Хотя Apache Kafka часто используется в качестве шины обмена данными в микросервисной архитектуре, о чем мы писали здесь, не стоит воспринимать эту платформу как хранилище событий. В чем разница между событием и сообщением, а также другие тонкости построения микросервисной архитектуры, управляемой событиями.
События vs сообщения
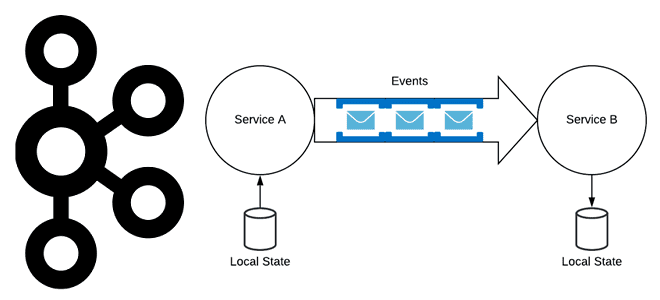
Событие — это сообщение программной системы о том, что произошло в пределах ее границ. Система выполняет операцию и в случае успеха этой операции сообщает другим приложениям или сервисному ПО посредством асинхронного обмена сообщениями, что операция выполнена и какие данные получились в результате этого. Однако, события и сообщения принципиально отличаются друг от друга и приводят к совершенно разным типам поведения в программных системах.
Событие — это запись определенного действия, произошедшего в системе. Поэтому событие определяется на языке системы-продюсера, которая не заботится о своих потребителях, а просто гарантирует, что определенный набор данных о событии будет передан через какой-то носитель. Сообщение является одноранговой конструкцией, нацеленной на конкретного потребителя. Поэтому содержимое сообщения должно быть определено на языке потребителя и не будет иметь смысла для других систем, которые будут его прослушивать. По сути, сообщение, отправленное системой A системе B, представляет собой асинхронный вызов API.
Если события и сообщения передаются через асинхронную транспортную среду, например, Apache Kafka, разница между ними становится значимой, при взаимодействии между несколькими распределенными системами.
Используя события для распространения информации по всей распределенной системе, можно построить очень слабосвязанную архитектуру, в которой разные сервисы знают друг о друге очень мало. Все системы либо транслируют события, соответствующие действиям в их контексте или используют события из других систем для запуска собственных рабочих процессов. Сервис-продюсер не знает, какой потребитель будет потреблять ее события. Сервис-потребитель не знает, откуда пришло событие, а просто делает что-то в ответ на его получение.
В мире микросервисов события порождают хореографический стиль построения рабочих процессов. По сути, это не явно определенный рабочий процесс, а сопоставление сервисов с реакцией на определенный набор событий. Сквозной рабочий процесс достигается без его полного описания, т.к. его можно составить из независимых взаимодействий событийных сервисов. При этом нет необходимости знать полный поток, который на самом деле может и не существовать совсем. Этот подход противоположен паттерну оркестрации, когда есть единый управляющий центр, маршрутизирующий взаимодействие между отдельными сервисами.
В архитектуре, основанной на сообщениях, сервисы могут быть разделены во времени из-за использования асинхронного обмена сообщениями, но они связаны на границе передачи домена. Но в этом случае разные системы знают друг о друге, позволяя реализовать отправку подтверждений о получении и обработке сообщений, что невозможно в архитектуре, управляемой событиями. В микросервисной архитектуре сообщения порождают рабочие процессы в стиле оркестровки, когда система оркестрации фиксирует последовательность, где набор сервисов должен вызываться для достижения сквозного вывода, и вызывает их через сообщения или вызовы API. Обычно именно так реализуются корпоративные шины данных (ESB, Enterprise Service Bus).
Разобравшись с разницей между событиями и сообщениями, рассмотрим некоторые проблемы, которые необходимо учитывать при внедрении архитектур, управляемых событиями. Одной из них является мониторинг бизнес-процессов. Поскольку системы взаимодействуют не друг с другом, а с событиями, отслеживать статус любого бизнес-процесса становится труднее. Длинные конвейеры обработки данных, например, работа с заказами в интернет-магазине, становятся очень сложными для управления. В частности, чтобы определить полный процесс выполнения заказа придется обратиться к нескольким сервисам. Поэтому вместо оркестровки во многих случаях целесообразно использовать подход хореографии, о котором мы говорили выше и также рассматриваем здесь.
Также усложняется обработка ошибок. Если один сервис выходит из строя и теряет некоторые сообщения, нет простого способа повторно сгенерировать или воспроизвести потерянные данные. Сервис-продюсер не дает никаких гарантий их повторной публикации. А обеспечение безотказной работы таких систем распределенной передачи событий как Apache Kafka становится критически важной частью всей микросервисной архитектуры. Далее разберем достоинства и недостатки подхода Event Sourcing и его реализацию на Apache Kafka. Подробнее о том, что представляет собой этот паттерн EDA-архитектуры, читайте в нашей новой статье.
