
Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим особенности обработки пакетных транзакций в популярной графовой СУБД Neo4j . Когда вместо простых запросов встроенного SQL-подобного языка Cypher лучше использовать процедуры библиотеки APOC, чтобы избежать проблем с памятью или остановки обновлений.
OOM, большие графы и пакетные транзакции в Neo4j
При работе с массивными графами в Neo4j можно столкнуться с ошибкой OOM (Out Of Memory), когда заканчивается память кучи. Избежать этого помогут пакетные транзакции, работать с которыми можно через запросы встроенного в Neo4j SQL-подобного языка запросов Cypher, разделив один запрос Cypher на несколько транзакций.
Рассмотрим пример небольшого графа из датасета Paradise Paradise ICIJ по оффшорным компаниям и трастам. Нас интересуют только оффшоры (зеленые) и трасты (оранжевые), а также отношения OFFICER_OF между ними. По сути, это биграф или двудольный граф с двумя типами узлов. В узлы, т.е. вершины биграфа, можно разбить на 2 части так, что каждое отношение (ребро) соединяет вершину из одной части с какой-то вершиной другой части. В двудольных графах не существует рёбер между вершинами одной и той же части графа. На практике двудольные графы естественно возникают при моделировании отношений между двумя различными классами объектов. Например, граф футболистов и клубов, где ребрами соединяют спортсмена и клуб, если спортсмен играл в этом клубе. Также двудольные графы часто используются в теории кодирования.
При анализе двудольных графов обычно их сперва преобразуют в однодольные. В нашем примере спроецируем двудольный графа в однодольный из оффшоров, а отношения между ними будут определять, есть ли у них общие объекты и сколько.
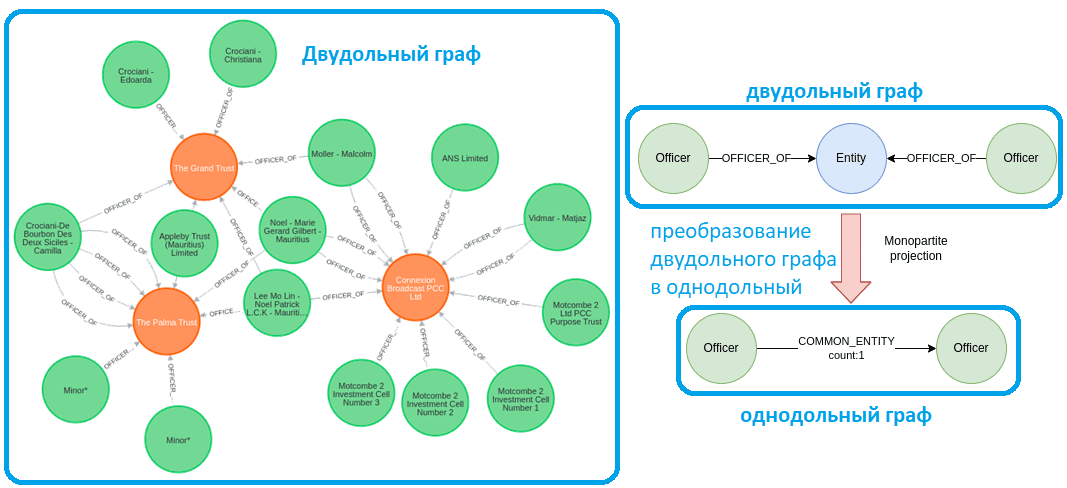
Такое преобразование в графовой СУБД Neo4j выполняется через довольно простой Cypher-запрос сопоставления шаблонов и посчитать подходящие случаи. При желании можно сохранить результаты как отношения между оффшорами.
