача – это событие в рабочем процессе или конвейере обработки данных, которое может выполнять различные операции. В AirFlow каждый DAG написан на Python, что снижает порог входа в технологию и решает проблему с интеграциями различных систем. Будучи интерпретируемым языком, Python-код может работать в самых разных средах. Визуально этот Python-код представляется в пользовательском интерфейсе с помощью сеток, графов, календарей и даже диаграмм Ганта.
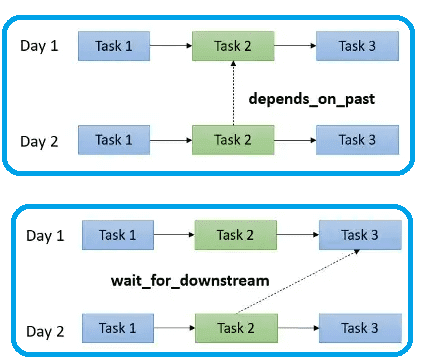
Задачи в DAG могут зависеть руг от друга, быть параллельными и передавать информацию между собой. Если задача зависит от предыдущей, она считаются дочерней по отношению к родительской (вышестоящей). Можно сказать, что в DAG-графе зависимости между задачами представляют собой направленные ребра, которые определяют, как идет перемещение по этому направленному графу. Именно зависимости являются ключом к определению гибких конвейеров обработки данных. Можно установить зависимость между задачами, используя методы set_downstream и set_upstream. Также можно установить зависимость между задачами в текущем и предыдущем запусках DAG:
- depend_on_past в значении true определяет, что задача в текущем запуске DAG будет выполняться только в том случае, если та же задача была успешно выполнена или была пропущена при предыдущем запуске;
- wait_for_downstream в значении true определяет, что задача в текущем запуске будет выполняться только в том случае, если та же задача была успешно выполнена или пропущена в предыдущем запуске, а непосредственная нижестоящая задача в предыдущем запуске также была выполнена или была пропущена.
Каждая задача в AirFlow имеет одно из следующих состояний в любой момент времени:
- none — задача еще не поставлена в очередь на выполнение, а ее зависимости еще не выполнены;
- scheduled — планировщик определил, что зависимости задачи выполнены, и она должна быть запущена;
- queued — задача поставлена в очередь, назначена исполнителю и ожидает worker’а;
- running – задача выполняется на worker’е или на локальном/синхронном исполнителе;
- success – задача завершена без ошибок;
- failed — во время выполнения задачи произошла ошибка, и ее не удалось запустить;
- skipped – задача была пропущена из-за ветвления или другого условия;
- upstream_failed – не удалось выполнить восходящую задачу, но правило триггера говорит, о ее необходимости;
- up_for_retry – задачу не удалось выполнить, но остались попытки повторной попытки, и она будет перепланирована;
- up_for_reschedule — задача представляет собой датчик в режиме перепланирования.
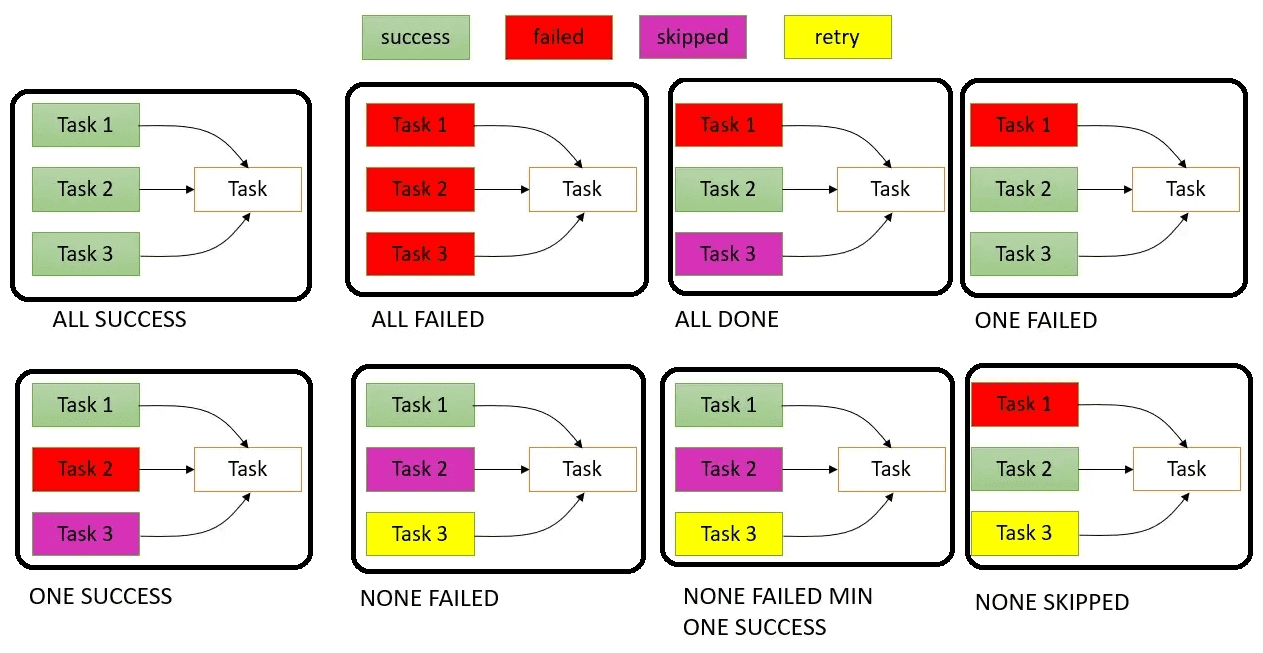