Event Sourcing: за и против
При этом Kafka, хотя и может использоваться как единый источник истины для событий, решая проблему распределенных транзакций, его приходится использовать для всех частей сложной системы, даже тех, которые предполагают другие архитектурные паттерны. Например, когда необходимо реализовать ACID-требования к транзакциям, лучше подойдет реляционная СУБД, а не Kafka.
Кроме того, в системе с источником событий часто требуется построить модели чтения данных, которые объединяют события из нескольких потоков или нескольких типов. Например, чтобы агрегировать товары на складе, нужно агрегировать все типы событий, которые добавляют и удаляют товары на складе, для каждого типа товара. Чтобы корректно спроецировать все события в правильное текущее состояние для любого момента времени, они должны быть в нужном хронологическом порядке. Если порядок событий неправильный, то обработка события удаления товара со склада перед событием его добавления на склад приведет к неправильному ответу.
Однако, Apache Kafka гарантирует порядок только внутри разделов, а не между ними, что заставляет ИТ-архитектора усложнять решение. Поэтому Event Sourcing — это лучший способ сохранить состояние системы, а не микросервисная архитектура, управляемая событиями. И этот подход дает следующие преимущества:
- гибкость – можно изменить реализацию модели в любое время без необходимости миграции базы данных, перейдя от ООП к функциональному стилю программирования, изменить граф объектов, преобразовать скаляры в объекты-значения и пр. Ограничениями в этом случае становятся границы, заданные потоками событий. Если нужно разделить одну сущность на две или объединить их, следует перенести потоки событий, что не всегда просто на работающем приложении.
- простота отладки – если некоторые сущности находятся в неправильном состоянии, можно воспроизвести события, которые привели к этому состоянию, чтобы выяснить причину ошибки. Исправив код публикации неверного события, также придется поправить состояние всех некорректных сломанных сущностей, добавив события исправления в конец всех затронутых потоков.
- разделение принятия решения и изменения состояния, что снижает сложность проектирования и реализации системы;
- простые запросы на чтение потока событий, которые выполняются намного быстрее из-за отсутствия соединения нескольких таблиц. А добавление событий в поток представляет собой простой запрос на вставку. Впрочем, для огромных потоков с тысячами событий, запросы к ним и их десериализация могут работать медленно. Поэтому рекомендуется делать потоки событий небольшими, определяя их границы с учетом домена. Если нужны большие долгоживущие потоки, поможет создание моментальных снимков как кэш, который материализует состояние сущности в некоторый момент времени. Для восстановления он сначала считывает последний снимок, а затем считывает и применяет только те события, которые произошли после создания снимка. Но это увеличивает размер кода и шансы на ошибки.
Подробнее про отличия Event Sourcing от Event Streaming и возможности их совместного использования читайте в нашей новой статье.
В заключение перечислим некоторые лучшие практики Event Sourcing подхода. Не стоит обогащать события дополнительной информацией, которая не относится к ограниченному контексту. Если нужно обогатить события дополнительными метаданными, лучше реализовать новое событие. Не обязательно публиковать все события в брокере сообщений, т.к. Event Sourcing — это просто способ хранения состояния. В распределенной микросервисной архитектуре состояние должно быть приватным по отношению к ограниченному контексту, которому принадлежит сервис. Иначе получится распределенный монолит. Поэтому в архитектуре, .управляемой событиями, следует публиковать только ключевые, которые часто обогащаются дополнительной информацией, чтобы сервисы-потребители этих событий получали все данные, необходимые им для выполнения работы.
А версионирование событий позволяет развивать Event Driven архитектуру. Таким образом, Event Sourcing отлично подходит для комплексных систем со сложной бизнес-логикой, где необходимо много разных представлений (моделей). Однако, для простого CRUD-приложения с 4-мя базовыми операциями работы с данными, что реализуется в REST API, Event Sourcing не имеет особого смысла. Наконец, повторим, для использования событий в некоторых ограниченных контекстах (частях приложения), целесообразно рассмотреть другие архитектурные паттерны, например, CQRS (Command and Query Responsibility Segregation). Кстати, Apache Kafka отлично реализует этот шаблон разделения команд чтения данных и манипулирования ими, что мы разбирали здесь и здесь. О развитии экосистемы Apache Kafka в Confluent Cloud с возможностями вычислительного фреймворка Flink читайте в нашей новой статье.
Освойте проектирование современных дата-архитектур в проектах аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Архитектура Данных
- Практическое применение Big Data Аналитики для решения бизнес-задач
- Аналитика больших данных для руководителей
Источники

