
Сегодня разберем еще одну интересную тему из нашего нового курса «Greenplum для инженеров данных» по построению конвейеров приема данных для этой MPP-СУБД в рамках веб-интерфейса платформы автоматизированного управления потоками работ Apache NiFi. Читайте далее, как устроен коннектор VMware Tanzu Greenplum для Apache NiFi и какие возможности он предоставляет дата-инженеру.
Что такое коннектор VMware Tanzu Greenplum для Apache NiFi
Прежде всего поясним, что из-за покупки корпорацией VMware в 2020 году компании Pivotal, которая была вендором Greenplum (GP) с 2012 года, теперь эта open-source MPP-СУБД коммерциализируется под торговой маркой VMware Tanzu Greenplum [1].
Коннектор VMware Tanzu Greenplum для Apache NiFi позволяет дата-инженеру быстро и просто создавать конвейеры приема данных для MPP-СУБД в рамках удобного веб-интерфейса НайФай без разработки кода. В частности, можно использовать встроенные процессоры НайФай для настройки конвейера данных с процессором PutGreenplumRecord Connector, который загружает ориентированные на запись данные в GP для последующей аналитики. Ключевыми возможностями, которые предоставляет коннектор VMware Tanzu Greenplum для Apache NiFi, являются следующие [2]:
- drag-and-drop механизм веб-GUI NiFi для настройки компонентов и создания конвейера данных;
- поддержка форматов входных данных CSV, Avro, Parquet, JSON и XML с помощью встроенных считывателей записей NiFi (Record Readers);
- преобразование записей NiFi в кортежи Greenplum;
- загрузка кортежей в базу данных Greenplum;
Коннектор для НайФай использует сервер потоковой передачи GP (Streaming Server) для параллельной загрузки данных в базу. Это обеспечивает повышенный параллелизм и высокую пропускную способность во время приема данных по сравнению с процессором NiFi на основе JDBC, а также снижает нагрузку на мастер-хост кластера Greenplum.
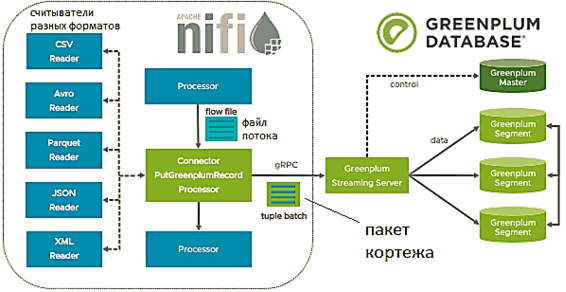
Разумеется, одного готового коннектора недостаточно, чтобы организовать прием данных из НайФай в GP: необходимо выполнить ряд шагов по настройке процессоров и контроллеров. Как это сделать, мы рассмотрим далее.
Эксплуатация Apache NIFI
Код курса
NIFI3
Ближайшая дата курса
13 мая, 2024
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Как передать данные: строим конвейер потоковой передачи
Перед началом построения такого конвейера следует убедиться, что у вас есть доступ к работающему кластеру GP и работающему экземпляру Greenplum Streaming Server или привилегии, необходимые для его запуска. Для упрощения предположим, что все компоненты Big Data конвейера (Apache NiFi, СУБД и сервер потоковой передачи GP работают на одном хосте). Сам процесс построения потокового конвейера передачи данных из НайФай в Greenplum будет состоять из следующих шагов [3]:
- подготовка среды: вход в клиент NiFi, создание рабочей директории, к которой есть доступ и запуск пользовательского интерфейса;
- добавление и настройка процессора GetFile с указанием входной директории;
- настройка службы контроллера GreenplumGPSSAdapter с заданием свойств Greenplum Streaming Server, портов, хостов и пользователей этой MPP-СУБД;
- определение источника, формата и схемы входных данных в свойствах процессора GetFile;
- настройка службы контроллера устройства чтения записей, чтобы указать схему данных и специфицировать первую строку файла в качестве заголовка;
- добавление и настройка процессора PutGreenplumRecord, чтобы определить наименование схемы данных, таблицу, тип операции, действия с совпадающими и несовпадающими колонками, количество записей в пакете и поведение в случае ошибки передачи данных из NiFi в Greenplum;
- подключение и запуск процессовров GetFile и PutGreenplumRecord с ранее определенными конфигурациями;
- создание базы данных и таблицы GP, куда необходимо записать данных из потокового файла (FlowFile) Apache NiFi, если это не было сделано ранее;
- запуск разработанного конвейера и проверка результатов.
Непосредственный пример потоковой передачи данных в CSV-формате из Apache NiFi в GP подробно представлен в официальной документации VMware Tanzu Greenplum [3]. Примеры других интеграций этой MPP-СУБД с фреймворками потоковых вычислений мы разбирали в статьях про коннекторы к Apache Kafka и Spark здесь и здесь. А пример обогащения потока данных информацией о характеристиках пользовательского устройства смотрите в нашей новой статье.
Greenplum для инженеров данных и аналитиков данных
Код курса
GPDE
Ближайшая дата курса
24 июня, 2024
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Узнайте больше совместное использование Greenplum и Apache NiFi для эффективного хранения и быстрой аналитики больших данных на авторских курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://en.wikipedia.org/wiki/Greenplum
- https://gpdb.docs.pivotal.io/connectors/apache-nifi/1-0/overview.html
- https://gpdb.docs.pivotal.io/connectors/apache-nifi/1-0/csv_example.html

