
В этой статье продолжим говорить про обучение разработчиков Apache Spark и рассмотрим, какие сегменты памяти есть в этом Big Data фреймворке и как с ними работать наиболее эффективно. Читайте далее, почему процессы PySpark и SparkR потребляют внешнюю память, чем пользовательская память кучи JVM отличается от памяти хранилища и какие конфигурации нужно настроить, чтобы ускорить распределенные вычисления и предотвратить возможные утечки.
В JVM и не только: виды памяти Apache Spark
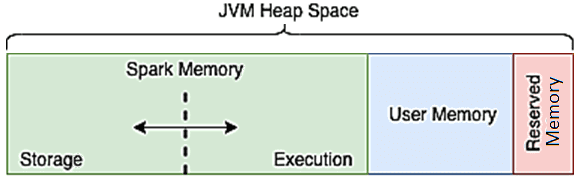
Напомним, при том, что Apache Spark поддерживает Java, R и Python, основным языком реализации самого фреймворка является Scala. Поэтому все операции выполняются внутри JVM, даже если пользовательский код написан на Python или R. Среда выполнения фреймворка разделяет пространство кучи (Heap) JVM в драйвере и исполнителях на 4 разные части [1]:
- память хранилища (Storage Memory), зарезервированная для кэшированных данных;
- память выполнения (Execution Memory), используемая структурами данных во время shuffle-операций, при которых данные перемешиваются – т.е. соединение, группировка и агрегирование;
- пользовательская память (User Memory) для хранения структур данных, созданных и управляемых пользовательским кодом;
- зарезервированная память (Reserved Memory) для внутренних целей фреймворка.
Кроме JVM Heap, есть еще два сегмента памяти, к которым обращается Spark:
- память вне кучи (Off-Heap Memory) – сегмент за пределами JVM, который иногда используется виртуальной машиной Java, например, для метода intern(), гарантирующего что все строки с одинаковым содержимым, совместно используют одну и ту же память. Память вне кучи также может использоваться для хранения сериализованных датафреймов и RDD. О том, как сохранить датафрейм в память исполнителя вне кучи, читайте в нашей отдельной статье.
- внешняя память процесса (External Process Memory), которую используют программы на PySpark и SparkR в рамках процессов Python и R вне JVM.
Какие параметры конфигурации стоит настроить, чтобы использовать каждый вид памяти наиболее эффективно, мы рассмотрим далее.
2 самых важных параметра для памяти хранилища
Раздел Memory Management в официальной документации Спарк включает целых 10 различных конфигураций для настройки управления памятью фреймворка. Из них к памяти хранилища относятся следующие [2]:
- memory.fraction – сегмент от 300 МБ JVM-кучи для выполнения и хранения данных. По умолчанию его значение равно 0,6 – чем оно меньше, тем чаще происходит утечка и вытеснение кэшированных данных. Эта конфигурация позволяет выделить память для внутренних метаданных и структур пользовательских данных, а также приблизительно оценить размер разреженных необычно больших записей.
- memory.storageFraction – часть области spark.memory.fraction, объем памяти хранения, невосприимчивый к вытеснению, по умолчанию равный 0,5. Чем больше это значение, тем меньше оперативной памяти доступно для выполнения, и задачи чаще сохраняются на диск.
Таким образом, оба параметра устанавливают объем пространства JVM, который будет использоваться в качестве памяти для хранения и кэширования данных). Но spark.memory.fraction определяет общий объем памяти, выделенной как для перемешивания, так и для хранения данных. А объем памяти, защищенной от вытеснения, определяется параметром spark.memory.storageFraction.
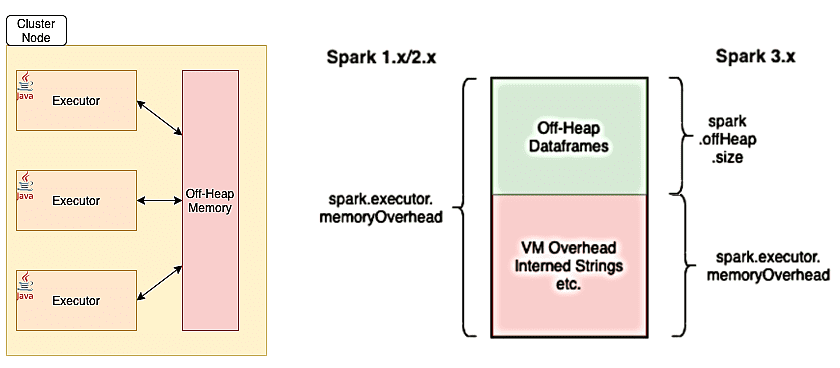
Исполнители и память вне кучи
При том, что большинство операций в Спарк происходит внутри JVM и использует ее кучу для своей памяти, каждый исполнитель может также иногда обращаться к внешнему пространству за пределами виртуальной машины Java через API-интерфейсы sun.misc.Unsafe. Эта память вне кучи находится за пределами области сборки мусора, поэтому предоставляет разработчику приложения более точный контроль над памятью. В частности, фреймворк использует эту память вне кучи для более эффективной работы с памятью за счет метода String.intern() и накладных расходов JVM. Также off-heap memory нужна фреймворку для хранения данных в рамках проекта Tungsten – компонента Spark SQL, который повышает эффективность операций обработки данных, работая непосредственно на уровне байтов.
