Недавно мы писали про проектирование микросервисной архитектуры на базе Apache Kafka. В продолжение этой актуальной для ИТ-архитекторов, разработчиков и дата-инженеров темы, сегодня рассмотрим опыт американской медиакомпании Storyblocks по переходу от монолитной архитектуры системы поставки контента к распределенным микросервисам с Apache Kafka в Confluent Cloud.
Постановка задачи: монолит vs микросервисы
По мере роста бизнеса и увеличения количества продуктов, практически каждая компания сталкивается с необходимостью перехода от монолитной архитектуры своих ИТ-приложений к распределенным независимым решениям. Такая задача встала и перед Storyblocks, медиакомпанией из США, основанной в 2009 году. Она является лидирующим американским провайдером стокового видео и аудио с неограниченной загрузкой по подписке, обслуживая более 100 000 клиентов в индустрии телевидения и видеопроизводства, включая NBC и MTV, а также множество любителей с небольшими видеопроектами.
В 2016 году у компании возникли проблемы с масштабированием исходного монолитного приложения. Было решено разделить его на микросервисы, что привело к росту технического долга и огромной энтропии, связанной с синхронными вызовами REST API между службами. В рамках перехода от PHP-монолита выполнялся перенос учетных записей пользователей из баз данных MySQL в централизованный микросервис.
Сперва все данные учетных записей пользователей трех основных продуктов, расположенных на разных веб-сайтах, находились в отдельных базах данных. Зарегистрировавшись в одном продукте, для пользования другим нужна была новая регистрация. Это не удобно с точки зрения пользовательского опыта. Поэтому возникла задача объединить все учетные записи пользователей в один микросервис, чтобы улучшить пользовательский опыт, масштабировать ИТ-инфраструктуру, а также перейти к единому представлению клиента.
Самый простой подход к такой миграции микросервиса — просто создать сервис, временно отключить рабочие сайты, импортировать данные из старых баз данных в микросервис, а затем снова включить сайты разных продуктов. Однако, такое изменение затронет чрезвычайно чувствительную логику обработки данных с точки зрения бизнеса и чреват простоем всей системы, т.е. потерей денег.
Поэтому был применен поэтапный подход из следующих этапов:
- рефакторинг монолитного кода таким образом, чтобы все операции чтения и записи данных в домен сервиса имели четкие границы. Это инкапсулирует всю логику чтения/записи в одном месте и упрощает управление переключением между исходной базой данных и микросервисом.
- запись пользовательских данные в исходную базу данных и их отправка в новый сервис. При этом исходная база данных остается источником истины для чтения пользовательских данных.
- обратная заливка — импорт данных из старого сервиса в новый, включая перенос пользователей, которые в новом микросервисе ранее не существовали.
- попытка чтения в монолите из нового сервиса с регистрацией любых несоответствий данных, чтобы устранить любые возникающие ошибки. Записи по-прежнему идут в монолит, и на данный момент он по-прежнему является источником истины, что позволяет при необходимости вернуться к исходной базе данных.
- чтение и запись в новом микросервисе с отключением старой базы данных. Теперь микросервис стал источником записи.
Активировав запись и заполнив старые записи в фоновом режиме, инженерам Storyblocks удалось добиться перехода без простоя производственных приложений. Благодаря этапу попытки чтения удалось получить предварительный просмотр в реальном времени того, как рабочие сайты считывают данные из сервиса, включая мониторинг всех важных показателей: время отклика, сбои при записи или чтении, проблемы с целостностью данных и пр. метрики, чтобы оперативно устранить их с низким уровнем риска. Однако, этот переход создал новые проблемы, которые в конечном итоге привели к использованию Apache Kafka в качестве полностью управляемого облачного сервиса в Confluent Cloud. Как это было сделано, рассмотрим далее.
Не все так просто: проблемы синхронных вызовов REST API
Для первой версии микросервисной архитектуры в Storyblocks был выбран конвейер данных AWS Kinesis, который загружал необработанные данные в Amazon S3, чтобы обеспечить применение алгоритмов машинного обучения для анализа данных о посещениях. Также инженеры Storyblocks попытались использовать AWS Kinesis для межсервисного взаимодействия между микросервисами.
