На практике каждый аналитик Big Data и Data Scientist часто сталкивается с удалением дублирующихся значений в датасете. Поэтому, чтобы добавить в наши курсы по Apache Spark еще больше полезных примеров, сегодня рассмотрим 5 простых способов решения этой востребованной задачи. Читайте далее, чем distinct() отличается от dropDuplicates(), а reduceByKey() — от collect_set(), когда стоит применять оконные функции и при чем здесь ограничение размера Scala-кортежей.
5 способов удалить дубли в Spark DataFrame: пример на Scala
При работе с Apache Spark можно выделить следующие основные способы устранения дубликатов в датасете, предоставляемые API-интерфейсами фреймворка [1]:
- distinct();
- dropDuplicates();
- reduceByKey();
- collect_set();
- оконные функции.
Чтобы понять, как они работают и чем отличаются, рассмотрим набор данных об установках различных приложений разными пользователями. Определим исходные данные в виде DataFrame с помощью Scala-кода:
Fimport spark.implicits._
val installsDF = Seq(
(«01/01/2020», «a», 123),(«01/02/2020», «b», 234),
(«01/03/2020», «a», 345),(«01/04/2020″, «b», 234),
(«01/01/2020», «a», 123),(«01/05/2020», «x», 567)
).toDF(«installDate»,
«userId», «appId»)
Выведем результат с помощью команды installsDF.show(false):
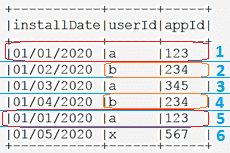
Далее, рассмотрим, как вышеперечисленные функции удалят дубликаты в строках 1 и 5.
Как работает метод distinct()
Метод distinct() предоставляется API-интерфейсом структуры данных DataFrame и возвращает новый DataFrame, содержащий отдельные строки. Он не принимает аргументов, учитывая все столбцы при удалении дубликатов. Поэтому, если нужно обработать только подмножество столбцов, следует выбрать их перед вызовом distinct(). Тогда возвращенный DataFrame будет содержать только подмножество столбцов, которые использовались для устранения дубликатов [2].
Вообще использование distinct() для устранения дублей — это самый простой и часто использующийся способ убрать из набора данных идентичные повторяющиеся строки. Применение этой функции к датафрейму из рассматриваемого примера installsDF.distinct() вернет новую таблицу с удаленной 5-ой строкой, которая полностью повторяла 1-ю.

Метод dropDuplicates()
В отличие от distinct(), который не принимает аргументов вообще, при использовании dropDuplicates() можно указать подмножество столбцов, которые следует учитывать при удалении повторяющихся записей. Это означает, что dropDuplicates() является более подходящим вариантом, когда нужно удалить дубликаты только из подмножества столбцов, при этом вернув все столбцы исходного DataFrame.
Примечательно, что для статического пакетного DataFrame этот метод просто удалит повторяющиеся строки, а для потокового все данные триггеров будут храниться в промежуточном состоянии. В этом случае, чтобы ограничить время задержки дублирования данных через их состояние, можно обратиться к водяному знаку потоковой таблицы, используя метод withWatermark(). При этом слишком поздние данные старше водяного знака будут удалены, чтобы избежать любой возможности дублирования [2]. Подробнее о том, что такое водяные знаки в Apache Spark Structured Streaming и зачем они нужны, мы рассказывали здесь и здесь.
Вызов метода dropDuplicates(Seq <String> colNames) с аргументами дает возможность использовать только определенные столбцы в качестве условия для удаления частично идентичных строк. В рассмотренном примере это будет выглядеть следующим образом: installsDF.dropDuplicates («userId», «appId») удалит 4-ю и 5-ю строку из исходного набора данных, т.к. они включали повторяющиеся значения по столбцам userId и appId со строками 2 и 1.

