Сегодня рассмотрим важную практическую задачу из курсов Kafka для разработчиков и администраторов кластера – разделение топиков по брокерам. Читайте далее, как пропускная способность всей Big Data системы зависит от числа разделов, коэффициента репликации и ответного ack-параметра, а также при чем здесь KIP-500, позволяющий отказаться от Zookeeper.
Что такое партиционирование в Kafka или зачем делить топик на разделы
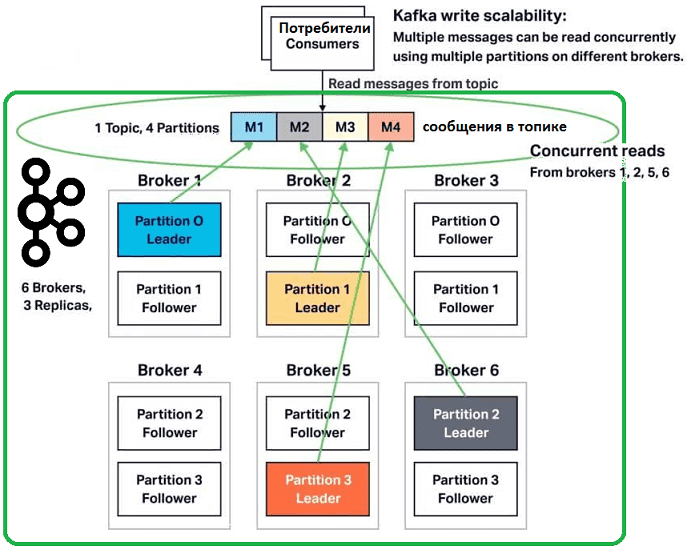
Напомним, разбиение топика по разделам – это основной механизм параллелизма в Apache Kafka, позволяя линейно масштабировать нагрузки потребителей. Ключевыми идеями этой концепции являются следующие [1]:
- каждый топик может иметь 1 или больше разделов, распараллеленных на разные узлы кластера (брокеры), чтобы сразу несколько потребителей могли считывать данные из одного топика одновременно;
- если число потребителей меньше числа разделов, один consumer получает сообщения из нескольких разделов;
- если потребителей больше, чем разделов, некоторые consumer’ы не получат никаких сообщений, пока общее количество потребителей не снизится до количества разделов;
- теоретически максимальное число разделов может быть любым, но на практике их размер ограничен размером сохраняемых сообщений, которые могут поместиться на одном узле.
- если в топике данных больше, чем может вместить 1 брокер, следует увеличить количество разделов;
- чтобы повысить надежность и доступность данных в кластере-Kafka, разделы могут иметь копии, число которых задается коэффициентом репликации (replication factor), который показывает, на сколько брокеров-последователей (follower) будут скопированы данные с ведущего-лидера (leader);
- число разделов и коэффициент репликации можно настроить для всего кластера или для каждого топика отдельно.
Таким образом, количество разделов и коэффициент репликации – это 2 самых важных параметра при создании топика. Значение этих настроек влияют на производительность и долговечность всей Big Data системы в целом. Примечательно, что рекомендуется определять эти значения сразу, т.к. их изменение на «живом» топике может привести к неожиданному снижению производительности или целостности данных [2]. Впрочем, новый релиз Apache Kafka без Zookeeper с реализацией долгожданного KIP-500 вносит свои коррективы в ограничение числа разделов, позволяя масштабировать их практически до бесконечности. Как это работает, мы рассмотрим завтра, а пока глубже погрузимся в устройство Kafka-топика, чтобы понять влияние числа разделов и особенностей их распределения по брокерам на общую производительность системы.
Администрирование кластера Kafka
Код курса
KAFKA
Ближайшая дата курса
29 мая, 2024
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Как пакеты сообщений записываются в разделы
При отправке сообщения в топик producer решает, в какой именно раздел записать сообщение. Если в один и тот же раздел одновременно отправлено несколько записей, они объединяются в пакет (batch). Время обработки каждого пакета зависит от входящих в него записей. Небольшой размер пакета (batch.size) более эффективен с точки зрения накладных расходов на запись, но их много мелких пакетов приводит к большему количеству запросов и очередей, увеличивая общую задержку. Пакет считается завершенным либо по достижении определенного размера, либо по истечении определенного периода времени (linger.ms). Оба параметра (batch.size и linger.ms) настраиваются в конфигурации продюсера. По умолчанию batch.size равен 16 384 байта, а linger.ms — 0 миллисекунд.
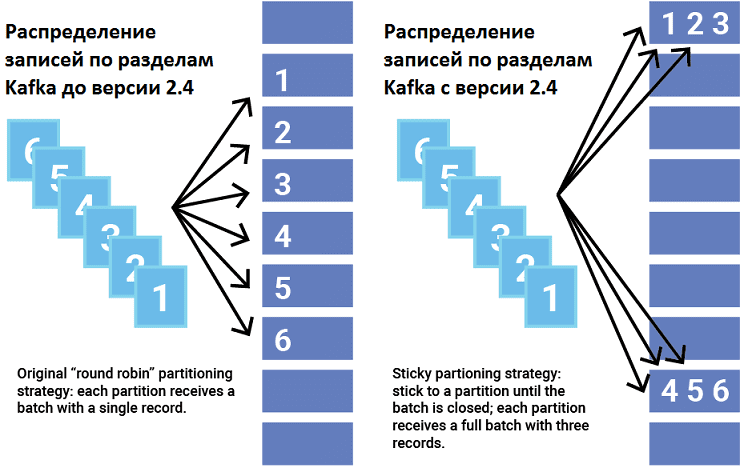
Даже если linger.ms равен 0, производитель группирует записи в пакеты, которые создаются в одном разделе примерно в одно и то же время, т.к. системе требуется время для обработки каждого запроса. Если записи отправляются в разные разделы, они не могут образовать пакет. Kafka позволяет пользователям выбирать стратегию разделения, настраивая класс разделителя (Partitioner). Разделитель назначает раздел для каждой записи: по умолчанию через хеширование ключа записи. Также некоторые записи могут иметь нулевой ключ. До версии Apache Kafka 2.4 стратегия разделения заключалась в циклическом просмотре разделов топика и отправке записи каждому из них. Этот метод не очень хорошо работает в пакетном режиме и фактически может увеличить задержку при работе с небольшими пакетами.