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
13 мая, 2024
Продолжительность
16 ак.часов
Стоимость обучения
48 000 руб.
Общая память вне кучи для исполнителя Спарк контролируется конфигурацией spark.executor.memoryOverhead, по умолчанию равной 10% памяти исполнителя при минимальном размере 384 МБ. Даже если пользователь явно не задает этот параметр, фреймворк сам выделит 10% памяти исполнителя или 384 МБ, в зависимости от того, что больше для накладных расходов JVM [1]. Этот объем дополнительной памяти, выделяемой для каждого процесса-исполнителя, увеличивается по мере роста размера исполнителя. В настоящее время опция поддерживается в YARN и Kubernetes. Дополнительная память также включает память исполнителя PySpark (если spark.executor.pyspark.memory не настроен специально) и память, используемую другими процессами, не являющимися исполнителями, в том же контейнере [2]. Примерный расчет оптимального количества ресурсов на исполнителя смотрите в нашей новой статье.
Объем памяти вне кучи, используемый фреймворком для хранения фактических датафреймов, определяется параметром spark.memory.offHeap.size. Это дополнительная функция, которую можно включить, установив для spark.memory.offHeap.use значение true. Примечательно, что в предыдущих релизах фреймворка (до версии 3.x) общая память вне кучи, указанная с помощью memoryOverhead, также включала память вне кучи для датафреймов. Версия 3.0 отделяет off-heap от memoryOverhead, поэтому теперь разработчику не нужно волноваться о размерах датфреймов во время установки memoryOverhead исполнителя [1].
Максимальный объем памяти контейнера для запущенного исполнителя равен сумме значений spark.executor.memoryOverhead, spark.executor.memory, spark.memory.offHeap.size и spark.executor.pyspark.memory [2].
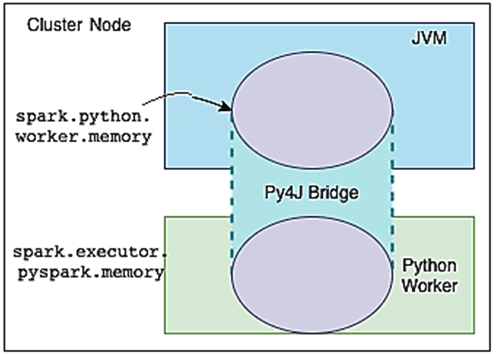
Что разработчик Spark-приложений должен знать о памяти Python: особенности PySpark
При выполнении пользовательского кода на PySpark используются участки памяти, заданные в конфигурациях spark.python.worker.memory и spark.executor.pyspark.memory. При работе с Python-кодом в PySpark исполнитель выполняет два отдельных процесса, которые взаимодействуют друг с другом через мост Py4J:
- JVM выполняет часть кода Спарк, связанный с операциями перемешивания, такими как соединение и агрегирование;
- python, который непосредственно выполняет код пользователя.
Параметр spark.python.worker.memory управляет объемом памяти, зарезервированной для каждого процесса worker’а PySpark, за пределами которого он переносится на диск, т.е. этот объем памяти может быть занят объектами, созданными через мост Py4J во время Спарк-операций. Если этот параметр не установлен, его значение по умолчанию равно 512 МБ.
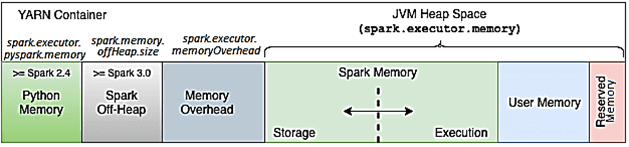
Начиная с версии 2.4, параметр spark.executor.pyspark.memory контролирует фактическую память процесса worker’а Python, устанавливая предел пространства памяти, который он может адресовать, с помощью свойства system.RLIMIT_AS. Если память worker’а Python не установлена через параметр spark.executor.pyspark.memory, этот процесс потенциально может занять всю память узла. А, поскольку эта часть памяти не отслеживается диспетчером ресурсов Спарк-кластера, таким как Hadoop YARN, есть риск перепланирования в узле и смены страниц в памяти. В результате возможно замедление работы всех контейнеров YARN на этом узле. Поэтому следует настраивать оба параметра [1]:
- python.worker.memory, который ограничивает память в JVM для объектов Python;
- executor.pyspark.memory, который ограничивает фактическую память процесса Python.
В заключение отметим, что общая память, запрошенная фреймворком у диспетчера контейнеров, в частности, Hadoop YARN, равна сумме памяти исполнителя, накладных расходов памяти и лимита памяти worker’а, на котором выполняется программа Python [1].
Освойте все тонкости разработки распределенных приложений Apache Spark для аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:

