Сегодня разберем тему, важную для обучения дата-инженеров и разработчиков распределенных Spark-приложений. Почему чтение данных из реляционных баз в Apache Spark может быть медленным и как его ускорить, изменив SQL-запрос или структуру таблицы.
JDBC-источники данных для Apache Spark
Apache Spark является средством обработки, а не хранения больших данных. Поэтому, чтобы использовать вычислительные мощности этого распределенного движка, необходимо загрузить в память Spark-приложения данные из постоянных источников: реляционных баз или файловых хранилищ. Apache Spark предлагает встроенные возможности для чтения данных из реляционных баз данных через JDBC (Java DataBase Connectivity) — платформенно независимый промышленный стандарт взаимодействия Java-приложений с реляционными базами данных. Он реализован в виде пакета java.sql в составе Java SE и основан на концепции драйверов, позволяющих получать соединение с СУБД по специально описанному URL. Драйвер может загружаться динамически во время работы программы, затем самостоятельно регистрируется и вызывается автоматически, когда программа требует URL с протоколом, за который он отвечает. По сути, JDBC выполняет роль API-интерфейса Java, определяющего возможности доступа клиента к СУБД. В отличие от ODBC (Open Database Connectivity), JDBC подходит только для языка программирования Java, но зато может работать на любой операционной системе: Linux, Windows и пр. Подробнее про использование JDBC в Spark-приложениях мы писали здесь и здесь.
Spark SQL включает источник данных, который может считывать данные из других баз данных с помощью JDBC, что предпочтительнее использования JdbcRDD, т.к. результаты возвращаются в виде датафрейма. Это позволяет их обрабатывать в Spark SQL или объединять с другими источниками данных. Источник данных JDBC также легче использовать из Java или Python, поскольку он не требует от пользователя предоставления ClassTag, в отличие от сервера JDBC Spark SQL, который позволяет другим приложениям выполнять запросы с использованием Spark SQL.
Для свойств соединения пользователи могут указать свойства JDBC-соединения в параметрах источника данных. Учетные данные (имя пользователя и пароль) обычно предоставляются в качестве свойств подключения для входа в источники данных. JDBC-соединение в Apache Spark имеет более 20 параметров. Однако, настройки по умолчанию могут привести к длительным процессам или исключениям из-за нехватки памяти. Исправить эти проблемы и настроить производительность помогут следующие способы:
- ограничение данных с помощью подзапроса;
- партиционирование таблиц в источнике данных JDBC;
- оптимизация производительности кластера.
Далее рассмотрим каждый из этих способов более подробно.
Ограничение данных с помощью подзапроса
Самый простой, но очень эффективный способ повысить производительность чтения из JDBC-источников – это ограничить выборку данных. Вместо чтения всей таблицы следует указать в запросе только те столбцы и строки, которые нужны. Например, как это показано в следующем участке кода на PySpark:
query = """
SELECT category,
value
FROM testdata
WHERE category < 10
"""
df = spark.read.jdbc(
url="jdbc:postgresql://db/postgres",
table=f"({query}) t ",
properties=connection_properties
)
Поскольку в проектах аналитики больших данных в таблицах обычно хранится множество строк, рекомендуется добавлять в SQL-запрос выражение LIMIT, чтобы ограничить количество строк выборки. О том, как работает этот оператор в Apache Spark и когда вместо него лучше использовать TABLESAMPLE, мы писали здесь.
Партиционирование таблиц в источнике данных JDBC
По умолчанию Apache Spark будет хранить данные, считанные из JDBC-соединения, в одном разделе. Поэтому для процесса чтения будет использоваться только один исполнитель кластера. Чтобы увеличить количество узлов, читающих данные параллельно, их необходимо разделить, передав в запросе следующие параметры:
- partitioningColumn определяет, какой столбец таблицы будет использоваться для разделения данных на разделы. Тип данных этого столбца разделения должен быть NUMERIC, DATE или TIMESTAMP, поскольку SQL-запросы создаются на основе смещений от нижней границы и верхней границы перед чтением фактических данных.
- numPartitions устанавливает желаемое количество разделов;
- Нижняя (lowerBound) и верхняя (upperBound) границы используются для вычисления границ раздела.
При этом Apache Spark будет генерировать SQL-запрос для каждого раздела с отдельным фильтром в столбце разделения. На следующем рисунке показано, как данные делятся на четыре раздела с использованием вышеприведенных параметров.
