Дата-инженеры часто сталкиваются с изменением структуры конвейера обработки данных в Apache AirFlow, например, когда добавляются новые источники или приемники данных. Однако, менять DAG каждый раз при изменении внешних условий довольно утомительно. Читайте далее, как автоматизировать реорганизацию DAG, используя JSON, YAML-файл или другую плоскую структуру данных для хранения динамической конфигурации рабочего процесса.
Зачем нужно динамическое изменение DAG в Apache AirFlow и как это сделать
Мы уже писали, что при проектировании сложных конвейеров данных дата-инженер может столкнуться со случаями, когда после выполнения определенной задачи DAG разделяется на несколько вариантов, выбор одного из которых зависит от предыдущего результата или других условий. Аналогичным образом, возникает задача перепроектирования ETL-конвейера при изменении источников данных. Автоматизировать такое динамическое изменение DAG можно несколькими способами и использование плоского файла со структурированными данными далеко не единственный способ добиться динамического изменения пакетного конвейера обработки данных. Также можно использовать внешнюю базу данных для хранения информации о DAG, переменные AirFlow или переменные среды, вложенные операторы или генерировать Python-код со встроенной динамической конфигурацией. Подробнее обо всех этих способах читайте в нашей новой статье.
В качестве практического примера рассмотрим ETL-конвейер, который перемещает данные из разных источников в центральное хранилище. Сложность в том, что источники данных определяются только во время выполнения. Поэтому в DAG надо динамически создавать группы задач ETL для каждого источника данных, присутствующего во время выполнения. Предположим, DAG имеет следующую структуру, показанную далее на рисунке.
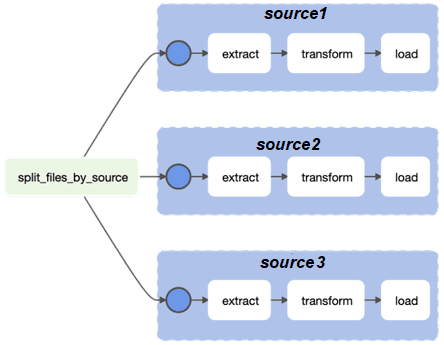
Можно настроить папку DAG следующим образом:
dags/ |- configs/ | |- sources.yaml |- .airflowignore |- etl_using_external_yaml_file_dag.py
Файл .airflowignore нужен, чтобы планировщик AirFlow знал, какие файлы или папки следует игнорировать при поиске файлов Python для анализа обновлений DAG. Это сократит время загрузки DAG и улучшит производительность. В нашем примере файл .airflowignore имеет следующее содержимое:
configs/.*
С помощью приведенной выше структуры проекта можно получить динамическую конфигурацию DAG из YAML-файла:
from pathlib import Path
import pendulum
import yaml
from airflow.decorators import dag
from airflow.operators.dummy import DummyOperator
from airflow.utils.task_group import TaskGroup
from operators.extract_operator import ExtractOperator
from operators.load_operator import LoadOperator
from operators.transform_operator import TransformOperator
DAG_ID = "etl_using_external_flat_file"
DAG_DIR = Path(__file__).parent
CONFIG_DIR = "configs"
SOURCES_FILE_NAME = "sources.yaml"
SOURCE_CONFIG_FILE_PATH = DAG_DIR / CONFIG_DIR / SOURCES_FILE_NAME
SOURCES = "sources"
@dag(
dag_id=DAG_ID,
start_date=pendulum.now(tz="Asia/Singapore"),
schedule_interval=None,
)
def create_dag():
split_files_by_source = DummyOperator(task_id="split_files_by_source")
source_config_file_path = Path(SOURCE_CONFIG_FILE_PATH)
sources = []
if source_config_file_path.exists():
with open(source_config_file_path, "r") as config_file:
sources_config = yaml.safe_load(config_file)
sources = sources_config.get(SOURCES, [])
for source in sources:
with TaskGroup(group_id=source) as task_group:
extract = ExtractOperator(task_id="extract", source=source)
transform = TransformOperator(task_id="transform", source=source)
load = LoadOperator(task_id="load", source=source)
extract >> transform >> load
split_files_by_source >> task_group
globals()[DAG_ID] = create_dag()
В вышеприведенном коде анализируется YAML-файла, чтобы получить список источников данных:
# configs/sources.yaml sources: - source1 - source2 - source3
Поскольку динамическая конфигурация ETL-конвейера теперь находится в файле, который хранится на том же компьютере, что и сами файлы DAG, нужен внешний процесс для внесения изменений в динамическую конфигурацию. Это может быть сделано непосредственно в файловой системе разработчиком вручную или через конвейер развертывания, что более предпочтительно, поскольку прямые изменения в файловой системе не сохраняют историю изменений.