Однако, при добавлении новых функций в этот конвейер, он быстро сломался: схемы данных не хранились централизовано, а регистрация схемы была подвержена ошибкам и требовала ручного запуска пользовательского Python-скрипта. Отсутствие управление версиями, нестандартная инфраструктура и изменения кода приводили к ошибкам и сбоям, проверка схемы данных была неполной и изменения, несовместимые с предыдущими версиями, нарушали последующие сценарии. Файлы схем данных были большими и нечитаемыми для человека, а недопустимые события нельзя было обнаружить до развертывания кода.
Такая архитектура оставалась хрупкой и сложной в использовании, была неудобной при создании новых событий или обновлении существующих. Кроме того, система не допускала простой асинхронной связи между сервисами. Новые и существующие данные отслеживались и улучшались очень медленно из-за синхронных вызовов RESTfull API между разными сервисами. Со временем это также привело бы к увеличению технического долга.
Поэтому был нужен способ разделить наши микросервисы без энтропии, связанной с вызовами RESTfull API с использованием архитектуры, управляемой событиями, для передачи данных в AWS S3. Для в качестве брокера событий для создания потоковых приложений и обслуживания ML-алгоритмов анализа данных о пользовательском поведении была выбрана Apache Kafka в виде полностью управляемого облачного сервиса Confluent Cloud.
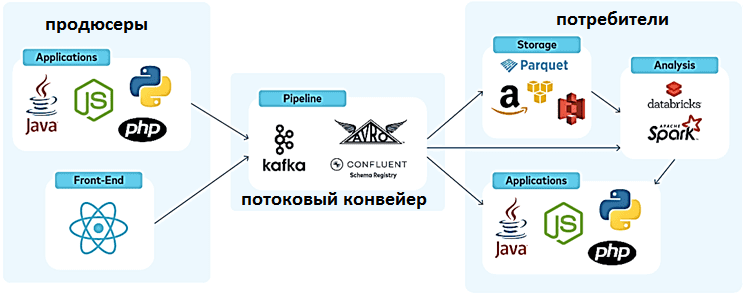
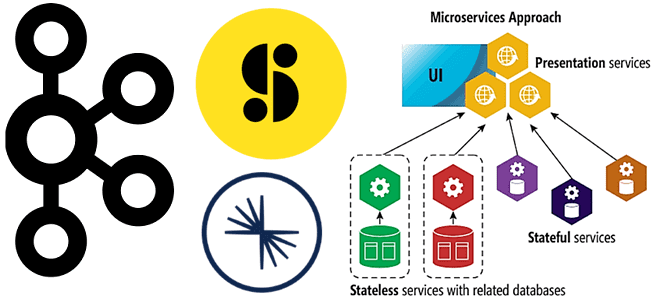
Kafka Confluent как единый конвейер событий, гибкий для разных вариантов использования, позволил выполнить переход к микросервисной архитектуре следующим образом:
- перенести сбор данных на полностью управляемые коннекторы Kafka;
- разгрузить межсервисное взаимодействие и полностью разделить микросервисы, чтобы не повторять рутинную работу по созданию множества конечных точек REST API для разныхъ команд;
- использовать «бесконечное» хранилище данных, которое позволяет дата-инженерам легко воспроизводить старые события для потребителей.
Кроме того, Confluent Cloud также предлагает множество облачных функций, которые повышают удобство и эффективность эксплуатации этой распределенной платформы потоковой передачи событий. В частности, автоматическое исправление Kafka с нулевым временем простоя, планирование и определение емкости брокеров, балансировка нагрузки и эластичное масштабирование без накладных расходов на службы синхронизации метаданных (ZooKeeper или собственный Quorum Controller), разделы и JVM.
От REST API к микросервисам, управляемым событиями, на Kafka Confluent
Выбрав Confluent в качестве центральной опоры своей инфраструктуры данных, Storyblocks использует его для текущих операций и исторического анализа: 200 топиков Kafka, от биллинга и учетных записей пользователей до аналитики потока кликов. Например, микросервис выставления счетов на основе событий, который отвечает за быстрое и точное выставление счетов клиентам. Он построен на Confluent и взаимодействует с другими микросервисами компании, используя события в основном конвейере. Благодаря полностью управляемому сервису Confluent Cloud не нужно нанимать дополнительных дата-инженеров и администраторов кластеров Kafka.
