
Интеграционный движок Kafka Engine для потоковой загрузки данных в ClickHouse из топиков Кафка – наиболее популярный инструмент для связи этих Big Data систем. Однако, он не единственное средство интеграции Кликхаус с Apache Kafka. Сегодня рассмотрим, как еще можно организовать потоковую передачу больших данных от самого популярного брокера сообщений в колоночную аналитическую СУБД от Яндекса.
От Kafka Streams до JDBC-драйвера: варианты интеграции ClickHouse с Кафка
Прежде всего отметим, что именно Kafka Engine является «официальным» средством интеграции ClickHouse с Apache Kafka, которое рекомендует Яндекс, изначальный разработчик колоночной аналитической СУБД. В технической документации на свой продукт компания приводит перечень библиотек для интеграции с внешними системами от сторонних разработчиков, уточняя, что не занимается их поддержкой и не гарантирует их качества. Одним из таких средств, указанных в этом разделе официальной документации, является коллекция библиотек Stream loader [1].
Она используется для загрузки данных из Kafka в произвольные хранилища: HDFS, S3, ClickHouse или Vertica, используя семантику строго однократной доставки (exactly once). С помощью Stream loader можно самостоятельно реализовать различные настраиваемые загрузчики, комбинируя готовые компоненты для форматирования и кодирования записей, хранения данных, группировки потоков и пр. [2].
Также в официальной документации перечисляется еще одно стороннее приложении для интеграции с Apache Kafka – Clickhouse_sinker. В нем не нужно писать программный код, т.к. достаточно задать все требуемые параметры в конфигурационных файлах. Clickhouse_sinker использует Go-клиент и собственный протокол TCP-клиент-сервер ClickHouse с более высокой производительностью, чем HTTP [3].
Наконец, для полного контроля над процессом потоковой заливки данных из Кафка в Кликхаус разработчик Big Data может написать собственный Java-код и использовать ClickHouse JDBC драйвер [4]. Для реализации соединения по JDBC ClickHouse использует отдельную программу clickhouse-jdbc-bridge, которая должна запускаться как системная служба (демон). Она предназначена для передачи SQL-запросов из ClickHouse во внешние СУБД [5].
В контексте создания собственных интеграционных решений также следует упомянуть Apache Kafka Streams – клиентскую библиотеку для разработки приложений и микросервисов, в которых входные и выходные данные хранятся в кластерах Кафка. Подробнее о Apache Kafka Streams мы рассказывали здесь.
Построение хранилища данных на базе Clickhouse
Код курса
CLICH
Ближайшая дата курса
3 июня, 2024
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Кейс компании Ситимобил или зачем к Кликхаус прибавили Exasol
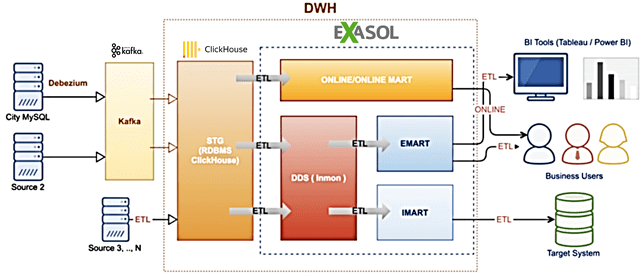
Изначально Ситимобил, крупный отечественный сервис для заказа такси, использовал комбинацию ClickHouse с Apache Kafka и еще несколько open-sourse технологий стека Big Data (MySQL, Apache AirFlow). Но в 2019 году компания начала активную экспансию в регионы РФ, что привело к многократному росту объема данных (более 30 Тб). Чтобы обеспечить непротиворечивость информации и оперативную аналитику Big Data для своих бизнес-пользователей, компания решила построить корпоративное хранилище данных (КХД), интегрированное с BI-системами Tableau и Power BI. Примечательно, что в этом решении ClickHouse выполняет роль операционного слоя первичных данных (стейджинг), в котором хранятся данные без предварительной обработки. В него загружаются данные как от сторонних внешних систем, так и из Apache Kafka, которая используется в качестве шины данных. Основной слой КХД с обработанными данными и витринами реализован на аналитической In-Memory MPP-СУБД Exasol [6]. Благодаря массивно-параллельной архитектуре, колоночному хранению данных и резидентным вычислениям в оперативной памяти, Exasol позволяет очень быстро выполнять SQL-запросы на больших данных, в т.ч. JOIN-операции [7].
Внедрение Exasol в Ситимобил состоялось в мае 2020 года. Дальнейшее развитие этого проекта предполагает хранение части стейджингового слоя в Exasol для оперативного доступа к первичным данным. Это позволит обеспечить высокую скорость получения данных из КХД, их полноту и достоверность, а также качество ETL-процессов [6]. Подробнее про состав и назначение послойной архитектуры КХД мы рассказывали здесь.
В следующей статье мы поговорим про основные достоинства ClickHouse и чем они обусловлены. Больше технических подробностей по интеграции Apache Kafka с другими внешними источниками для потоковой обработки больших данных вы узнаете на практических курсах по Кафка в нашем лицензированном учебном центре повышения квалификации и обучения руководителей и ИТ-специалистов (разработчиков, архитекторов, инженеров и аналитиков Big Data) в Москве:
- https://clickhouse.tech/docs/ru/interfaces/third-party/integrations/
- https://github.com/adform/stream-loader
- https://github.com/housepower/clickhouse_sinker
- https://www.altinity.com/blog/clickhouse-kafka-engine-faq
- https://clickhouse.tech/docs/ru/engines/table-engines/integrations/jdbc/
- http://www.tadviser.ru/index.php/Проект:Ситимобил_%28Exasol%29
- https://habr.com/ru/company/badoo/blog/271753/

