
Как разработчику выбрать подходящий режим развертывания для своего Spark-приложения, достоинства и недостатки клиентского и кластерного режимов, а также особенности запуска под управлением YARN.
Архитектура и режимы развертывания Spark-приложения
Будучи фреймворком для создания приложений быстрой обработки Big Data, Apache Spark имеет несколько режимов развертывания, которые зависят от варианта запуска Spark-приложения: на локальной машине или в распределенной среде кластера. Режим запуска Spark-приложения полностью определяется значением одного параметра, драйвера. Именно место нахождения компонента «Драйвер» (на локальном узле или в удаленном кластере) определяет поведение задания Spark.
Напомним, любое приложение Apache Spark включает в себя процесс драйвера (driver) и набор процессов-исполнителей (executor). Именно процесс драйвера считается «сердцем» Spark-задания, поскольку он управляет всей необходимой информацией для работы приложения. А исполнители отвечают за фактическое выполнение работ, которые им выделяет драйвер. Процесс драйвера отвечает за следующие аспекты управление информацией о приложении, отклик на команды, анализ, распределение и планирование работы исполнителей. Драйвер преобразует исходный код программы в задачи – единицы вычислительной активности, которые вместе образуют задание (job), и планирует их для исполнителей с помощью планировщика задач (Task Scheduler). Подробнее об этих и других основах архитектуры Spark-приложений мы писали здесь.
Диспетчер ресурсов в Spark-кластере отвечает за выделение ресурсов работающим приложениям. Фреймворк имеет подключаемую архитектуру, которая позволяет использовать различные диспетчеры кластеров в качестве менеджеров ресурсов: Apache Mesos, Hadoop YARN и Kubernetes. Программой, отвечающей за управление конкретным приложением, работающим в кластере, является мастер приложений (Application Master). В частности, мастер приложений занимается выделением ресурсов, координацией задач, обеспечивает отказоустойчивость и отчетность о состоянии Spark-приложения для программы драйвера.
Диспетчер ресурсов (Resource Manager) создает контейнеры — виртуальные машины или процессы, запускаемые на узле кластера и получающие определенное количество ресурсов для выполнения задач или исполнителя. Исполнителем называется процесс, который запускается мастером приложений на рабочем узле кластера и отвечает за выполнение задач – обработку данных и выполнение вычислений.
Как уже было отмечено ранее, для приложений Apache Spark возможны 2 режима развертывания, в зависимости от расположения драйвера:
- режим клиента, когда драйвер запускается на узле, куда отправляется задание. Этот режим поддерживает как интерактивные оболочки, так и команды отправки заданий
- режим кластера, когда драйвер находится на удаленном узле в кластере.
Чем отличаются эти режимы и какой из них выбирать, мы рассмотрим далее.
Режим клиента
Если драйвер Spark-задания работает на машине, с которой оно отправлено, это соответствует клиентскому режиму развертывания. В этом случае узел, отправляющий задание, находится внутри или рядом со инфраструктурой, обеспечивая высокую скорость работы приложения из-за отсутствия сетевой задержки перемещения данных для генерации конечного результата. Когда машина, отправляющая задание, удалена от Spark-инфраструктуры, возникает высокая задержка из-за передачи большого объема данных по сети.
При запуске Spark-оболочки драйвер приложения создает сеанс Spark на локальном компьютере, который запрашивает диспетчер ресурсов, присутствующий в кластере, для создания приложения YARN. Диспетчер ресурсов YARN запускает контейнер мастера приложений. В клиентском режиме Мастер приложений действует как средство запуска Исполнителя, обращаясь к диспетчеру ресурсов и запрашивая дополнительные контейнеры. Менеджер ресурсов выделит новые контейнеры.
После выделения контейнеров с запрошенными конфигурациями, мастер приложений запускает исполнителей в каждом контейнере. Каждый исполнитель работает в своей собственной JVM и может одновременно выполнять несколько задач. Исполнители можно добавлять или удалять динамически во время выполнения приложения в зависимости от доступных ресурсов в кластере. Исполнители будут напрямую общаться с драйверами, которые присутствуют в системе, куда отправлено Spark-приложение.
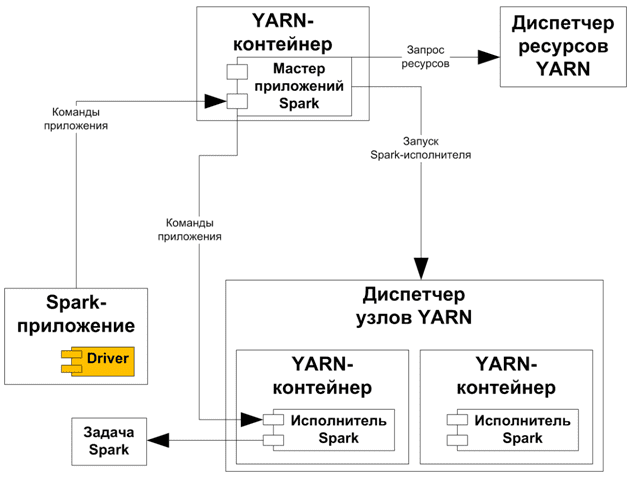
В клиентском режиме взаимодействие между вышеописанными компонентами упрощается, а сама схема развертывания становится намного меньше.