Вместо реализации очереди сообщений для взаимодействия между сервисами команда может публиковать события в топике Kafka, где они могут храниться столько, сколько нужно. Бесконечное хранилище (Infinite Storage) такого типа, встроенное в Confluent Cloud, эффективно по двум причинам:
- события могут быть воспроизведены по запросу с полной встроенной проверкой схемы без пользовательских SQL-запросов или доступа к производственной базе данных;
- аналитики иногда обращаются к давним историческим данным без сложных запросов к корзинам S3 или пакетных процессов.
Наконец, новая архитектура отлично подходит для ML-кейсов. Например, модели машинного обучения анализируют видео на наличие определенных характеристик (фичей), а результаты анализа передаются в конвейер. При необходимости дата-инженеры могут подписаться на такую модель, а специалисты по Data Science смогут убедиться в корректности прогноза.
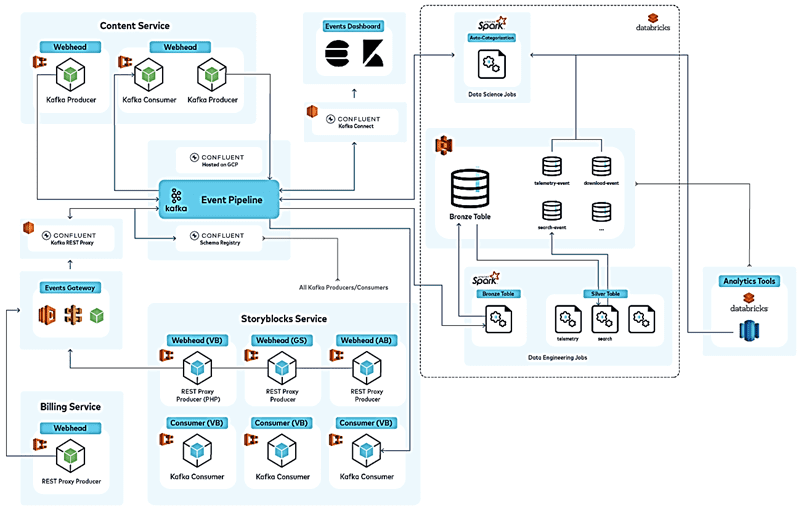
Вместо заключения отметим несколько практических рекомендаций от с Storyblocks по переходу к архитектуре микросервисов, управляемой событиями:
- определите границы данных – лучшим кандидатом для микросервиса, управляемого событиями будет тот, который может иметь инкрементную разблокировку, будет актуальным для бизнеса и стейкхолдеров. Например, аутентификация при введении единого входа, если такого не было раньше или микросервис для выставления счетов.
- осторожный рефакторинг исходного приложения, чтобы абстрагировать «сервис» в свой собственный класс/API, который вызывает остальная часть кода. Оттуда можно реорганизовать внутренности этого сервиса, не касаясь остальной части монолита.
- использовать Kafka в качестве шины событий для асинхронного межсервисного взаимодействия. Apache Kafka предоставляет средства для асинхронного взаимодействия служб друг с другом через топики. Этот архитектурный стиль очень хорошо сочетается с потребностями связи микросервисов, когда один сервис может транслировать данные для использования любым количеством потребителей. Это уменьшает количество двухточечных подключений, включая технический долг и накладные расходы на управление.
- обязательно сохранить данные! Можно направить всю коммуникацию между сервисами в Confluent, чтобы аналитики имели доступ к данным о внутренней работе платформы и историческим данным, а дата-инженеры могли легко выявлять ошибки в конвейере обработки и исправлять их через простое воспроизведение сообщений потребителям. Можно также хранить данные в корпоративном озере (Data Lake), но обычно это требует дополнительных шагов для доступа и форматирования данных в пригодный для использования формат.
Больше практических подробностей про архитектуры распределенных систем, а также администрирование и использование Apache Kafka для потоковой аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
Источники

