
Продолжая разговор про фиксацию заданий Apache Spark при работе с облачными хранилищами больших данных, сегодня подробнее рассмотрим, насколько эффективны commit-протоколы экосистемы Hadoop, предоставляемые по умолчанию, и почему известный разработчик Big Data решений, компания Databricks, разработала собственный алгоритм. Читайте далее про сравнение протоколов фиксации заданий в Spark-приложениях: результаты оценки производительности и транзакционности – бенчмаркинговый тест.
3 варианта commit-протоколов Apache Hadoop для фиксации Spark-заданий в облаке
Напомним, протокол фиксации заданий (commit) необходим для предотвращения потери или дублирования данных при работе с облачным объектным хранилищем. Он гарантирует, что видимыми становятся только результаты успешно выполненных задач и заданий Apache Spark. По умолчанию этот Big Data фреймворк включает 2 стандартных commit-протокола экосистемы Hadoop [1]:
- версия 1, когда выходные файлы задачи перемещаются в их окончательные местоположения в конце задания. А все файлы промежуточного вывода записываются во временный каталог, созданный Spark. После выполнения всех задач, драйвер Spark перемещает файлы из временного каталога в окончательный, однако, при большом количестве выходных файлов эта операция может занять много времени.
- версия 2, когда выходные файлы перемещаются в окончательный каталог по мере выполнения задач. Это решает проблему долгой работы Spark-драйвера на последнем этапе, но в случае сбоя задания в окончательном каталоге появятся файлы с частичными результатами, что может привести к некорректным данным.
Таким образом, протокол фиксации версии 1 обеспечивает безопасность, а версии 2 — производительность. Поскольку оба этих качества важны для практической обработки больших данных, компания-апологет коммерческого продвижения Apache Spark, предложила собственный commit-протокол, который объединяет достоинства обеих версий Hadoop-алгоритмов, исключая их недостатки. Он называется DBIO и координируется с другими высокодоступными сервисами Databricks. Его основная идея заключается в следующем [2]:
- когда пользователь записывает файл в Spark-задании, DBIO записывает файлы тегов с уникальным идентификатором транзакции прямо в их окончательное расположение и отмечает транзакцию как успешно выполненную, когда задания будут зафиксированы;
- при чтении файлов DBIO проверяет наличие идентификатора транзакции, а также статус успешного завершения и игнорирует файлы, если транзакция не завершена.
Эта простая идея значительно повышает производительность без ущерба для надежности. Насколько это эффективно работает по сравнению со стандартными commit-протоколами, рассмотрим далее.
Hadoop для инженеров данных
Код курса
HDDE
Ближайшая дата курса
17 июня, 2024
Продолжительность
40 ак.часов
Стоимость обучения
120 000 руб.
Сравнение протоколов фиксации заданий: бенчмаркинговый тест
Для сравнения эффективности каждого commit-протокола относительно других они сравнивались по следующим параметрам [2]:
- производительность – насколько быстро протокол фиксирует файлы;
- транзакционность – может ли работа завершаться только с частичными или искаженными результатами? В идеале выходные данные задания должны быть видимыми для транзакций только в случае успешного завершения. А если при выполнении задания произошел сбой, читатели не должны наблюдать поврежденные или частичные результаты.
Сначала сравним по этим двум показателям стандартные версии commit-протоколов Apache Hadoop. Поскольку в версии 2 файлы перемещаются параллельно, как только задачи завершаются, она почти в пять раз быстрее, чем v1. Поэтому в последнем релизе Apache Hadoop именно v2 является протоколом фиксации по умолчанию.
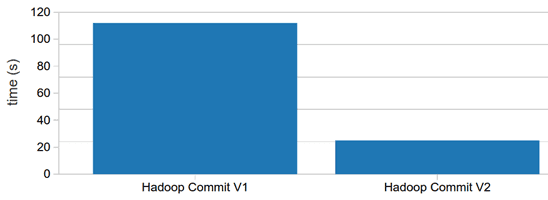
Однако, хотя версия 2 работает быстрее, она оставляет после себя частичные результаты при сбоях задания, нарушая требования к транзакционности. На практике это означает, что для связанных ETL-заданий сбой может дублировать некоторые входные данные для последующих заданий, даже при успешной повторной попытке. Это требует тщательного управления при использовании связанных ETL-заданий.
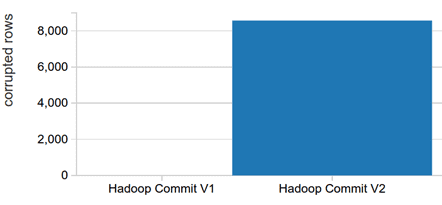
Новый протокол фиксации транзакций Databricks обеспечивает надежные гарантии в случае различных сбоев. А обеспечение корректности результатов дает пользователям Spark несколько дополнительных преимуществ [2]:
- безопасная спекуляция задач, которая позволяет Spark избирательно запускать задачи, когда наблюдается необычно медленное выполнение определенных задач. В стандартных commit-протоколах Hadoop использование предположений о задачах Spark при записи в объектное облачное хранилище Amazon S3 небезопасно из-за возможности конфликтов файлов. С транзакционной фиксацией можно безопасно включить спекуляцию задач с помощью параметра «speculation true» в конфигурации кластера Spark. Это снижает влияние отставших задач на завершение работы в целом, значительно повышая производительность.
- атомарная перезапись файлов. По умолчанию Spark реализует перезапись, сначала удаляя существующий набор данных, а затем выполняя задание по созданию новых данных. Это прерывает все текущие считыватели и не является отказоустойчивым. С транзакционной фиксацией от Databricks можно атомарно «логически удалять» файлы, помечая их как удаленные во время фиксации. Атомарную перезапись можно переключить, задав параметру «databricks.io.directoryCommit.enableLogicalDelete» значение TRUE. Это улучшает работу пользователей, которые одновременно обращаются к одним и тем же наборам данных.
- Повышенная согласованность протокол фиксации транзакций с другими службами Databricks помогает смягчить возможные проблемы согласованности Amazon S3, которые могут возникнуть с связанными ETL- заданиями.
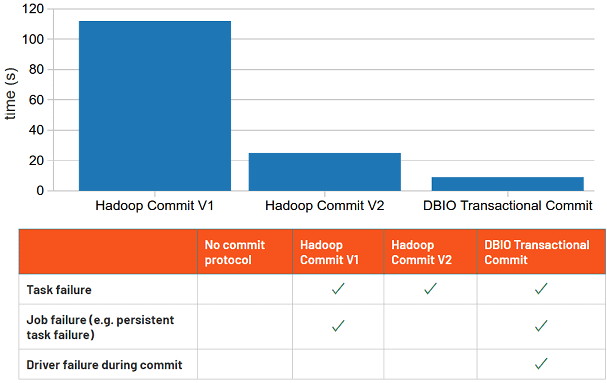
Таким образом, DBIO-протокол транзакционной фиксации заданий Apache Spark от Databricks обеспечивает лучшую производительность и надежные гарантии корректности выходных данных, по сравнению со стандартными версиями commit-алгоритмов экосистемы Hadoop.
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
13 мая, 2024
Продолжительность
16 ак.часов
Стоимость обучения
48 000 руб.
Узнайте больше про особенности конфигурирования Apache Spark для эффективной разработки распределенных приложений и потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
Источники