MATCH (n:Officer)-[:OFFICER_OF]->(:Entity)<-[:OFFICER_OF]-(m)// avoid duplication WHERE id(n) < id(m)// count the number of occurrences per pair of node WITH n,m, count(*) AS common// return the total number of rows RETURN count(*) AS numberOfRows
Даже в небольшом однодольном графе может быть множество отношений, каждое из которых имеет вес, и все эти данные необходимо сохранить. Но , Neo4j Sandbox — бесплатный облачный экземпляр базы данных Neo4j, который поставляется с предустановленными плагинами, имеет только 1 ГБ динамической памяти. Поэтому создание более миллиона взаимосвязей в одной транзакции может привести к проблемам с памятью. Следовательно, нужно увеличить значение времени ожидания транзакции. По умолчанию экземпляры Sandbox имеют время ожидания транзакции 30 секунд. Это означает, что если транзакция длится дольше 30 секунд, она будет автоматически завершена. Избежать этого поможет установка следующей конфигурации времени ожидания транзакции:
CALL dbms.setConfigValue(‘dbms.transaction.timeout’,’0′);
Здесь в Neo4j можно воспользоваться процедурой apoc.periodic.iterate, которая часто используется для пакетной обработки транзакций:
CALL apoc.periodic.iterate( // first statement
"MATCH (n:Officer)-[:OFFICER_OF]->()<-[:OFFICER_OF]-(m)
WHERE id(n) < id(m)
WITH n,m, count(*) AS common
RETURN n,m, common",
// second statement
"MERGE (n)-[c:COMMON_ENTITY_APOC]->(m)
SET c.count = common",
// configuration
{batchSize:50000})
В первом операторе представляется поток данных для работы, который может состоять из миллионов строк. Второй оператор выполняет фактическое обновление. В нашем случае это создаст новые отношения между парой оффшоров и сохранит количество в качестве веса отношений. Определив размер пакета через параметр batchSize в конфигурации, можно записать количество строк, которые должны быть зафиксированы в одной транзакции. Например, если задать для параметра batchSize значение 50 000, транзакция будет зафиксирована после 50 000 выполнений второго оператора.
В Neo4j 4.4 пакетная обработка транзакций была представлена как собственная функция Cypher. Для пакетных транзакций, использующих только Cypher, надо определить подзапрос, который обновляет граф, за которым следует IN TRANSACTIONS OF X ROWS.
:auto MATCH (n:Officer)-[:OFFICER_OF]->()<-[:OFFICER_OF]-(m)
WHERE id(n) < id(m)
WITH n,m, count(*) AS common
CALL {
WITH n,m,common
MERGE (n)-[c:COMMON_ENTITY_CYPHER]->(m)
SET c.count = common} IN TRANSACTIONS OF 50000 ROWS
Выполняя приведенный выше оператор Cypher в браузере Neo4j, следует добавить команду :autocommand. Логика Cypher-запроса аналогично пакетной обработке APOC: сперва определяется поток данных (первый оператор), а затем используется подзапрос (второй оператор) для пакетной обработки больших обновлений. О том, какие еще возможности есть в библиотеке APOC, рассмотрим далее.
Библиотека APOC в Neo4j
APOC (Awesome Procedures on Cypher) — один из проектов Neo4j Labs. До релиза библиотеки APOC разработчикам нужно было писать свои собственные процедуры и функции для общих возможностей, которые Cypher или база данных Neo4j еще не поддерживали. При этом каждый разработчик писал свою собственную реализацию, что приводило к большому количеству различного кода с аналогичным назначением.
Поэтому один из разработчиков Neo4j Labs создал библиотеку APOC как стандартную служебную библиотеку для общих процедур и функций, чтобы коллеги из других команд и доменов могли использовать стандартную ее для общих процедур и писать свои собственные функции только для уникальной бизнес-логики и специфических потребностей.
Библиотека APOC считается самой большой и наиболее широко используемой библиотекой расширений для Neo4j. Она включает более 450 стандартных процедур, предоставляющих функциональные возможности для утилит, преобразований, обновления графов и пр. Все эти компоненты легко запускать как отдельные функции или включать в запросы Cypher. Поэтому перед разработкой собственной UDF для графовой аналитики больших данных рекомендуется сперва проверить наличие готовой функции в библиотеке APOC.