Следующий пример показывает, как вносить динамические изменения конфигурации, используя другой DAG:
import pendulum
from airflow.decorators import dag
from constants import SOURCE_CONFIG_FILE_PATH
from operators.configure_sources_yaml_file_operator import ConfigureSourcesYamlFileOperator
DAG_ID = "configure_sources_yaml_file_dag"
@dag(
dag_id=DAG_ID,
start_date=pendulum.now(tz="Asia/Singapore"),
schedule_interval=None,
)
def create_dag():
ConfigureSourcesYamlFileOperator(
task_id="configure_sources_yaml_file",
sources_yaml_file_path=str(SOURCE_CONFIG_FILE_PATH),
)
globals()[DAG_ID] = create_dag()
После динамического изменения DAG можно работать с ним:
import yaml
from airflow.models import BaseOperator
from airflow.models.taskinstance import Context
SOURCES_KEY = "sources"
class ConfigureSourcesYamlFileOperator(BaseOperator):
def __init__(self, sources_yaml_file_path: str, *args, **kwargs):
super().__init__(*args, **kwargs)
self.sources_yaml_file_path = sources_yaml_file_path
def execute(self, context: Context):
if context["dag_run"] is None:
self.log.info("No DAG run config given. No change to sources YAML file")
return
run_config = context["dag_run"].conf
if run_config.get(SOURCES_KEY) is None:
self.log.warning(
f"DAG run config JSON does not contain the required key '{SOURCES_KEY}'"
)
return
with open(self.sources_yaml_file_path, "w") as config_file:
yaml.safe_dump(run_config, config_file)
Дополнительное преимущество этого приема в том, что сохраняется история изменений динамической конфигурации DAG, хотя не исключает ручного внесения изменений.
Подводя итог рассмотренному приему динамического обновления конфигураций DAG с помощью плоского YAML-файла, отметим, что он считается одной из лучших практик дата-инженерии в AirFlow. Его самым большим преимуществом является отсутствие дополнительной нагрузки на рабочую базу данных: извлечение динамической конфигурации выполняется исключительно на том узле, где запущен процесс планировщика AirFlow.
Однако, главный недостаток этого метода в том, что фактическое содержимое плоского файла с динамической конфигурацией DAG можно просмотреть только с помощью специализированных редакторов. Это слегка усложняет отладку динамического поведения DAG. Кроме того, применение динамических изменений может отражаться с некоторой задержкой, поскольку это обрабатывается AirFlow только после того, как планировщик проанализировал и сериализовал DAG. В AirFlow версии 2 планировщику потребуется сериализовать DAG и сохранить его в базе данных метаданных, откуда их извлекает веб-сервер и десериализует. Затем эти десериализованные DAG отображаются в пользовательском интерфейсе вместе с любыми обновлениями их рабочего процесса или расписания. А частота обновления зависит от конфигурации планировщика min_file_process_interval. В этом параметре задается количество секунд, по истечении которых файл DAG анализируется. Обновления DAG отражаются после этого интервала, по умолчанию раз в 30 секунд. При высокой частоте такого обновления возрастает нагрузка на ЦП.
Больше полезных приемов администрирования и эксплуатации Apache AirFlow для дата-инженерии и аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