Как работает reduceByKey() в Apache Spark
Функция reduceByKey(func: (V, V) ⇒ V): RDD [(K, V)] возвращает новый RDD — распределенный набор данных из пар «ключ-значение» (K, V), в котором все значения для одного ключа объединяются в кортеж — ключ и результат выполнения функции reduce для всех значений, связанных с этим ключом. Однако, не все значения для одного ключа обязательно находятся в одном разделе или даже на одном узле кластера Spark, но они должны быть расположены вместе, чтобы вычислить результат. Во время вычислений одна задача будет работать с одним разделом, поэтому чтобы организовать все данные для выполнения одной операции reduceByKey, Spark необходимо выполнить операцию все для всех: считав данные из каждого раздела. Это необходимо, чтобы найти все значения для всех ключей, а затем объединить значения по разделам для вычисления окончательного результата для каждого ключа [3]. Подобное перемешивание (shuffle) данных снижает скорость вычислений из-за передачи информации по сети, поэтому при оптимизации Spark-приложений рекомендуется исключать shuffle-операции. Подробно об этом мы писали здесь и здесь.
Возвращаясь к рассматриваемому примеру, применим reduceByKey() к набору данных, чтобы найти приложения, установленные пользователем, вместе с датой его первой установки. Сначала нужно преобразовать DataFrame в RDD и включить installDate и userId в качестве ключа и appId в качестве значения. Для этого выполним следующий код:
import org.joda.time.DateTime
import org.joda.time.format.DateTimeFormatinstallsDF
.map( r=> ((r.getAs[String](«userId»), r.getAs[Integer](«appId»)), r.getAs[String](«installDate») ))
.rdd
.reduceByKey( (x,y) => {
val pattern = «MM/dd/yyyy»
val installDateMillis1 = DateTime.parse(x, DateTimeFormat.forPattern(pattern)).getMillis
val installDateMillis2 = DateTime.parse(y,
DateTimeFormat.forPattern(pattern)).getMillisif(installDateMillis1 < installDateMillis2) x else y
} ).map{case((userId, appId), (installDate)) => (installDate, userId, appId)}
.toDF(«installDate», «userId», «appId»)
.show(false)

Метод reduceByKey подходит во многих случаях удаления дублей, но он ограничен размером кортежа. В Scala кортеж (tuple) – неизменяемый контейнер, содержащий упорядоченный набор элементов различного типа из серии классов от 2 до 22 элементов. Поэтому reduceByKey() не стоит использовать, когда в ключах или значениях Spark RDD более 22 столбцов [1].
Функция collect_set()
Эта функция из API-интерфейса Spark SQL собирает и возвращает набор уникальных элементов, но она не является детерминированной, т.к. порядок результатов зависит от порядка строк, который может измениться после перемешивания [4].
На самом деле collect_set() – это не совсем дедупликация, а сворачивание записей путем выполнения groupBy() и сбора уникальных значений для столбца, относящегося к каждой группе.
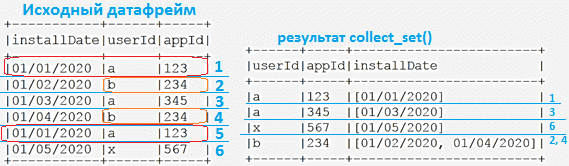
В нашем примере это выглядит так:
import org.apache.spark.sql.functions.collect_setinstallsDF
.groupBy(«userId», «appId»)
.agg(collect_set(«installDate»).alias(«installDate»))
.show(false)
В результате строки 2 и 4 из исходного датасета будут объединены, а их отличающиеся значения перечислены в столбце installDate.
Оконные функции (Window Function) для удаления дублей
Если набор данных содержит более 22 столбцов, требуется обойти ограничение размера кортежей Scala, применив оконные функции Spark SQL. Например, для поиска приложений, установленных пользователем вместе с его первой датой установки, необходимо разделить RDD по столбцам userId и appId, отсортировать столбец installDate по возрастанию, преобразовав его во временную метку unix. Далее следует указать рейтинг для каждой строки и отфильтровать строки с рангом 1.
Код на Scala выглядит следующим образом [1]:
import org.apache.spark.sql.expressions._val windowConf =
Window.partitionBy(«userId»,»appId»).orderBy(unix_timestamp($»installDate»,»MM/dd/yyyy»).cast(«timestamp”).asc)installsDF
.withColumn(«rank», row_number().over(windowConf))
.filter($»rank» === 1)
.show(false)
Результат будет включать дополнительный столбец rank, искусственно добавленный как критерий отбора (фильтрации) нужных строк.

Завтра мы продолжим разговор про практическое обучение Apache Spark и рассмотрим пример оптимизации SQL-запросов на больших датафреймах. Узнайте больше про возможности Apache Spark для аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники
- https://eshanhaval.medium.com/everyday-data-dedupe-with-spark-c28425ab271e
- https://towardsdatascience.com/distinct-vs-dropduplicates-in-spark-3e28af1f793c
- https://spark.apache.org/docs/latest/rdd-programming-guide.html
- https://spark.apache.org/docs/latest/api/sql/#collect_set