Недавно мы писали про пользу snapshot’ов Apache HBase на примере компании Vimeo. Сегодня рассмотрим кейс корпорации Box, которая специализируется на облачных enterprise-продуктах совместного управления контентом и файлами. Переход от локальной HBase к Google Cloud BigTable: сложности миграции и способы их обхода.
Сходства и различия Apache HBase с Google Cloud BigTable
Изначально компания Box использовала вычислительные сервисы в собственных центрах обработки данных, а облачные сервисы применялись в основном для географически разнесенных хранилищ. Но с учетом всеобщего тренда на SaaS/PaaS-решения было решено перейти от локальной HBase к Google Cloud BigTable. Напомним, BigTable – это высокопроизводительная NoSQL-СУБД на основе Google File System и других продуктов этой корпорации. Сегодня эта СУБД редко используется за пределами Google, но доступна как часть Google App Engine.
Хотя BigTable как полностью управляемая облачная NoSQL-СУБД имеет совместимый с HBase клиент, на практике организовать процесс миграции с нулевым временем простоя оказалось не так-то просто. При том, что HBase можно рассматривать как своего рода Java-реализацию BigTable, которая добавляет аналогичную функциональные возможности, в ядро Hadoop, они имеют ряд специфических отличий. В частности, при создании семейства столбцов нельзя настроить размер блока или метод сжатия ни с помощью оболочки HBase, ни с помощью API этой NoSQL-СУБД. BigTable управляет размером блока и сжатием автоматически, используя собственные методы сжатия для всех данных. Также BigTable требует, чтобы имена семейств столбцов следовали регулярному выражению [_a-zA-Z0-9] [-_. A-zA-Z0-9] *. Поэтому при импорте данных в BigTable из HBase, нужно сначала изменить имена семейств, чтобы следовать этому шаблону. Также некоторые методы, доступные в HBase, не поддерживаются в BigTable. Подробнее про сходства и отличия Google Bigtable с HBase читайте здесь.
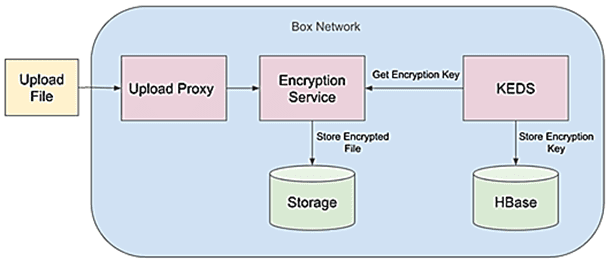
Каждый файл клиента, загруженный в Box, зашифрован с использованием уникального ключа шифрования данных. Созданием, извлечением и хранением этих метаданных ключей управляет внутренний микросервис шифрования ключей (KEDS, Key Encryption Decryption Service). KEDS хранит все свои данные в таблице NoSQL, размещенной на нескольких кластерах HBase в центрах обработки данных Box. В начале миграции в этом наборе данных было примерно 200 миллиардов ключей, а общий размер таблицы в HBase составлял примерно 80 ТБ. Эти полностью реплицированные кластеры используются в активной конфигурации и расположены в разных географических регионах. Поскольку переносимые данные используются в каждой операции, которая обращается к содержимому хранилища в Box, метаданные видят примерно 80 000 операций чтения в секунду и 20 000 операций записи в секунду.
Поэтому к клиенту HBase в Box выдвигаются следующие обязательные требования:
- нулевое время простоя хранилища метаданных или сервиса KEDS;
- минимальное воздействие на задержку сервиса со стороны процесса миграции и конечного состояния не могут кардинально изменить задержку службы;
- надежная гарантия целостности данных, т.к. неправильный или поврежденный ключ приведет к сбою.
Экземпляр BigTable — это набор из одного или нескольких кластеров BigTable, каждый из которых состоит из одного или нескольких узлов. Кластеры могут существовать в независимых регионах и поддерживать автоматическую репликацию между ними. Маршрутизация запросов к кластерам внутри экземпляра контролируется профилем приложения, который может быть двух типов:
- однокластерная маршрутизация: направляет все запросы в один кластер в экземпляре. Если этот кластер становится недоступным, необходимо вручную переключиться на другой кластер в экземпляре.
- Мультикластерная маршрутизация: автоматически направляет запросы в ближайший кластер в экземпляре. Если кластер становится недоступным, трафик автоматически переключается на ближайший доступный кластер.
Чтобы протестировать жизнеспособность кластера BigTable в условиях рабочей нагрузки, дата-инженеры Box создали экземпляр BigTable с двумя кластерами и реализовали двойную запись между HBase и BigTable. Также был сделан моментальный снимок небольшого кластера HBase (15 ГБ) в среде разработки и импортирован в аналогичный экземпляр BigTable. В результате этого эксперимента выяснились следующие подробности:
- не все функции BigTable поддерживаются во всех конфигурациях с несколькими кластерами. Например, BigTable не поддерживает операции проверки и размещения со своей мульти-кластерной маршрутизацией, которая обеспечивает автоматическое переключение при отказе.