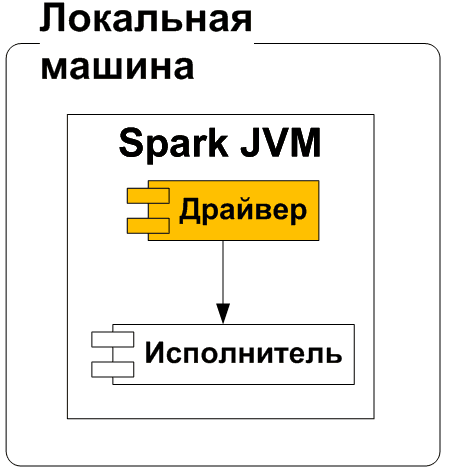
В этом режиме клиент имеет больший контроль над приложением. Это позволяет разработчику взаимодействовать с приложением во время его работы, отслеживать ход выполнения и изменять приложение по мере необходимости. Кроме того, клиентский режим предоставляет разработчику прямой доступ с клиентского компьютера к выходным данным и журналам приложения, что полезно для отладки и устранения ошибок.
В локальном режиме Spark работает на одной машине, используя все ядра машины. Это самый простой способ развертывания, который обычно используется для тестирования и отладки приложений. В этом случае не нужно беспокоиться о сложных настройках или конфигурациях кластера, что подходит для начинающих разработчиков или дата-инженеров, которым необходимо протестировать небольшие рабочие процессы обработки данных.
Однако, основным недостатком клиентского режима является низкая производительность и слабая надежность. Если локальный узел выходит из строя, то все задание завершится сбоем. Это неприемлемо для производственного развертывания, но пригодится для разработки и тестирования, когда пользователь должен взаимодействовать с приложением Spark и получать обратную связь в режиме реального времени, например, в Jupyter-блокнотах или средах разработки. Также клиентский режим пригодится в ситуациях, когда пользователь хочет выполнить задание с коротким сроком службы, которое не требует постоянного мониторинга.
Режим кластера
В кластерном развертывании драйвер Spark-задания не работает на локальном компьютере, с которого оно было отправлено. Задание запустит драйвер внутри кластера. В этом случае локальная машина, отправляющая задание, удалена от инфраструктуры, но благодаря тому, что в ней работает драйвер, сокращается перемещение данных по сети. Поэтому обработка данных выполняется быстрее. А надежность всей системы повышается, поскольку снижается вероятность разрыва сети между драйвером и Spark-инфраструктурой.
В режиме кластера задание запускает драйвер в кластере как часть подпроцесса мастера приложений. Для развертывания используется команда spark-submit, которая не поддерживает интерактивный режим shell-оболочки. В случае сбоя программа драйвера создается заново, поскольку запускается удаленно в мастере приложений. Как уже было отмечено выше, в режиме кластера работает выделенный диспетчер ресурсов, например, YARN, Apache Mesos, Kubernetes и пр. для выделения ресурсов, необходимых для выполнения задания. В отличие от локального клиентского режима, в режиме кластера мастер приложений создаст в нем драйвер, который взаимодействует с диспетчером ресурсов.
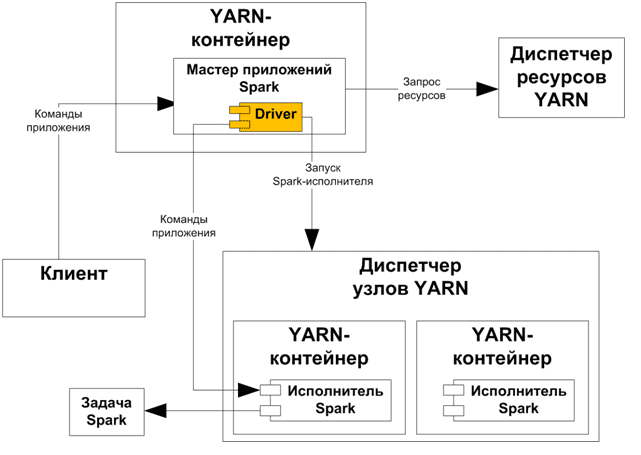
Из-за повышенной надежности и производительности именно кластерный режим используется для производственных развертываний приложений. Однако, просто знать разницу между клиентским и кластерным режимами недостаточно: разработчику Spark-приложений также полезно понимать особенности использования диспетчера ресурсов YARN, что мы и рассмотрим далее.
Запуск Spark-приложений на YARN
YARN контролирует управление ресурсами, планирование и безопасность запущенных на нем Spark-приложений в любом режиме (кластера или клиента). При запуске Spark в YARN исполнитель Spark работает как контейнер YARN. Например, MapReduce планирует контейнер и запускает JVM для каждой задачи, а фреймворк размещает несколько задач в одном контейнере, позволяя на несколько порядков сократить время запуска каждой из них.
У каждого экземпляра приложения есть процесс мастера приложений в YARN. Им обычно является первый контейнер, запущенный для этого приложения. Необходимые ресурсы приложения получает согласно своим запросам к диспетчеру ресурсов. После выделения ресурсов, приложение дает команду менеджеру узлов (Node Manager) запускать контейнеры от его имени. После этого процесс, запускающий приложение, может завершиться, а координация продолжается с процесса, управляемого YARN и работающего в кластере.
Если драйвер запускается в мастере приложений на узле кластера, который выбирает YARN, это соответствует кластерному развертыванию Spark-приложения. Это означает, что процесс, работающий в контейнере YARN, отвечает за различные этапы, а клиент, запустивший приложение, не должен продолжать работать в течение всего срока службы задания.
Однако, для интерактивной отладки кластерный режим не подходит, поскольку приложения, требующие ввода данных пользователем, нуждаются в Spark-драйвере для запуска внутри клиентского процесса, например, spark-shell и pyspark.
Когда драйвер запускается на хосте, на котором отправлено Spark-задание, это соответствует клиентскому режиму. Мастер приложений запрашивает контейнеры-исполнители из YARN, а клиент для планирования заданий просто связывается с этими контейнерами после их запуска.
Узнайте больше про Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