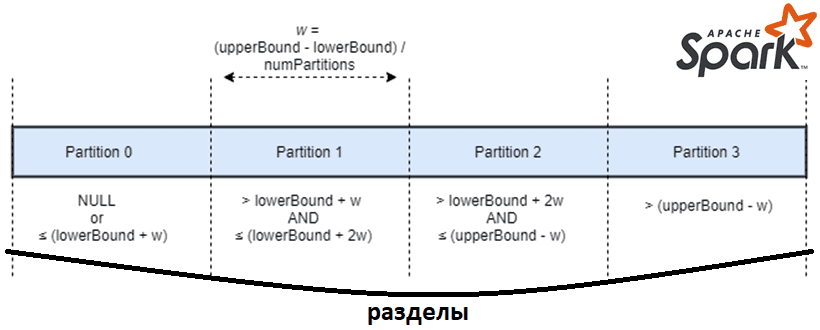
Важно отметить, что все данные будут считаны независимо от того, используется ли партиционирование или нет. Первый и последний разделы будут содержать все данные за пределами соответствующей верхней или нижней границы, если они не совпадают с фактическими границами данных. Чтобы снизить влияние на производительность, нижняя и верхняя границы должны быть близки к фактическим значениям, представленным в столбце разделения. Подробнее об этом читайте в нашей новой статье.
В следующем коде PySpark показано, как можно сначала определить минимальное и максимальное значения столбца, а затем использовать эти значения для разделения. В качестве источника данных используется объектно-реляционная база PostgreSQL:
query = """
SELECT category,
value
FROM testdata
WHERE category < 100
"""
query_min_max = f"""
SELECT Min(category),
Max(category)
FROM ({query}) s
"""
# Determine min and maximum values
df_min_max = spark.read.jdbc(
url="jdbc:postgresql://db/postgres",
table=f"({query_min_max}) t ",
properties=connection_properties,
).collect()
min, max = df_min_max[0][0], df_min_max[0][1]
# Partition the data
df = (
spark.read.option("numPartitions", 8)
.option("partitionColumn", "category")
.option("lowerBound", min)
.option("upperBound", max)
.jdbc(
url="jdbc:postgresql://db/postgres",
table=f"({query}) t ",
properties=connection_properties,
)
)
Партиционирование наиболее эффективно, когда оно выполняется для индексированного столбца, а строки таблицы равномерно распределены по разделам. Разделение увеличивает количество параллельных запросов, выполняемых к базе данных, что потенциально может быть равно количеству исполнителей в кластере Apache Spark, если это не ограничено его конфигурацией.
Если в исходной таблице нет столбца с подходящим типом данных, можно использовать общий номер строки или блока для разделения таблицы. Например, в PostgreSQL для этого подойдет столбец ctid:
SELECT (ctid::text::point)[0]::bigint AS block_number,
value
FROM testdata
WHERE category < 100
Для этого столбца можно применить хэш-функцию, чтобы преобразовать полученный хэш в числовое значение. PostgreSQL предлагает для этой цели функцию hashtext(), которая вычисляет хэш-значение для столбца с типом данных строка. Это можно использовать в сочетании с оператором деления по модулю для получения желаемого количества разделов. В этом случае предварительный расчет минимального и максимального значений не требуется. Следующий SQL-запрос показывает работу этого приема для 64 разделов:
SELECT abs(hashtext(category)) % 64 as part, value
FROM testdata
WHERE category < 100
Справедливости ради стоит отметить, что хэширование может существенно снизить производительность. Поэтому нужно искать компромисс между преимуществом чтения данных в распределенном режиме и стоимостью вычисления хэш-функции. Если проблемы с производительностью все же возникли, их стоит искать и исправлять.
Оптимизация производительности Apache Spark
Проблемы с производительностью можно выявить, проверив веб-интерфейс Apache Spark или метрики кластера. Пользовательский интерфейс фреймворка показывает количество задач, равное количеству разделов JDBC-подключения для первого этапа. Обычно оптимальное количество задач равно количеству ядер ЦП в кластере Apache Spark. Метрики кластера дадут представление о том, равномерно ли сбалансированы данные в кластере. Перекос или неравномерное распределение данных – одна из наиболее вероятных причин снижения производительности, что мы разбирали здесь.