- размер набора данных в HBase и BigTable неодинаков. При первоначальном импорте набор данных был примерно на 50% больше в BigTable, возможно, из-за дополнительных версий строк, которые копируются во время импорта. В то время как BigTable и HBase поддерживают управление версиями, BigTable не имеет практических ограничений на максимальное количество версий, лимитировать которое можно с помощью параметра maxVersions. Однако, через неделю после импорта объем данных увеличился еще на 20% по сравнению с HBase. Поэтому пришлось заложить в бюджет 50% дополнительных мощностей во время миграции и 20% дополнительных мощностей в долгосрочной перспективе.
- при импорте snapshot’а HBase в BigTable есть риски восстановить строки, которые были удалены в BigTable после того, как был сделан моментальный снимок HBase. Избежать этого можно фиксируя и воспроизводя удаления в BigTable на основе отметок времени после миграции или временно отключать удаления при переходе.
- из-за несовместимости клиента Cloudera HBase и клиента BigTable, совместимого с ним, возникли проблемы с форматом сериализации данных protobuf. Поэтому дата-инженерам Box пришлось исключить пакеты Apache HBase и Hadoop, загружаемые клиентом BigTable.
Поэтапная миграция
Протестировав жизнеспособность кластера BigTable в условиях рабочей нагрузки, дата-инженеры Box составили поэтапный план перехода из локального кластера Apache HBase. Он начинался с асинхронных операций с HBase и с BigTable, т.к. они могли завершаться ошибкой, в отличие от синхронных. Сперва были реализованы асинхронные операции двойной записи и чтения BigTable, выполняемые после каждой операции с HBase. Однако, после этого возникли спорадические всплески ошибок DEADLINE_EXCEEDED от BigTable, что сказывалось на работе сервиса KEDS. Это происходило каждые несколько часов ежедневно и длилось от нескольких секунд до пары минут.
Основная причина таких всплесков была в ошибке сетевого подключения на уровне прокси Google FrontEnd (GFE), который представляет собой уровень перед всеми облачными сервисами Google. Из-за периодических отключений узлов GFE вследствие обычного еженедельного перезапуска или сбоя сервис KEDS с открытыми подключениями к этим узлам GFE не получал сигнала GOAWAY, указывающий, что соединение не должно использоваться. Поэтому трафик снизился на такие соединения с тайм-аутами. Команда GFE исправила это, отправив правильный сигнал выключения. А дата-инженеры Box добавили дополнительную логику для автоматического отката к их второму кластеру BigTable, чтобы повысить устойчивость к таким ошибкам.
Далее операции двойного чтения и записи были синхронизированы, чтобы поддерживать согласованность данных между HBase и BigTable. На этом этапе каждый запрос на запись в службу KEDS записывался в HBase и в BigTable, прежде чем вернуть успешное выполнение клиенту. Это гарантирует согласованность HBase и BigTable с момента развертывания синхронной двойной записи. Далее выполнялся перенос исторических данных данных в BigTable из HBase с помощью моментальных снимков, чтобы гарантировать существование записей в обеих базах.
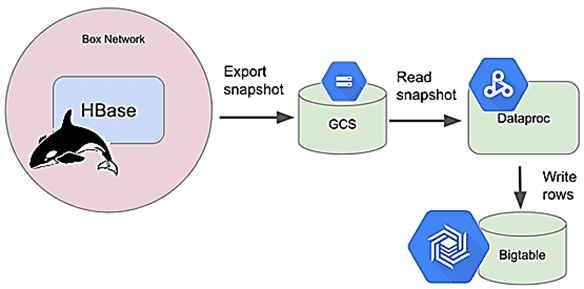
Процесс создания snapshot’а состоял из трех основных этапов:
- создание моментального снимка в HBase через типовую команду snapshot ‘keds_table_name’, ‘keds_snapshot’;
- экспорт моментального снимка в корзину Google Cloud Storage (GCS) с помощью задания HBase ExportSnapshot, требующего, чтобы местом назначения была файловая система. Чтобы рассматривать корзину GCS как файловую систему, нужен GCS Connector – библиотека Java с открытым исходным кодом. Загрузив jar-файл коннектора, мождно скопировать его на все узлы данных в кластере HBase. Далее следует создать учетную запись облачной службы Google с разрешениями на запись объектов в корзину GCS, загрузить учетные данные в файл JSON и скопировать его на все узлы данных. Наконец, необходимо обновить свойства файла core-site.xml на всех узлах данных HBase. После всего этого фактическая команда экспорта snapshot’а выглядит следующим образом:
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -libjars /usr/lib/hadoop/lib/gcs-connector-hadoop2-2.1.6-shaded.jar -snapshot keds_snapshot -copy-to gs://bucket_name/hbase_snaphost_home
- импорт снимка в экземпляр BigTable путем запуска задания MapReduce в Google Cloud Dataproc. Здесь команда Box увеличила масштаб экземпляра BigTable до примерно одного узла BigTable для каждой задачи сопоставления, чтобы дополнительный трафик записи не прервал входящий трафик клиентов от синхронной двойной записи.
В результате всех этих шагов удалось добиться согласованности данных между HBase и BigTable, а также полностью перейти к BigTable, используя его как источник истины. После нескольких недель успешного эксплуатационного тестирования в production, были окончательно отключены все операции записи в HBase. Читайте в нашей новой статье, как перейти в Cloudera Operational Database.
Освоить все тонкости работы с Apache HBase для эффективной аналитики больших данных вам помогут специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:

