Сегодня мы поговорим о проектировании архитектуры корпоративных хранилищ данных (КХД) и рассмотрим, какие методы и инструменты используются для моделирования структуры DWH и динамики ETL-процессов. В этой статье про основы Data Modelling разберем, что такое OLAP и OLTP, почему 3-я нормальная форма стала стандартом в SQL-СУБД, чем схемы звезды отличается от снежинки, как подход Data Vault оптимизирует работу Apache Hadoop и какова польза всех этих методов для архитектора Big Data.
Краткий обзор методов моделирования данных
Все методы моделирования данных можно разделить на 2 группы: структурные и процессные. Реляционная парадигма, актуальная для типовых КХД, фокусируется на определении сущностей и взаимосвязей между ними, чтобы затем представить эти концепции в виде связанных таблиц с помощью ER-диаграмм (Entity-Relationship). Для описания потоков движения данных в бизнес-анализе используются DFD-диаграммы (Data Flow Diagram). DFD-схемы наглядно показывают обмен информацией между хранилищами данных (не в смысле КХД, а скорее, базы-источники, потребители и прочие места хранения), внутренними процессами системы и внешними по отношению к ней сущностями. Данный динамический метод можно использовать при концептуальном проектировании Big Data решений, когда определяются основные источники и потребители данных, а также процессы их обработки, в частности, ETL. Такая визуализация пригодится при проектировании современных КХД, интегрированных с озерами данных (Data Lake) и облачными сервисами расширенной аналитики Big Data. Это имеет отношение к новой гибридной архитектуре данных под названием LakeHouse, о чем мы рассказываем здесь.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
15 июля, 2024
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Возвращаясь к структурному дизайну DWH, отметим 3 наиболее распространенных метода моделирования [1]:
- многомерное для витрин данных и уровня ядра в LSA-архитектуре, когда потребности бизнес-пользователей в аналитике известны и корректно определены. При этом витрина данных считается не физическим слоем, а набором представлений ядра модели.
- реляционное (IDEF1X) для определения связей между таблицами КХД, BI-дэшбордами (витринами данных) и прочими целевыми системам, которые относительно стабильны и должны быть интегрированы с моделью ядра КХД.
- свод данных или Data Vault – гибридный подход, сочетающий достоинства третьей нормальной формы (3NF) и схемы звезды, которая используется в денормализованных КХД.
Инструментально все эти методы реализованы в виде различных CASE-средств, которые позволяют создавать ER-диаграммы и проверять их корректность. Часто они входят в состав платформ для создания DWH, например, как это сделано в SAP BW∕4 HANA.
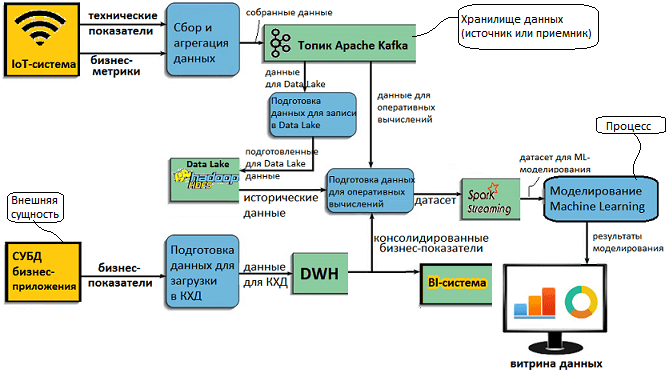
Как появился Data Vault или недостатки 3NF и звездных схем для КХД
Поскольку исторически DWH возникли из реляционных СУБД, они унаследовали также и подходы к проектированию, принятые в этой области. В частности, использование 3NF – третьей нормальной формы, когда каждый неключевой атрибут таблицы должен предоставлять информацию о лишь о полном ключе и ни о чём более. Напомним, в теории СУБД, нормальная форма – это совокупность требований, которым должно удовлетворять отношение, чтобы избежать избыточности, которая может привести к логически ошибочным результатам выборки или изменения данных. 3NF избавляет от транзитивных зависимостей: любой столбец таблицы зависеть только от ключевого столбца, что позволяет обеспечивать целостность данных в СУБД [2]. Этот подход был создан в 60-70хх гг. XX века Эдгаром Коддом (Edgar F. Codd) и Кристофером Дейт (Christopher J. Date) для систем оперативной обработки транзакций в реальном времени (OLTP, Online Transaction Processing). В начале 1980-х концепция 3NF была адаптирована для проектирования КХД, когда к первичным ключам каждой таблицы добавилась временная метка (date-time stamp). Однако такое применение этого подхода показало его следующие недостатки [3]:
- проблемы масштабируемости и гибкости из-за сильной связанности таблиц, когда добавление дополнительной родительской таблицы вызовет каскадные изменения всех нижележащих подчиненных таблиц. А при вставке новой строки с существующим родительским ключом все дочерние строки должны быть повторно переназначены на новый родительский ключ.
