
Сегодня разберем пример европейской логистической компании Sixfold, которая смогла увеличить пропускную способность своей системы мониторинга транспортных отгрузок на базе Apache Kafka и Kubernetes. Также рассмотрим, как дата-инженеры Sixfold справились с проблемами изоляции при последовательной обработке сообщений и транзакционной записи в топики Kafka с базами данных отдельных микросервисов на подах Kubernetes.
Apache Kafka как основа микросервисной архитектуры логистической компании Sixfold
ИТ-сервисы Sixfold получают много данных из разных источников, самые крупные категории которых относятся к транспорту и телеметрии. Данные о транспортировке дают представление о запланированном маршруте: где и когда забрать или доставить товар. А данные телеметрии от устройств GPS на транспортных средствах позволяет в режиме реального времени оценивать время получения и доставки. Объединив эти два потока данных, можно в реальном времени выяснить, что происходит с транспортировкой товара. По мере роста клиентской базы возникла задача масштабирования продукта сразу по двум осям: количество маршрутов и количество транспортных средств.
Логистическая система Sixfold построена на Apache Kafka по микросервисной модели, когда различные микросервисы взаимодействуют друг с другом посредством передачи сообщений. В качестве платформы управления контейнерными приложениями используется Kubernetes. При множестве достоинств каждой технологии в отдельности, совмещение Kafka с Kubernetes не самая простая задача с технической точки зрения, о чем писали здесь и здесь. В эксплуатации также возникают проблемы, например, когда во время развертывания новой версии микросервиса старые поды Kubernetes завершаются, а новые порождаются. Возникает некоторое наложение, что при работе с Kafka приводит к перебалансировке потребителей и вызывает дополнительную нагрузку на отдельные поды. В результате скорость обработки сообщений снижается, и пропускная способность всей системы падает.
Исправить эту проблему помогло профилирование сервисов с большим объемом данных. Мониторинг за работой Node.js-приложений с помощью протокола V8 Inspector, встроенного в Chrome DevTools показал, что причиной повышенного потребления ресурсов ЦП в служебных модулях, а не в самой базе данных, были неоптимальные регулярные выражения. TypeORM, пакет OSS для абстракции базы данных, имел некоторые проблемы с производительностью, которые удалось исправить. Также были улучшены регулярные выражения в коде микросервисов, которые выполняли много запросов к СУБД. Вместе с оптимизацией планов SQL-запросов с помощью индексов и их группировки с помощью загрузчиков данных, специалисты Sixfold смогли намного повысить пропускную способность своей логистической системы.
Также был улучшен API GraphQL, отключены ненужные плагины apollo-сервера и изменена схема данных. Парсинг абстрактного синтаксического дерева входящего запроса GraphQL позволил заранее знать типы данных, которые нужно извлечь, и подготовить базовые загрузчики, уже инициируя асинхронные запросы к БД. В результате большинство последовательных запросов к базе данных стали параллельными, что сэкономило много времени на запросах API.
Однако, эти действия не решили все проблемы микросервисной системы на базе Kafka, о чем мы поговорим далее.
Изоляция и состояния транзакций
Итак, в основе ИТ-системы Sixfold лежит Kafka как средство взаимодействия сервисов друг с другом. У каждого сервиса есть собственная база данных PostgreSQL. На абстрактном уровне работу каждого сервиса можно представить следующим образом:
- прочитать сообщение из Kafka;
- выполнить обработку данных согласно правилам бизнес-логики, возможно, включая REST-запросы к внешним сторонам;
- сохранить/обновить состояние в локальной базе данных;
- записать новое сообщение в Kafka.
Таким образом, можно представить всю архитектуру системы как сеть топиков Kafka с узлами в качестве сервисов, которые выполняют необходимую бизнес-логику. Эта архитектура имеет следующие недостатки:
- проблема изоляции — последовательная обработка сообщений. Топик Kafka реализует абстракцию лога с последовательным смещением. В рамках одного лога можно двигаться только линейно: потребители должны подтвердить обработку сообщения, переместив указатель смещения вперед. Но при некорректном сообщении его обработка занимает много времени или полностью останавливает поток. В результате REST-запрос к внешней стороне завершится ошибкой и затормозит всю систему.
- проблема состояний связана с записью данных в СУБД микросервиса. Записывая задания в сервисную СУБД, можно обновлять состояние в рамках той же транзакции, что и вставка нового задания. Объединение с заданием, которое создает фактическое сообщение Kafka, позволяет сделать всю операцию транзакционной. Если одна из частей выйдет из строя: обновление данных или планирование задания, обе операции будут отменены, и данные останутся согласованными. Даже если во время выполнения задание завершится ошибкой, обновления не теряются. Пока проблема сохраняется, дальнейшие сообщения об изменении состояния будут помещаться в очередь как задания. После решения проблемы, обновления будут выходить в логическом порядке для остальной системы, и в конечном итоге все будут синхронизированы.