В случае нехватки памяти на рабочих процессах, т.е. OOM-ошибки, даже при использовании партиционирования, рекомендуется увеличить количество разделов сверх числа доступных исполнителей. Это сократит размер раздела и требования к объему памяти. Впрочем, если данные в столбце партиционирования распределены неравномерно, этот прием не поможет. Чтобы решить эту проблему, необходимо использовать второй столбец для тех разделов, которые слишком велики. Рекомендуется использовать исходный столбец для разделения данных, исключая большие разделы с помощью предложения WHERE, а затем разделить по второму столбцу только исключенные данные во втором запросе. Таким образом, партиционирование может значительно ускорить процессы приема, сохраняя низкий уровень требуемой рабочей памяти и обеспечивая параллельное чтение.
Эти выводы подтверждают эксперименты из двух кластеров Databricks, записывающих 30 миллионов строк из базы PostgreSQL в дельта-таблицу. Первый кластер содержит только один узел и не использует партиционирование, а второй кластер разделяет данные на 32 раздела и использует автоматическое масштабирование от 4 до 8 узлов.
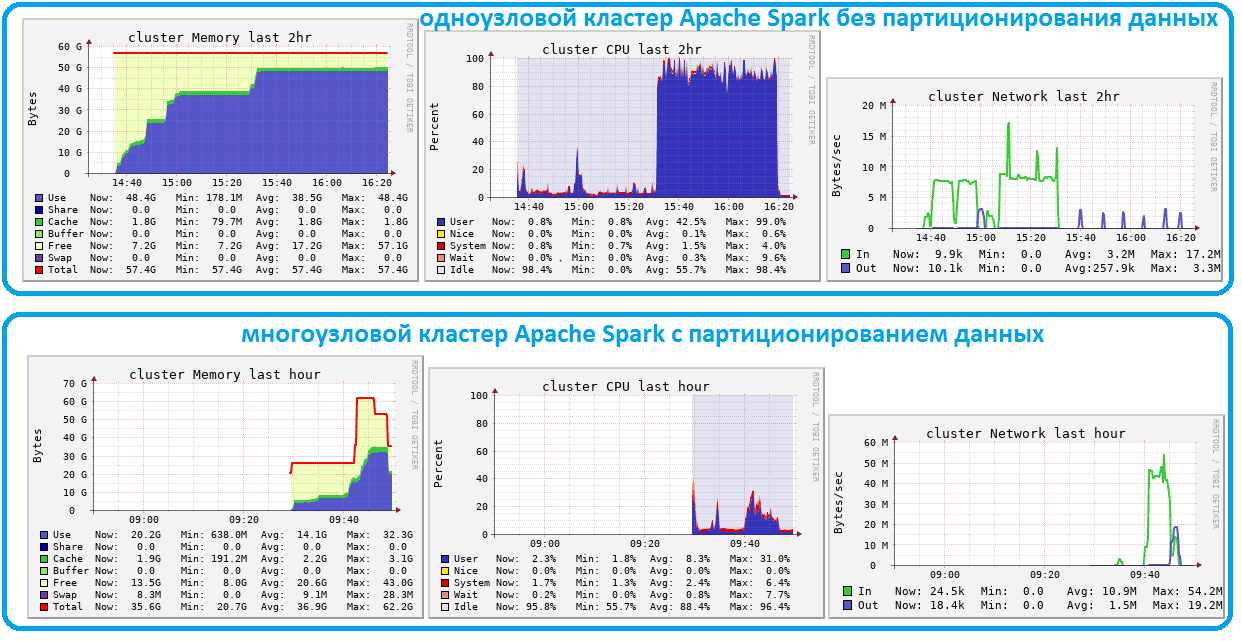
В кластере с одним узлом без партиционирования загрузка данных из JDBC-источника в Apache Spark заняла более часа, а в многоузловом кластере с партиционированием время выполнения удалось сократить до 10 минут. Разделенное задание использует меньше памяти на одного worker’а и обеспечивает более высокую пропускную способность сети. При чтении еще больших наборов данных отсутствие разделов исключает масштабирование и приводит к исключениям из-за нехватки памяти. Поэтому партиционирование таблиц – отличный вариант для очень больших наборов данных.
Освойте администрирование и использование Apache Spark для задач дата-инженерии, разработки распределенных приложений и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