Задача меняет свое состояние в зависимости от правила ее триггера. Если не нужно, чтобы задача запускалась исключительно при условии успешного выполнения вышестоящей, можно установить правило запуска. Правило триггера выводит меняет поведение задачи, особенно если в DAG есть ветвления. По умолчанию все задачи имеют правило триггера all_success. Это означает, что все вышестоящие родительские задачи должны быть успешными, прежде чем запускать дочерние. Но, когда есть определенный уровень SLA (соглашение об уровне обслуживания), задачам может быть присвоено значение времени ожидания для конвейера данных, чтобы соответствовать ожиданиям доставки. Вообще в Apache AirFlow есть следующие правила триггеров:
- all_success (по умолчанию) – зависимая задача будет выполняться, если все вышестоящие задачи выполнены успешно, не удались или пропущенная задача приведет к тому, что зависимая задача будет пропущена. Родительскими задачами здесь считаются все успешные восходящие задачи.
- all_failed – зависимая задача запускается, когда все вышестоящие задачи находятся в состоянии сбоя или upstream_failed;
- all_done – зависимая задача запускается, когда все вышестоящие задачи выполнены с их выполнением, успехом, неудачей или пропуском, не имеет значения. Их выполнение должно быть завершено. В этом случае количество восходящих задач меньше или равно количеству успешных, неудачных, upstream_failed или пропущенных задач.
- one_failed – зависимая задача запускается при сбое хотя бы одной вышестоящей задачи, не ожидая выполнения всех вышестоящих задач;
- one_success – зависимая задача запускается, когда успешно выполнена хотя бы одна вышестоящая задача, не ожидая выполнения всех вышестоящих задач;
- none_failed – зависимая задача запускается только в том случае, если все вышестоящие задачи не завершились ошибкой или находятся в состоянии upstream_failed, то есть все вышестоящие задачи выполнены успешно или были пропущены.
- none_failed_min_one_success — зависимая задача запускается только в том случае, если все вышестоящие задачи не завершились ошибкой или upstream_failed и хотя бы одна вышестоящая задача завершилась успешно.
- none_skiped – зависимая задача запускается только тогда, когда ни одна вышестоящая задача не находится в состоянии пропуска, т. е. все вышестоящие задачи находятся в состоянии успеха, сбоя или upstream_failed.
Про лучшие практики работы с XCom-объектами и правилами триггеров вы узнаете в нашей новой статье.
Обратные вызовы и операторы Apache AirFlow
Обратный вызов (callback) предоставляет способ действовать при изменении состояния отдельной задачи или всего DAG. Есть три способа использования обратного вызова:
- через инициализацию DAG, когда действие или функция будет вызываться после выполнения всех конечных задач;
- через инициализацию задачи, когда действие или функция будет вызвана после выполнения задачи;
- через аргументы по умолчанию, которые передаются в оператор ALL как аргументы ключевого слова.