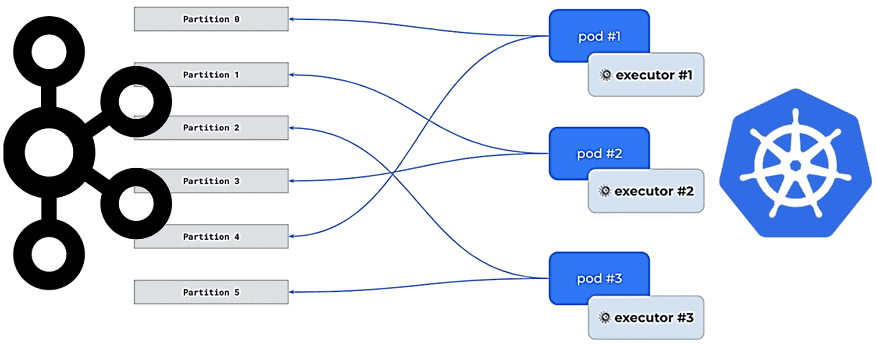
О проблеме изоляции или последовательной обработки сообщений стоит сказать подробнее. У Kafka есть разделы, которые следует рассматривать как единицу параллелизма. Один топик Kafka состоит из нескольких разделов, каждый из которых представляет собой отдельный журнал сообщений. Много разделов позволяет избежать поной остановки системы: только один раздел тормозит из-за некорректного сообщения, поскольку смещения отслеживаются для каждого раздела автономно. Но кластер Kafka может обрабатывать только определенное количество разделов и бесконтрольно увеличивать это число не рекомендуется.
Целевой раздел для любого данного сообщения выбирается некоторым алгоритмом, по умолчанию это хэш предоставленной ключевой строки по модулю от общего количества разделов. При использовании этой стратегии хеширования сообщение, которое раньше находилось в разделе 3, могло переместиться в раздел 7 после добавления 10 разделов. Теперь данные для одного и того же сообщения теперь находятся в двух разных разделах, что нарушает логический порядок их повторной обработки. Администраторы Kafka-кластера в Sixfold выбрали 100 в качестве количества разделов, чтобы отложить необходимость добавления разделов и перемешать исторические данные. Однако, стали намного сложнее обращения к внешним системам при обработке сообщений и последовательной фиксации смещений.
Проблема сводится к отсутствию общей транзакционной границы между обновлением базы данных отдельного микросервиса и созданием сообщения Kafka с обновлением состояния. Даже при неуспешном обновлении в базе данных микросервиса, сообщение Kafka может быть создано или наоборот. Таким образом, необходимо выполнять оба действия транзакционно. Для этого разработчики Sixfold реализовали собственное решение как задание запланированного асинхронного действия, поддерживаемого БД, с настраиваемыми политиками очередей. Это задание имеет 3 ключевых свойства:
- type — определяет, какую функцию выполнять;
- origin – источник для связывания задания с конкретным экземпляром микросервиса, т.е. пода Kubernetes, который отвечает за его выполнение;
- group — строка, которую можно использовать для группировки нескольких заданий в один поток. Например, transport_id, когда все задания для определенного транспорта будут формировать единую группу для последовательного выполнения.
Запустив 3 экземпляра каждого сервиса из соображений избыточности, инженеры Sixfold настроили автоматическое горизонтальное масштабирование подов Kubernetes: если сервис начинает испытывать трудности под нагрузкой, Kubernetes автоматически добавляет новый экземпляр. А за безопасное и эффективное распределение заданий между экземплярами-исполнителями отвечает группы потребителей Kafka. Протокол их ребалансировки обеспечивает разделение всех разделов топика между всеми работающими членами группы потребителей. Например, если есть 3 экземпляра приложения и 100 разделов, то каждый экземпляр занимает примерно 33 раздела. У каждого экземпляра сервиса есть 1 исполнитель заданий, который знает о назначенных в данный момент разделах.
Дополнительным преимуществом этого решения является отсутствие отдельных процессов или «кластера исполнителей» для управления. Поскольку задание поступает через сообщения Kafka в определенные разделы, ее обрабатывает один и тот же процесс. Когда нагрузка слишком велика, добавление экземпляров автоматически распределяет нагрузку, поскольку у каждого экземпляра меньше разделов для обработки.
Поскольку все задания находятся в одной группе потребителей, даже в случае сбоя REST-запроса к внешней системе, это не повлияет на другие задания, которые выполняются независимо на основе значения группы. По сути, этот подход позволяет уменьшить влияние некорректного сообщения, имитируя дополнительные виртуальные разделы внутри одного раздела Kafka.
Узнайте больше про администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
Источники

