
Мы уже писали, что Apache Hadoop 3.3.1 поддерживает технологию кодирования со стиранием (Erasure Coding, EC), которая экономит место на жестком диске по сравнению с репликацией. Однако, беспечное применение этой новой фичи может обернуться настоящей катастрофой. Кейс соцсети «Одноклассники» от ведущего разработчика Дениса Ефарова, представленный на конференции Smart Data для инженеров данных в октябре 2021 года.
Что такое Erasure Coding и зачем это нужно
Напомним, кодирование со стиранием для HDFS, введенное в Apache Hadoop 3.3.1 снижает накладные расходы на хранение данных до 50% независимо от коэффициента репликации. Это достигается с помощью алгоритма Рида-Соломона, позволяющего чередовать и разделять логически последовательные данные файла на более мелкие блоки, сохраняя их на разных дисках недорогого RAID-массива.
Из-за особенностей этой технологии, экономия места в HDFS повышает расходы на кластер Apache Hadoop по следующим причинам:
- дополнительное потребление ресурсов ЦП на кодирование/декодирование данных на клиентах HDFS и узлах Hadoop-кластера;
- увеличение нагрузки на сеть из-за передачи данных;
- зависимость количества узлов данных в кластере Hadoop от ширины полосы EC, равной числу блоков файловой системы;
- избыточность количество стоек в кластере, чтобы в среднем каждая из них содержала количество блоков не больше числа блоков четности EC, чтобы обеспечить отказоустойчивость при чтении и записи файлов, выполняемых вне стойки.
По сути, все эти недостатки устраняются дополнительными вложениями в кластер Apache Hadoop. Поэтому если инвестиции в инфраструктуру – не проблема, Erasure Coding – отличный способ сэкономить место на жестких дисках. Именно так размышляла команда дата-инженеров соцсети Одноклассники, когда в первой половине 2019 года произошел резкий скачок увеличения количества данных: +10% за 2 месяца. Чтобы существующая инфраструктура Hadoop могла обрабатывать десятки ТБ в день и хранить 150 петабайт исторических данных за 10 лет в Apache Hadoop, дата-инженеры Одноклассников (ОК) решили использовать Erasure Coding. Что из этого вышло, мы рассмотрим далее.
EC в Одноклассниках: настоящие проблемы и их последствия
Внедрив в июне 2019 года Erasure Coding в свои кластера Apache Hadoop, дата-инженеры ОК отметили первые успехи этой технологии, которая позволяла экономить около 5 ТБ в сутки. Однако, в ноябре 2019 года впервые возникла проблема с чтение файла формата Parquet из HDFS: обрыв записи, ошибка в методе org.apache.parquet.hadoop.ParquetFileReader.readFooter(). Исправив эту единичную проблему вручную, ровно через 6 месяцев дата-инженеры ОК столкнулись с ней снова. После сканирования папков и файлов, стало понятно подобные баги характерны только для Parquet-файлов в Hadoop 3, которые отличаются EC-полосой размером 1 МБ и идут ровно через 6 блоков.
Суть ошибки оказалась связана с алгоритмом Рида-Соломона при восстановлении поврежденных блоков, которая зависит от порядка индексов. Обнаружить этот баг оказалось непросто из-за отсутствия исключений при ошибке в методе org.apache.hadoop.io.erasurecode.rawcoder.RSRawDecoder.generateDecodeMatrix(int[] erasedIndexes). Из-за несоответствия индексов блок B0′ выглядит как результат валидного восстановления блока B0 по размеру и соответствию другим блоками, но не является им!
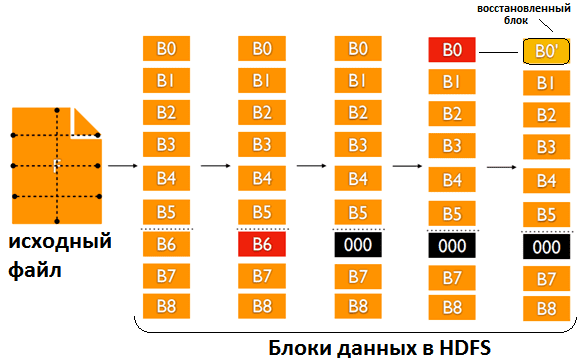
Эта проблема связана с главным достоинством EC – экономией места в HDFS. При кодировании размер данных уменьшается. Но при декодировании, т.е. восстановлении данных – наоборот, растет! Но места больше не становится, напротив, его не хватает. Поэтому при декодировании в EC следует, прежде всего, проверить корректность оригинала. Для этого дата-инженеры ОК вручную реализовали восстановление данных по алгоритму Рида-Соломона с помощью Java API, который позволяет получить отдельные блоки. На восстановление поврежденных данных ушел почти год, с августа 2020 по сентябрь 2021.
Так из-за неаккуратного применения Erasure Coding для хранения данных повреждено оказалось больше 4 000 000 файлов, 10% из которых имели поврежденные резервные копии. Из них удалось восстановить 9.9%, 0.1% (40 000 файлов) оказались утеряны навсегда. Общие потери данных составили около 115 ТБ. Поэтому золотое правило каждого администратора насчет бэкапов остается неизменным: они должны быть. Всегда. Причем в максимально простой форме, без вычислений и в другой физически и алгоритмически системе. Желательно в структурированных форматах, которые легче проверить на корректность.
Узнайте больше про администрирование и эксплуатацию Apache Hadoop для аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Hadoop
- Hadoop для инженеров данных
- Администрирование кластера Hadoop
- Безопасность озера данных Hadoop на платформе CDP
Источники
- https://smartdataconf.ru/person/denis-efarov/
- https://assets.ctfassets.net/oxjq45e8ilak/3vPN1K82TYTSaEqpXMpMt7/6332940cb1f21efc6cd7cb3bf88dbd6d/Hadoop_3-_Erasure_Coding_Catastrophe.pdf
- https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HDFSErasureCoding.html
- https://karthiksharma1227.medium.com/hdfs-erasure-coding-ec-4ef151367bb5