- зависимость первичного ключа от времени и от вышеупомянутой связанности таблиц;
- трудности загрузки в режиме near real-time;
- трудоемкие запросы;
- проектирование «сверху вниз» и соответствующая top-down (нисходящая) реализация.
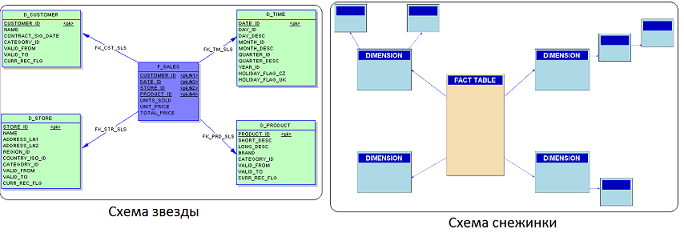
Чтобы обойти эти недостатки, со второй половине 1980-х в моделировании данных стала использоваться схема звезды (Star schema), удобная для хранения многомерных показателей. Именно эта модель лежит в основе витрин данных (Data Mart) – срезов КХД или реляционных OLAP-кубов в BI-системах для интерактивной аналитической обработки данных (Online analytical processing). При этом таблица фактов (центр звезды) содержит агрегированные данные для составления отчетов, а денормализованные таблицы измерений (лучи) описывает хранимые данные. Модификацию звездной схемы, когда отдельные таблицы измерений нормализованы с целью сокращения избыточности и определения всех зависимостей, называют «снежинкой». Она использует меньше дискового пространства и лучше сохраняет целостность данных. Недостаток снежинки в сложности запросов для доступа к данным из-за увеличенного числа соединений таблиц [4].
Предметно-ориентированные звездные схемы, приспособленные для мульти-предметных КХД, чтобы удовлетворить возрастающие потребности enterprise сектора в DWH-продуктах, называются согласованные витрины данных (Conformed Data Marts). По сути, согласованные витрины данных – это нескольких взаимосвязанных звездных схем, набор таблиц фактов, связанных через первичные/внешние ключи, о чем мы рассказываем здесь. Для этой модели также характерен ряд проблем, которые затрудняют ее применение в современных КХД [3]:
- изолированность предметно-ориентированной информации;
- возможная избыточность данных;
- несовместимые структуры запросов;
- трудности масштабируемости;
- несовместимая степень детализации таблиц фактов, которая усложняет их связывание, а также ограничивает дизайн, масштабируемость и гибкость модели данных;
- проблемы синхронизации при загрузках в режиме near real-time;
- ограниченные представления корпоративной информации;
- неудобная среда для интеллектуального анализа данных (Data Mining);
- необходимость проектирования «сверху вниз» с реализацией «снизу вверх».
Практическое применение Big Data аналитики для решения бизнес-задач
Код курса
PRUS
Ближайшая дата курса
17 июня, 2024
Продолжительность
32 ак.часов
Стоимость обучения
96 000 руб.
Чтобы исправить эти недостатки и сделать проектирование КХД более эффективным, в начале 2000-х годов была предложена модель Data Vault, основанная на реляционных принципах, нормализации данных и математике избыточности. В отличие от 3NF и звездных схем, она по-другому представляет отношения между сущностями, а также иначе структурирует поля таблиц и временные метки. Благодаря этому Data Vault может хранить больше детальных данных в меньшем физическом объеме, по сравнению с 3-ей нормальной формой и звездой [3]. Это преимущество актуально не только для реляционных сред, а сохраняется и в NoSQL-парадигме, когда данные могут храниться с использованием разных схем (хэш-таблицы, документы, графовые деревья, разреженные матрицы). Поэтому Data Vault позволяет сэкономить место и в HDFS, благодаря чему этот подход эффективен для построения не только КХД, но и для озер данных (Data Lake). Именно поэтому он был выбран Big Data архитекторами банка Тинькофф для проектирования озера данных, построенного по LSA-принципу и интегрированного с корпоративным DWH [5]. Подробнее об этом решении мы рассказывали здесь.
В следующей статье мы рассмотрим, ключевые понятия Data Vault, а также основные принципы этого подхода к моделированию данных. А как использовать все это на практике при разработке КХД и Data Lake для эффективного хранения больших данных, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Архитектура Данных
- Практическое применение Big Data Аналитики для решения бизнес-задач
- Аналитика больших данных для руководителей