Рассмотрим наиболее часто используемые процедуры в APOC и их практическое применение в реальных сценариях:
- date.format(dateForConversion, [timeUnit], [format]) — преобразование значения времени эпохи в желаемый формат. Пригодится для вывода в отчеты, отображения в веб-интерфейсе, включения в URL-адрес в качестве параметра и т.д. Некоторые функции даты/времени вошли в Neo4j 3.4 как часть основного продукта. Поэтому для версии Neo4j не ниже 3.4 специально обращаться к библиотеке APOC уже не нужно.
- load.json(url) — загрузка данных из URL-адреса или файла в формате JSON и использование операторов Cypher для создания или обновления данных в Neo4j. Отлично подходит для вызова API и сброса полученных данных в Neo4j. Другие аналогичные процедуры существуют в apoc.load.jdbc для прямого подключения JDBC к базе данных, apoc.load.xml — для XML-данных и apoc.load.csv для CSV-файлов.
- periodic.iterate(query1, query2, {param1: value1}) — используется как пакетный загрузчик, чтобы получить список результатов в первом запросе, а затем выполнить другой запрос для результатов query1, чтобы обновить каждый из них или получить для него другие данные. Можно установить параметры для размера пакета, переменных, количества повторных попыток и т. д. Существует несколько вариантов этой процедуры для запуска фоновых процессов, управления потоками и фиксации/отправки/отмены процессов.
Что и когда выбирать: процедуры APOC vs транзакционные Cypher-запросы
Хотя APOC все равно использует Cypher, существенное различие между ними заключается в обработке ошибок. Если одно выполнение в пакете дает сбой, то происходит сбой всего пакета, независимо от варианта: APOC или Cypher. Но нативный Cypher-запрос не будет продолжать операцию после сбоя одного пакета, и все ранее успешно зафиксированные транзакции будут отменены. Например, если третья транзакция не удалась, предыдущие две, которые были успешно зафиксированы, откатятся назад.
В этом случае лучше выбрать вариант APOC, где нет проблем в случае сбоя промежуточной партии. Запрос будет выполнять итерацию по всем пакетам независимо от сбоя в одном из них. Кроме того, APOC также имеет возможность определять повторные попытки в случае неудачного пакета, чего не хватает в пакетной обработке транзакций Cypher.
Например, при обновлении узлов через внешний API, подойдет процедура apoc.periodic.iterate со значением batchSize равным 1. Поскольку внешние API непредсказуемы и обращение к ним может стоить дорого, нужно хранить всю полученную из API информацию и перебирать все узлы, независимо от того, произошли ли какие-либо обновления между ними.
Кроме того, процедура apoc.periodic.iterate дает возможность параллельного запуска операторов обновления. В этом случае сначала нужно убедиться в отсутствии взаимоблокировок при выполнении параллельных обновлений или выполнение транзакции не будет выполнено. Как правило, при создании отношений нельзя использовать параллельное выполнение, потому что запрос может попытаться создать несколько отношений, начинающихся или заканчивающихся одним и тем же узлом, что приведет к взаимоблокировке узла и неудачному выполнению. Но при обновлении одного свойства узла за один раз, взаимоблокировки не возникнут. Поэтому при сохранении степени узла как его свойства, параллельное выполнение будет отличным вариантом.
CALL apoc.periodic.iterate(
"MATCH (o:Officer)
RETURN o",
"WITH o, size((o)--()) AS degree
SET o.degree = degree",
{batchSize:10000, parallel: true})
Таким образом, процедуру apoc.periodic.iterate из библиотеки APOC хорошо подходит для пакетных транзакций вместо собственной пакетной обработки Cypher, если нет требования немедленно завершить операцию после хотя бы одного неудачного пакета. Читайте в нашей новой статье по рефакторинг модели данных Neo4j с помощью библиотеки APOC и плагина Liquibase.
Больше практических примеров использования Neo4j и других инструментов графовой аналитики больших данных для реальных бизнес-задач вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
Источники