С версии 2.4. в Apache Kafka была введена новая стратегия назначения записей по разделам — липкое разделение (Sticky partitioning). Это решает проблему распределения записей без ключей на более мелкие пакеты, выбирая один раздел для отправки всех неключевых записей. Как только пакет в этом разделе заполнен или иным образом завершен, разделитель прикрепляется к новому разделу, выбирая его случайным образом. Таким образом, записи равномерно распределяются по всем разделам, получая дополнительное преимущество в виде пакетов большего размера.
Использование липкого разделителя с linger.ms> 0 в сценарии с относительно низкой пропускной способностью может значительно сократить временные задержки, особенно при создании сообщений без ключа. Кроме того, эта стратегия снижает загрузку ЦП, увеличивая количество записей в каждом пакете, чтобы уменьшить общее число пакетов и устранить лишнюю очередь. При меньшем количестве пакетов с большим количеством записей в каждом стоимость записи становится ниже, и их можно отправить быстрее. Положительный эффект становится более выраженным при увеличении количества разделов [3].
Как пропускная способность кластера зависит от числа разделов, коэффициента репликации и значения acks, а также при чем здесь отказ от Zookeeper в KIP-500
Однако, улучшенное формирование пакетов для распределения записей по брокерам Kafka не помогает автоматически определить оптимальное количество разделов. На практике слишком много разделов может вызвать длительные периоды недоступности при сбое брокера, т.к. выбор новых лидеров для всех разделов занимает много времени. Если разделы увеличиваются слишком быстро или их становится слишком много, кластер может быть перегружен [1].
Количество разделов, которые может поддерживать кластер Kafka, определяется двумя свойствами: пределом количества разделов на узел и пределом разделов в масштабе кластера. До реализации KIP-500 ограничивающим фактором было время для перемещения критически важных метаданных между внешним сервисом синхронизации Apache ZooKeeper и внутренним управлением лидером (контроллер Kafka). С новым контроллером кворума (Quorum Controller), представленным Confluent в марте 2021 года, это выполняется одним компонентом внутри Kafka, обеспечивая практически мгновенное переключение контроллера [4].
Также пропускную способность кластера Kafka можно улучшить, настроив параметр num.replica.fetchers. Эта конфигурация устанавливает количество потоков сборщика, доступных брокеру для репликации сообщения. По мере увеличения количества разделов может возникнуть конкуренция между потоками, поэтому увеличение их числа как минимум увеличит пропускную способность сборщика.
Кроме того, можно повысить производительность продюсера, поиграв с параметром acks (acknowledges) – количество подтверждений, которые лидер ожидает от follower’ов, чтобы считать сообщение успешно записанным. При этом стоит помнить, что производитель Kafka фактически является асинхронным. Поэтому влияние настройки acks не влияет напрямую на пропускную способность или задержку производителя, т.к. записи обрабатываются в его буфере с отдельными потоками. Напомним, параметр acks может принимать значения -1, 0 и 1. В чем разница между ними, мы подробно рассказывали здесь, когда разбирали строго однократную (exactly once) семантику гарантии доставки сообщений в Apache Kafka. Отметим, что конфигурации acks=all и idempotence=true обладают сопоставимой долговечностью, пропускной способностью и задержкой, однако idempotence=true гарантирует exactly once семантику для производителей. Подробнее о других настройках для увеличения скорости producer’а Kafka мы писали в этой статье.
Таким образом, пропускная способность Кафка-кластера зависит от разделов следующим образом [1]:
- оптимальное количество разделов на кластер примерно или чуть больше количества ядер ЦП, но не более 100;
- добавление новых брокеров (узлов в кластер) позволяет увеличить число разделов;
- при оптимальном количестве разделов увеличение значения num.replica.fetchers не оказывает существенного влияния на пропускную способность или задержку;
- коэффициент репликации и параметр acks влияют на сетевую загрузку и общую пропускную способность Big Data системы.
В реальности обычно брокер имеет не более 2000-4000 разделов по всем топикам, а во всем кластере Kafka рекомендуется не более 20 000 разделов для всех брокеров [2]. Хотя с отказом от Zookeeper это ограничение перестает быть актуальным, о чем мы поговорим завтра.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
27 мая, 2024
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Освойте практику разработки распределенных приложений потоковой аналитики больших данных и администрирования кластеров Apache Kafka на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://www.instaclustr.com/the-power-of-kafka-partitions-how-to-get-the-most-out-of-your-kafka-cluster/
- https://medium.com/swlh/choosing-right-partition-count-replication-factor-apache-kafka-cf50b1bc75cf
- https://www.confluent.io/blog/apache-kafka-producer-improvements-sticky-partitioner
- https://www.confluent.io/blog/kafka-without-zookeeper-a-sneak-peek/