Есть 5 основных обратных вызовов: on_execute_callback, on_success_callback, on_retry_callback, on_failure_callback и sla_miss_callback. Эти обратные вызовы определяются на уровне задачи или DAG. Как это может пригодиться на практике, мы разбираем на практических примерах здесь и здесь.
Также AirFlow предоставляет механизм для некоторых действий перед выполнением задачи (операторский метод execute) на уровне оператора через хуки (перехватчики, hooks), которые вызываются до того, как будет выполнена фактическая функция выполнения. Различают три типа хуков:
- pre_execute, что вызовет нужную функцию до того, как начнется фактическая задача. Это полезно, если нужно пропустить некоторые задачи для определенных запусков DAG без нарушения зависимостей;
- post_execute – вызов функции по завершении задачи;
- on_kill используется для очистки ресурсов, таких как потоки или процессы и пр.
Операторы AirFlow позволяют иметь разные типы задач с разной функциональностью. Например, BashOperator выполняет команду bash, PythonOperator — вызывает UDF- функцию Python, EmailOperator отправляет электронное письмо, а SimpleHttpOperator — обращается к конечной точке указанным методом HTTP (POST, GET и пр.).
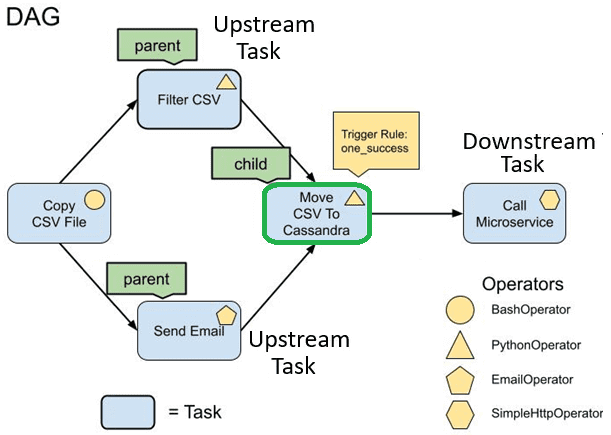
Датчики или сенсоры – это специальный вид операторов, которые просто ждут, пока произойдет определенное действие, например копирование файла или завершение рабочей нагрузки в Kubernetes. Подробнее о том, как они устроены, мы писали здесь и здесь. А в этой статье вы узнаете, почему с версии AirFlow 2.4 от поддержки интеллектуальных датчиков было решено отказаться.
Для работы операторов AirFlow дата-инженер должен настроить соединения в DAG и использовать переменные. Соединения — это объекты для хранения учетных данных и другой информации, необходимой для подключения к внешним службам. Можно настроить соединения к базам данных, конечным точкам HTTP, FTP-серверам и пр. Настройка этих соединений выполняется в пользовательском интерфейсе AirFlow.
Переменные — это общий способ хранения и извлечения произвольного контента или настроек в виде простого значения ключа, хранящегося в AirFlow. Хранить информацию в переменных можно в виде тела ответа или ключа API, имени сред или счетчика. AirFlow имеет встроенную защиту при использовании переменных: они автоматически шифруются с помощью Fernet, и фреймворк предоставляет возможность использования бэкэнда Secrets для дополнительной безопасности.
Еще одним полезным программным компонентом Apache AirFlow является библиотека DAGFactory, которая упрощает процессы разработки DAG, позволяя использовать YAML-формат вместо Python-кода. Поскольку YAML — это человеко-читаемый язык сериализации данных, библиотека DAGFactory преобразует YAML-файл в Python-код, повышая степень универсализации AirFlow до платформы, которую можно использовать во всей компании, а не только в дата-инженерии.
Наконец, в Apache AirFlow можно использовать REST API, чтобы включить его в современную архитектуру микросервисов. Это позволяет выполнять множество операций, от CRUD-действий над объектами, до запуска и мониторинга DAG, доступа к журналам, задания переменных и установки соединений.
Освойте приемы администрирования и эксплуатации Apache AirFlow для дата-инженерии и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

